NLP实践——VQA/Caption生成模型BLIP-2的应用介绍
NLP实践——VQA/Caption生成模型BLIP-2的应用介绍
- 1. 简介
- 2. 模型下载
- 3. 运行环境
- 4. 模型应用
1. 简介
今天介绍一个跨模态模型,也是最近比较火的一个工作,叫做BLIP-2。很久很久之前我写过一个简单的image caption项目的介绍,那个模型原理比较简单,就是encode-decode模式,但是项目却不怎么好运行,而现在,随着技术的迭代升级,还有huggingface社区的加持,想实现图文生成变得方便了许多。
BLIP模型是一个对图像部分和文字部分分别编码,然后再深度交互的模型,对于模型的技术细节,本文不做过多的介绍,可以直接阅读论文,总的来说没有什么难以理解的点。
利用这个模型,你可以一键生成对图像的描述,或者询问图像中的信息,与模型进行对话等。
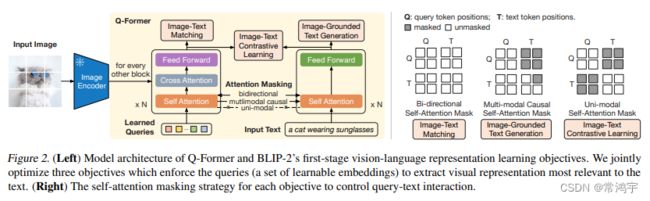
下面是项目和论文的地址。
项目地址:https://github.com/salesforce/LAVIS/tree/main/projects/blip2
论文地址:https://arxiv.org/abs/2301.12597
本文将介绍如何利用huggingface的transformers模块,实现BLIP-2的调用。
2. 模型下载
目前HF上开源出来的BLIP-2有好几个模型,这里选择Salesforce/blip2-opt-6.7b作为例子进行介绍,我们进入该项目的地址:
https://huggingface.co/Salesforce/blip2-opt-6.7b/tree/main
把文件列表里的所有文件全都下载下来,放在一个目录里。因为文件比较大,所以不建议直接联网下载到hf的默认缓存区,可以像我这样下载到自定义的地址,在加载模型的时候手动指定目录即可。
如果你迫不及待地想要体验一下在线版,可以直接进入space,直接在线操作:
https://huggingface.co/spaces/Salesforce/BLIP2
3. 运行环境
运行BLIP-2,需要最新版本的transformers模块,截至目前,已经发布的transformers的最高版本是4.26.1,我尝试使用这个版本,发现仍然没有BLIP2相关的模型,所以到git上找到开发中的版本4.27-dev。
截至目前(2023-02-16),进入git上官方transformers,你看到的transformers版本即为4.27的开发版,如果当你体验这个项目的时候,正式版已经更新,就可以跳过这一步,直接通过pip安装4.27及以上的版本:
pip install transformers==4.27
如果安装失败了,说明它还没有上线,那你需要手动安装。
-
- 通过git clone或者download zip,下载官方transformers,然后解压它,并且激活你的使用的python环境,
-
- 直接执行python setup.py,即可完成安装。
-
- 此时进入你相应地python环境,就可以成功地引用BLIP-2相关的模块了。
4. 模型应用
首先import所需的模块:
import torch
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
然后是建模,除了模型之外,有一个processor,起到类似tokenizer的作用,既可以对文本进行tokenize,也可以将图像划分为patch:
# 其中这个路径是上文中介绍的下载的模型所存放的路径
processor = Blip2Processor.from_pretrained("your_path_to/BLIP-2-opt/")
model = Blip2ForConditionalGeneration.from_pretrained("your_path_to/BLIP-2-opt/")
我们随便读取一张图片,这里我用了一张之前我自己用disco-diffusion生成的一张图片(原本准备给自己写的小说做配图的)。
image = Image.open('./my_pic_1.png')
对于image caption,我们只需要对图像进行操作,因为文本部分完全是由模型生成的:
# 注意,由于模型过大,我并没有把它放到GPU上
# 所以相应地在生成inputs的时候,也不要放在GPU上或者使用16精度计算
inputs = processor(images=image, return_tensors="pt") # .to(device, torch.float16)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
# 'a rocky cliff with trees and water in the background'
可以看到生成的描述是比较贴切的。
然后来问它一个问题,比起caption,只需要对prompt进行tokenize:
prompt = "Question: What tree is it in the picture? Answer:"
inputs = processor(images=image, text=prompt, return_tensors="pt") #.to(device, torch.float16)
# 注意这个时候的inputs.keys()包括了'pixel_values', 'input_ids', 'attention_mask'
inputs = processor(images=image, text=prompt, return_tensors="pt") #.to(device, torch.float16)
generated_ids = model.generate(**inputs)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0].strip()
print(generated_text)
# "It's a pine tree"
虽说它回答成了’a tree’,但是树的类型应该是对了。
参考文档:https://huggingface.co/docs/transformers/main/en/model_doc/blip-2#transformers.Blip2ForConditionalGeneration.forward.example
以上就是本文的全部内容了,如果你觉得还不错,欢迎点个一键三连加关注,我们下期再见。