限流熔断Sentinel的应用场景、基本概念与使用
Nacos就是我们程序安全的一个开关,在这里只是初步的接触了解,项目中如果要是与网关以及集群的限流结合一定是一件非常有意思的事情。有关Sentinel的源码部分流程图参考:
Sentinel源码 | ProcessOn免费在线作图,在线流程图,在线思维导图 |
希望后面自己也能去看源码好好理解一下,学习学习里面的相关理念,包括对高并发场景的处理
一、相关概念
1、服务雪崩
在我们的微服务架构中一个请求常常是有多个服务提供能力的这时候就会形成一个复杂的调用链路,在这个调用的链路中肯定有的位于上游有的位于下游,如果位于下游的一个服务或是其他位置的服务发生了异常失去服务提供能力,这时候就也会引起上游的服务拿不到相应结果,最终导致上游的服务也不可用,最终而导致全局服务失效,这就是自己理解的服务雪崩。
2、服务限流
当服务发生异常并且不可以使用的时候,当达到我们自己定义的这个异常的标准时候就限制一部分的请求,让他们直接返回结果或是报错,从而不至于服务全部失效。这里理解为服务限流可以保证服务有一个可提供服务的底线。
限流的主要目的是通过限制并发访问数或者限制一个时间窗口内 允许处理的请求数量来保护系统,一旦达到限制流量,则对当前 请求进行处理采取对应的拒绝策略。如:跳转错误页面、进行排 队、服务降级等。
3、服务降级
当某个服务提供者无法正常为服务调用者提供服务时,为了防止 服务雪崩,暂时将出现故障的接口隔离出来,后续一段时间内该 服务调用者的请求都会直接失败,直到目标服务恢复正常。
二、常用的四种限流算法
1、计数器算法
这是最基础的解决办法,也是最原始的解决办法。在用这个算法的时候会发生临界的情况就是在时间分段上,前时间段的请求都集中了在后半部分,后一段的时间都集中在了前一部分,前一段的后半段与后一段的前半段这一段的事件内限流也就是失效的。
2、滑动窗口算法
是为了解决计数器算法中出现的临界区间内的集中访问,他的做饭可以简单的理解为将时间段划分的更小,同时将时间篇做成桶的结构来统计每个桶中的QPS以及若干个连续桶QPS的总数。
参考的代码来源于:
简单的java实现滑动时间窗口限流算法 - dijia478 - 博客园 (cnblogs.com)
public class SlideWindowSelf {
//队列id与队列的映射关系
private volatile static Map<String, List<Long>> MAP = new ConcurrentHashMap<>();
//保证了程序不被实例话,智能通过今天方法来进行调用
private SlideWindowSelf(){ }
public static void main(String[] args) throws InterruptedException {
while (true){
System.out.println(LocalTime.now().toString()+SlideWindowSelf.isGo("ListId",2,10000L));
//睡眠0——10秒
Thread.sleep(1000*new Random().nextInt(10));
}
}
//这里面有关listId、count、timeWindow相关的信息如果结合配置文件以及外部存储就可以实现Sentinel
//中相关限流的基本功能;这个程序的结构总体来说简单清晰,通过运用集合相关的知识来解决,是值得学习
//随着后面对集合的越发熟悉应该可以对这个结构进行优化
//这个结构目前缺乏对链路信息分析的能力,如果要实现这部分的能力需要再添加相应的代码
public static synchronized boolean isGo(String listId,int count,long timeWindow){
//获取当前时间
long nowTime = System.currentTimeMillis();
//根据队列id取出对应的限流队列,感觉这里有点像Sentinel中资源的概念
List<Long> list = MAP.computeIfAbsent(listId,k->new LinkedList<>());
//如果队列还还有满则允许通过并且添加时间戳到队列中
if (list.size()<count){
list.add(0,nowTime);
return true;
}
//队列已满,则获取队列中添加最早的时间戳
Long farTime = list.get(count-1);
//用当前时间戳减去最早添加的时间戳
if(nowTime-farTime<=timeWindow)return false;
//允许通过并删除最早添加的时间戳将当前的时间添加到队列开始的位置
list.remove(count-1);
list.add(0,nowTime);
return true;
}
}
3、令牌桶限流
以稳定的速度往桶中丢令牌,使用的时候就从桶中拿数据,单桶中的令牌数被拿完的时候就进行限流措施。如果要是桶中令牌的拿出速率慢与放入速率造成桶满,这时候桶中的令牌就会溢出。
4、漏桶限流算法
令牌桶可以用来保护自己,主要用来对调用者频率进行限流,为的是让自己不被打垮。所以如果自己本身有处理能力的时候,如果流量突发(实际消费能力强于配置的流量限制),那么实际处理速率可以超过配置的限制。而漏桶算法,这是用来保护他人,也就是保护他所调用的系统。主要场景是,当调用的第三方系统本身没有保护机制,或者有流量限制的时候,我们的调用速度不能超过他的限制,由于我们不能更改第三方系统,所以只有在主调方控制。这个时候,即使流量突发,也必须舍弃。因为消费能力是第三方决定的。**如果要让自己的系统不被打垮,用令牌桶。如果保证别人的系统不被打垮,用漏桶算法。**MQ用的就是漏桶算法。
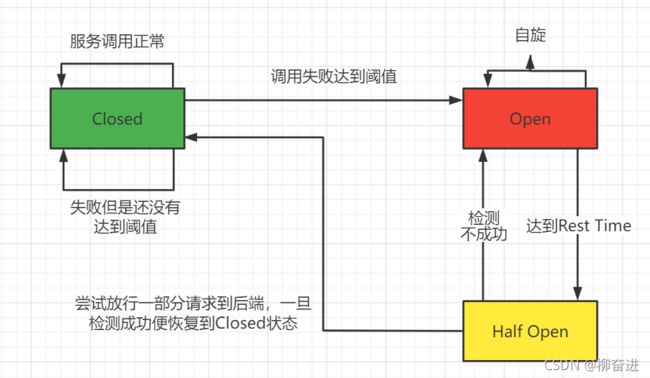
三、Sentinel简介
问题思考
面向分布式服务架构的轻量级流量控制组件,他一流量为切入点从限流、流量整型、服务降级、系统负载保护多个维度来保障服务的稳定性
要理解其中的直接失败带来的优势与好处
服务降级的使用应该是要与配置中心结合使用的,这时候应该如何做配置
1、Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器。
2、Sentinel的插槽是什么
NodeSelectorSlot负责收集资源的路径,并将这些资源的调用路径,以树状结构存储起来,用于根据调用路径来限流降级;ClusterBuilderSlot则用于存储资源的统计信息以及调用者信息,例如该资源的 RT, QPS, thread count 等等,这些信息将用作为多维度限流,降级的依据;StatisticSlot则用于记录、统计不同纬度的 runtime 指标监控信息;FlowSlot则用于根据预设的限流规则以及前面 slot 统计的状态,来进行流量控制;AuthoritySlot则根据配置的黑白名单和调用来源信息,来做黑白名单控制;DegradeSlot则通过统计信息以及预设的规则,来做熔断降级;SystemSlot则通过系统的状态,例如 load1 等,来控制总的入口流量;
上面的Slot都会包含在一个SlotChain中,每一个资源都对应着一个SlotChain,这一个个的流程走下来就完成我们的一个限流目的。在知乎的一篇文章中对着其中涉及到的并发相关内容做了很好地介绍:
阿里Sentinel原理解析 - 知乎 (zhihu.com)
不过对于他们这里个链路实现的方式不太清楚,里面采用的是否是模板模式,这一部分的代码后面应该补一下,形成一片专门的博客:
3、限流规则的组成因素
resource:资源名,即限流规则的作用对象
count: 限流阈值
grade: 限流阈值类型(QPS 或并发线程数)
limitApp: 流控针对的调用来源,若为default则不区分调用来源
strategy: 调用关系限流策略
controlBehavior: 流量控制效果(直接拒绝、Warm Up、匀速排队)
4、基于QPS/并发数的流量控制
流量控制主要有两种统计类型,一种是统计并发线程数,另外一种则是统计 QPS。类型由 FlowRule 的 grade 字段来定义。其中,0 代表根据并发数量来限流,1 代表根据 QPS 来进行流量控制。其中线程数、QPS 值,都是由 StatisticSlot 实时统计获取的。
-
并发线程数控制
是直接控制调用端不能够发送请求吗,应该是这个意思和目的
并发数控制用于保护业务线程池不被慢调用耗尽。例如,当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽。为应对太多线程占用的情况,业内有使用隔离的方案,比如通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)。这种隔离方案虽然隔离性比较好,但是代价就是线程数目太多,线程上下文切换的 overhead 比较大,特别是对低延时的调用有比较大的影响。Sentinel 并发控制不负责创建和管理线程池,而是简单统计当前请求上下文的线程数目(正在执行的调用数目),如果超出阈值,新的请求会被立即拒绝,效果类似于信号量隔离。并发数控制通常在调用端进行配置
-
QPS 流量控制
直接拒绝:是默认的流量控制方式,当QPS超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出
FlowException。这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时。Warm Up:即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。
匀速排队:会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。暂时不支持 QPS > 1000 的场景。
5、基于调用关系的流量控制
**调用关系包括调用方、被调用方;一个方法又可能会调用其它方法,形成一个调用链路的层次关系。**Sentinel 通过 NodeSelectorSlot 建立不同资源间的调用的关系,并且通过 ClusterBuilderSlot 记录每个资源的实时统计信息。有了调用链路的统计信息,我们可以衍生出多种流量控制手段。
-
根据调用方进行限流
流控规则中的
limitApp字段用于根据调用来源进行流量控制。该字段的值有以下三种选项,分别对应不同的场景:default:表示不区分调用者
{some_origin_name}:表示针对特定的调用者
other:表示针对除{some_origin_name}以外的其余调用方的流量进行流量控制 -
根据调用立案率入口进行限流

-
具有关系的资源流量控制:关联流量控制
这里面的一个控制思路就是通经过方向控制,A高了就对B进行控制
当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联。比如对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度。如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量。可使用关联限流来避免具有关联关系的资源之间过度的争抢,举例来说,
read_db和write_db这两个资源分别代表数据库读写,我们可以给read_db设置限流规则来达到写优先的目的:设置strategy为RuleConstant.STRATEGY_RELATE同时设置refResource为write_db。这样当写库操作过于频繁时,读数据的请求会被限流。
6、集群流控
-
为什么要使用集群流控?
如果用单级来控制同个服务多态机器的话可能会造成流量分布不均匀的情况,这时候采用的策略就是:集群流控可以精确地控制整个集群的调用总量,结合单机限流兜底,可以更好地发挥流量控制的效果。
集群流控中两种身份:
- Token Client:集群流控客户端,用于向所属 Token Server 通信请求 token。集群限流服务端会返回给客户端结果,决定是否限流。
- Token Server:即集群流控服务端,处理来自 Token Client 的请求,根据配置的集群规则判断是否应该发放 token(是否允许通过)。
四、Sentinel初步安装与使用
1、Sentinel的本地安装
下载的时候选择jar包,如果要是想看源代码的话也可以下载或是可控源代码,这个的现在路径可以走GitHub,jar包的下载地址为:
Releases · alibaba/Sentinel · GitHub
下载完成之后再jar包的目录下代开控制台执行下面的指令(替换jar包的名称),具体的操作指令如下:
java -Dserver.port=8081 -Dcsp.sentinel.dashboard.server=127.0.0.1:8081 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard-1.8.0.jar
相当于是告诉程序他要连接的服务的地址在哪里,在这里自己理解的就是后台的地址,如果没有这个的话页面初始化出来之后可能是没有数据的:

2、原生JDK模式中的使用
构建sentinel项目我们首先要引入依赖,在下面引入的依赖种有些是在注解模式中采用到的,这里会在代码中依赖中标记出来:
<dependencies>
//在JDK模式中只需要引入这里依赖即可
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-coreartifactId>
<version>1.7.1version>
dependency>
//sentine切面注解相关依赖
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-annotation-aspectjartifactId>
<version>1.4.0version>
dependency>
//做web服务
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
dependencies>
配置资源,这里面写明的信息主要是熔断以及限流的规则:
public class RulesUtils {
public static final int MAX_NUM = 50;
public static final int MIN_NUM = 20;
public static final String FLOW_RULES_RESOURCES = "process";
public static final String DEGRADERULES_RULES_RESOURCES = "processError";
/**
* 配置限流策略
*/
public static void initFlowRules() {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
/**
* 限流阈值类型:
* * 并发线程数模式——RuleConstant.FLOW_GRADE_THREAD 0
* * QPS模式——RuleConstant.FLOW_GRADE_QPS 1
*/
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
/**
* 调用关系限流策略:
* * 直接——RuleConstant.STRATEGY_DIRECT 0 (默认)
* * 关联——RuleConstant.STRATEGY_RELATE 1
* * 链路——RuleConstant.STRATEGY_CHAIN 2
*/
rule.setStrategy(RuleConstant.STRATEGY_DIRECT);
/**
* QPS流量流控行为:
* * 直接拒绝——CONTROL_BEHAVIOR_DEFAULT 0 (默认)
* * 慢启动模式——CONTROL_BEHAVIOR_WARM_UP 1
* * 匀速排队——CONTROL_BEHAVIOR_RATE_LIMITER 2
* * 冷启动+匀速排队——CONTROL_BEHAVIOR_WARM_UP_RATE_LIMITER 3
*/
rule.setControlBehavior(RuleConstant.CONTROL_BEHAVIOR_DEFAULT);
rule.setResource(FLOW_RULES_RESOURCES); // 设置需要保护的资源。这个资源的名称必须和SphU.entry中使用的名称保持一致。
rule.setCount(20); // 限流阈值
rule.setLimitApp("default"); // 是否需要针对调用来源进行限流,默认是default,即:不区分调用来源
rule.setClusterMode(false); // 是否是集群限流,默认为否
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
/**
* 配置熔断策略
*/
public static void initDegradeRule() {
List<DegradeRule> rules = new ArrayList<>();
DegradeRule rule = new DegradeRule();
/**
* 熔断策略,支持秒级RT、秒级异常比例、分钟及异常数。默认是秒级RT。
* * 平均响应时间——RuleConstant.DEGRADE_GRADE_RT 0
* * 异常比例——RuleConstant.DEGRADE_GRADE_EXCEPTION_RATIO 1
* * 异常数——RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT 2
*/
rule.setGrade(RuleConstant.DEGRADE_GRADE_EXCEPTION_COUNT);
rule.setResource(DEGRADERULES_RULES_RESOURCES); // 设置需要保护的资源。这个资源的名称必须和SphU.entry中使用的名称保持一致。
rule.setCount(5); // 限流阈值
rule.setTimeWindow(10); // 发生降级时降级恢复超时(以秒为单位)。
rules.add(rule);
DegradeRuleManager.loadRules(rules);
}
}
在项目中相关的配置细项我们可以参考官方的文档,其中需要注意的一点就是在定义资源的时候通过setResource()方法指定的要绑定的资源要与,我们在使用资源的地方一致,这里我们采用了常量的方式,也是为了便于后面的在使用地方的引用。接下来我们就可以写测试程序来测试我们资源所定义的熔断规则了:
-
通过异常来判断是否进行限流
@Slf4j
public class SentinelSphUSimpleDemo {
public static void main(String[] args) {
// runFlowRules();
runDegradeRules();
}
/**
* 限流规则
*/
public static void runFlowRules() {
RulesUtils.initFlowRules();
Entry entry = null;
int i = 0;
while (i < RulesUtils.MAX_NUM) {
try {
entry = SphU.entry(RulesUtils.FLOW_RULES_RESOURCES); // 指定流控资源名称
BusinessService.process(); // 业务逻辑
} catch (BlockException e) {
log.error("请求被SphU限流——block!");
/** 限流后,会走这段代码 */
} finally {
if (entry != null) {
entry.exit();
}
}
i++;
}
}
/**
* 熔断规则
*/
public static void runDegradeRules() {
RulesUtils.initDegradeRule();
Entry entry = null;
int i = 0;
while (i < RulesUtils.MIN_NUM) {
try {
entry = SphU.entry(RulesUtils.DEGRADERULES_RULES_RESOURCES); // 指定熔断资源名称
BusinessService.processError();
} catch (BlockException e) {
log.error("请求被SphU熔断——block!");
/** 限流后,会走这段代码 */
} catch (Throwable t) {
log.error("请求被SphU熔断——业务异常处理!");
Tracer.trace(t);
} finally {
if (entry != null) {
entry.exit();
}
}
i++;
}
}
}
如果是根据异常来做判断的话我们通常会try后面跟多个catch,从而区别是对限流规则异常的处理还是对业务代码异常的处理,这一点在使用的时候是需要注意的。
-
通过布尔值来判断是否进行限流
上面的两种限流,区别仅在于,判断是否进行限流的方式。如果是通过异常来进行的话我们就将有关绑定策略的代码放在一个try块中,如果发生了异常程序就会执行catch代码块中的方法。如果是通过布尔值进行限流则是将绑定则略的方法放在判断体中,从而根据绑定规则的返回结果来决定项目执行那一流程的代码。
@Slf4j
public class SentinelSphOSimpleDemo {
public static void main(String[] args) {
runFlowRules();
// runDegradeRules();
}
/**
* 限流规则
*/
public static void runFlowRules() {
RulesUtils.initFlowRules(); /** 初始化限流规则 */
int i = 0;
while (i < RulesUtils.MAX_NUM) {
if (SphO.entry(RulesUtils.FLOW_RULES_RESOURCES)) { /** 没有限流,会走如下代码 */
try {
BusinessService.process();
} catch (Throwable e) {
log.error("业务逻辑异常");
} finally {
SphO.exit();
}
} else { /** 限流后,会走如下代码 */
log.error("请求被SphO限流——block!");
}
i++;
}
}
/**
* 熔断规则
*/
public static void runDegradeRules() {
RulesUtils.initDegradeRule(); /** 初始化熔断规则 */
int i = 0;
while (i < RulesUtils.MIN_NUM) {
if (SphO.entry(RulesUtils.DEGRADERULES_RULES_RESOURCES)) { /** 没有熔断,会走如下代码 */
try {
BusinessService.processError();
} catch (Throwable t) {
log.error("业务逻辑异常");
Tracer.trace(t);
} finally {
SphO.exit();
}
} else { /** 熔断后,会走如下代码 */
log.error("请求被SphO熔断——block!");
}
i++;
}
}
}
3、集成注解版的使用
在上面JDK的模式下我们将项目做成main中模拟启动,但是在注解版中我们将项目做成web项目,通过浏览器请求来模拟出熔断限流的现象。首先我们需要定义接口:
public interface SentinelWithAnnotationService {
String FLOW_RULES_RESOURCES_PROCESS = "process";
String FLOW_RULES_RESOURCES_PROCESS_1 = "process1";
/** 业务处理逻辑 */
void process();
/** 业务处理逻辑 */
void process1();
/** 初始化流控规则 */
void initFlowRules(String resource);
}
来进行接口的一个实现,在接口的实现中除过有业务代码的实现也还有对资源的定义:
@Service
public class SentinelWithAnnotationServiceImpl implements SentinelWithAnnotationService {
/** 业务处理逻辑 */
@SentinelResource(value = FLOW_RULES_RESOURCES_PROCESS, blockHandler = "processBlockHandler",
fallback = "fallbackHandler")
public void process() {
System.out.println("process run!");
/*您的业务逻辑*/
try {
Thread.sleep(40);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/** Block异常处理函数,参数最后多一个BlockException,其余与原函数一致 */
public void processBlockHandler(BlockException e) {
System.out.println("block!");
}
/** Fallback函数,函数签名与原函数一致或加一个Throwable类型的参数 */
public void fallbackHandler() {
System.out.println("fallback!");
}
/**
* 这里单独演示blockHandlerClass的配置
* blockHandler:表示对应的方法名,并且必须为public static修饰的函数.
* blockHandlerClass:表示对应的blockHandler处理类,
*/
@SentinelResource(value = FLOW_RULES_RESOURCES_PROCESS_1, blockHandler = "processBlockHandler",
blockHandlerClass = {ExceptionUtil.class})
public void process1() {
System.out.println("process1 run!");
}
/** 配置限流策略 */
public void initFlowRules(String resource) {
List<FlowRule> rules = new ArrayList<>();
FlowRule rule = new FlowRule();
rule.setResource(resource);
rule.setGrade(RuleConstant.FLOW_GRADE_QPS);
rule.setCount(20); // Set limit QPS to 20.
rules.add(rule);
FlowRuleManager.loadRules(rules);
}
}
在这里有关资源的定义实际上是没有发生改变的,主要的改变是在使用资源来对业务代码进行限流的时候,我们可以通过注解的方式来实现,通过注解上的信息来表明我们使用按个资源,如果要是发生了限流应该如何处理。当时在上面的程序我们我们返现虽然在使用的时候我们制定了资源,但是在定义的时候我么并没有指定资源是什么,而是这个资源是通过参数的形式传递过来的。那么这个参数又是在合适传递进来起作用的呢,这一点就要说到我们的serviceImpl是在哪里调用的——controller中
@RestController
public class SentinelSimpleDemoController {
private static final int MAX_NUM = 50;
@Resource
private SentinelWithAnnotationService sentinelWithAnnotationService;
/**
* http://localhost:8000/process
*/
@GetMapping("/process")
public void process() {
sentinelWithAnnotationService.initFlowRules(SentinelWithAnnotationService.FLOW_RULES_RESOURCES_PROCESS);
int i = 0;
while (i < MAX_NUM) {
sentinelWithAnnotationService.process();
i++;
}
}
/**
* http://localhost:8000/process1
*/
@GetMapping("/process1")
public void process1() {
sentinelWithAnnotationService.initFlowRules(SentinelWithAnnotationService.FLOW_RULES_RESOURCES_PROCESS_1);
int i = 0;
while (i < MAX_NUM) {
sentinelWithAnnotationService.process1();
i++;
}
}
}
这样的写法虽然已经比jdk模式的好用了一些但是感觉还是没有那么优雅,如果要是资源的定义也是可以通过注解实现的那么应该就会好一些。但是考虑到目前的这种形式资源是可以在多个地方使用的,这样的实现方式应该会跟节省一些资源吧。
想要使用注解我们是还需要在Spring的容器中注入一个SentinelResourceAspect的Bean的:
@Configuration
public class SentinelAspectConfiguration {
@Bean
public SentinelResourceAspect sentinelResourceAspect() {
return new SentinelResourceAspect();
}
}
4、DashBoard模式下的使用
在使用DashBoard模式的时候如果我们不开启,外部存储的话就会造成,每当我们DashBoard的服务已启动所有的链路信息以及配置信息都会丢失,所以在使用DashBoard的时候我们通常还会配置Nacos,这时候需要的依赖就比较多了:
<dependencies>
<dependency>
<groupId>com.alibaba.cloudgroupId>
<artifactId>spring-cloud-starter-alibaba-sentinelartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
dependency>
<dependency>
<groupId>org.apache.commonsgroupId>
<artifactId>commons-lang3artifactId>
<version>3.7version>
dependency>
<dependency>
<groupId>com.alibaba.cspgroupId>
<artifactId>sentinel-datasource-nacosartifactId>
<version>1.7.0version>
dependency>
dependencies>
引入好依赖我们要做的第一步就是配置项目有关的内容,这时候我们在资源包下的application.yml下进行:
server:
port: 8001
spring:
application:
name: sentinel-nacos-demo
cloud:
sentinel:
transport:
dashboard: 127.0.0.1:8081
datasource:
- nacos:
server-addr: 127.0.0.1:8847
data-id: sentinel-nacos-demo-sentinel-flow
group-id: DEFAULT_GROUP
data-type: json
rule-type: flow
这里我们看到我们配置了data-id,对的没毛病我们使用的就是nacos配置中心的功能,但是上来我们先不使用配置中心的功能,直接将限流策略的资源硬编码到我们的程序中:
首先我们需要进行的还是配置我们的限流规则,原来配置的时候我们在使用限流规则之前都需要执行一下初始化相当于是创造一个限流规则的实例。在这里我们通过继承一个InitFunc的接口来实现限流规则的自动初始化,这样的操作采用了SPI的相关机理,所以我们需要在resources下面创建符合JDK 中SPI相关规范的配置文件:
public class FlowRuleStrategy implements InitFunc {
@Override
public void init() throws Exception {
List<FlowRule> rules = new ArrayList<>();
FlowRule flowRule = new FlowRule();
flowRule.setCount(1);
flowRule.setResource("foo1");
flowRule.setGrade(RuleConstant.FLOW_GRADE_QPS);
flowRule.setLimitApp("default");
rules.add(flowRule);
FlowRuleManager.loadRules(rules);
}
}
这时候编写一个Controller类,并写相应的方法,来进行一个请求测试开我们上面的硬编码是否发生作用:
@SentinelResource(value = "foo1", blockHandler = "blockHandlerFoo1")
@GetMapping("/foo1")
public String foo1() {
return "-----foo1-----";
}
public String blockHandlerFoo1(BlockException e) {
return "request blocking!";
}
启动程序之后我们请求http://localhost:8001/foo1 进行连续点击程序的限流发生作用,这时候看Dashboard可以看到:

Dashboard中能发现的族点链路是只有这个请求地址发生了Dashboard中才能看到:

链路显示出来之后我们就可以直接在后面的操作中进行相应的配置了,配置完成之后就会在流控规则中看到相应的配置。如果我们将数据中心的配置放开接入配置中兴,我们原来硬编码的规则就会被冲掉他会从数据中心中读取限流规则:
这里需要注意的一点是我们的nacos配置的是默认的名称空间public如果要是将数据配置再了自己定义的名称空间下的话需要另外指出

在nacos中配置的内容为:
[
{
"resource": "/withnacos",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"clusterMode": false
}
]
之后我们直接在配置中心改规则信息就可以起到一个限流的作用。写到这里你可能会问,限流异常之类的我们应该如何处理,我们可以通过继承特定的异常接口来实现自定义我们的异常,这里需要注意的一点就是每一类型的异常只能实现一个否则的话程序会报错。
/**
* 自定义URL限流异常
*/
@Service
public class MuseBlockHandler implements UrlBlockHandler {
@Override
public void blocked(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse,
BlockException e) throws IOException {
httpServletResponse.setHeader("Content-Type", "application/json;charset=UTF-8");
String message = "{\n"
+ "\t\"code\":\"400\",\n"
+ "\t\"message\":\"请求已被限流!\"\n"
+ "}";
httpServletResponse.getWriter().write(message);
}
}
当我们请求的连接后面有用户自定义数据的时候,这时候程序的请求入口地址都是一个但是从Url上来看的话确实不同的:
/**
* 案例3:URL资源清洗
* http://localhost:8001/urlCleaner/1和http://localhost:8001/urlCleaner/2
*/
@GetMapping("/urlCleaner/{id}")
public String urlCleaner(@PathVariable("id") int id) {
return "-----urlCleaner-----";
}
这时候我们实际上想限流的是urlCleaner,这就需要进行Url资源清洗:
@Service
public class MuseUrlCleaner implements UrlCleaner {
@Override
public String clean(String s) {
if (StringUtils.isBlank(s)) {
return s;
}
if (s.startsWith("/urlCleaner/")) {
return "/urlCleaner/*";
}
return s;
}
}