Mysql到Hbase数据实时增量同步案例(框架:MySQL-binlog+Maxwell+Kafka+python+Hbase)
导语
有童鞋私信我,问我如何通过MySQL binlog数据同步到其他数据库(比如:Hbase、Hive等),之前写过几篇博客(canal与Maxwell比较、Kafka、hbase、python等),今天我就这里做一个案例实践操作。
系统环境
CentOS Linux、JDK、zookeeper、kafka、Maxwell、MySQL、Hbase
本次可以学习如下知识:
1)、MySQL binlog启用配置与使用
2)、binlog查看提取方案maxwell
3)、zookeeper基本使用
4)、Kafka基本使用
5)、Hbase基本使用
6)、Python操作Hbase
本次实践为:数据增量同步
采用方案为:binlog->maxwell->Kafka->Hbase,当然你也可以使用canal替换maxwell,本博客使用maxwell。
业务场景
假如公司是做社交电商的,一些业务场景会给用户发各种类型的收益,然后用户在app上可以看到自己的各种汇总收益及收益明细。 在项目运营初期,用户数少、收益明细少,所以用户在app获取收益汇总时不会有性能相关的问题。然后随着用户数量的增加,业务的扩展,用户收益数据越来越多,用户每次访问收益汇总信息时,实时的通过sql汇总查询会遇到性能问题。
解决方案:
A:离线汇总+缓存
B:汇总表+业务逻辑实时【消息队列等】写入到汇总表
C:mysql+ maxwell+kafka实时计算
方案分析与选择:
A 方案问题: 实时性不足,用户获到收益后,明细存在但却没有加到汇总信息中。而且业务中有使用可用余额支付的场景,无法完全满足用户及业务的需求。
B 方案问题:业务耦合,每个业务线都要关注数据实时问题。 业务线多了的话有可能会遗漏部分场景。
C 方案:业务解耦,业务开发时无需过度关注收益汇总问题。实时性较强,收益数据正常产生到用户看到基本在毫秒级别
通过以上比较分析,我们选择C方案。
mysql+ maxwell+kafka实时计算介绍
当用户收益数据产生写入到mysql, maxwell监控到mysql的写操作,解析binlog日志写入到kafka。 消费者(python)消费kafka消息,根据具体的业务汇总数据到汇总表, app查看直接读取汇总表记录即可。
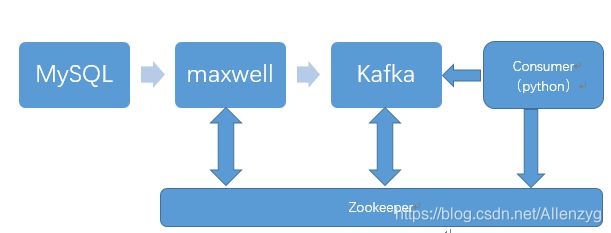
zookeeper保证Kafka、Maxwell的高可用。
1.Mysql binlog
binlog是sever层维护的一种二进制日志,与innodb引擎中的redo/undo log是完全不同的日志。
可以简单的理解该log记录了sql标中的更新删除插入等操作记录。通常应用在数据恢复、备份等场景。
MySQL-binlog讲解参见我的博客:MySQL-binlog日志(日志管理&案例:使用binlog日志进行数据恢复)_Allenzyg的博客-CSDN博客_log_bin=mysql_bin
2.Kafka
Kafka是使用Java开发的应用程序,Kafka需要运行Zookeeper,两者都需要Java,所以在需要安装Zookeeper和Kafka之前,先安装Java环境。
Kafka 是一种分布式的,基于发布 / 订阅的消息系统。在这里可以把Kafka理解为生产消费者模式。
2.1 Java安装
参见我的博客:Hadoop集群安装(3个节点)_Allenzyg的博客-CSDN博客
2.2 Zookeeper安装及配置
参见我的博客:zookeeper安装与验证_Allenzyg的博客-CSDN博客_验证zookeeper安装成功
2.3 Kafka安装及配置
参见我的博客:Kafka安装与验证_Allenzyg的博客-CSDN博客_kafka 验证
3.binlog提取工具Maxwell
3.1 Maxwell安装及配置
Maxwell是将mysql binlog中的insert、update等操作提取出来,并以json数据返回的一个工具。
参见我的博客:Maxwell与Canal_Allenzyg的博客-CSDN博客_maxwell和canal
3.2 配置Maxwell
cp config.properties.example config.properties
vi config.properties
maxwell配置:
log_level=info
# 默认生产者
producer=kafka
kafka.bootstrap.servers=localhost:9093
# mysql login info
host=localhost
user=maxwell
password=maxwell
# kafka配置
kafka_topic=test
kafka.compression.type=snappy
kafka.acks=all
kinesis_stream=test3.3启动maxwell(进入maxwell的安装目录下)
bin/maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --producer=kafka --kafka.bootstrap.servers=localhost:9093 --kafka_topic=test

补充:
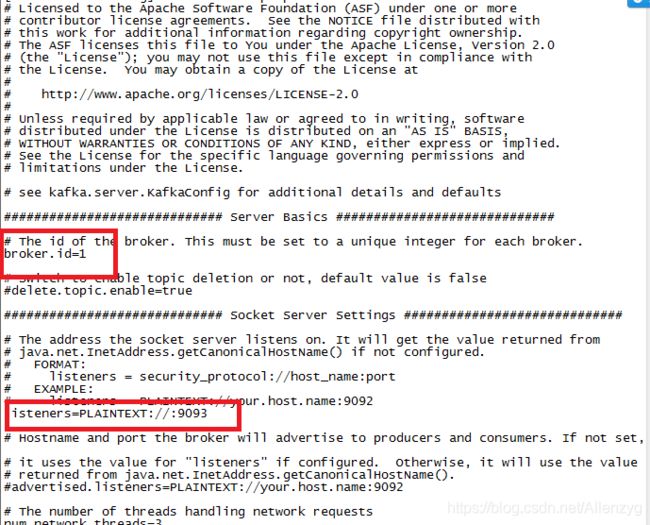
因为我修改了Kafka配置文件server1.properties,改变了端口,所以我这里是9093,不要盲目使用本博客的端口,视配置文件情况而定。
4.Hbase
4.1 安装及配置
参见我的博客:HBase安装与验证_Allenzyg的博客-CSDN博客_验证hbase安装成功
注意:Hadoop、zookeeper、hbase启动顺序。
4.2 Python操作Hbase
pip install thrift
pip install happybase
python连接Hbase需要启用thrift接口,启用方式:
./bin/hbase-daemon.sh start thrift

备注:如果不启用thrift,会报错:message='No protocol version header'
python连接hbase出现message='No protocol version header' 报错
错误原因
1: hbase的thrift服务没启动
2: 端口有误, 不是9090
查看是否启动:jps –m

查看hbase已有的表:list
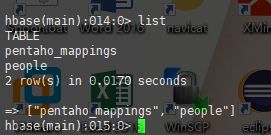
补充:如果使用list出现:ERROR: Can't get master address from ZooKeeper; znode data == null。出现此问题可能是zookeeper不稳定造成的,采用的是虚拟机,经常挂起的状态,使用hbase的list命令出现下面错误,这个可能是hbase的稳定性造成的。
Hbase出现ERROR: Can't get master address from ZooKeeper; znode data == null解决办法:
重启hbase
stop-hbase.sh
start-hbase.sh
4.3 Python代码实现
import happybase
class hbase():
def __init__(self):
self.conn = happybase.Connection("node4", 9090)
print("===========HBASE数据库表=============\n")
print(self.conn.tables())
self.conn.open()
def createTable(self,table_name,families):
self.conn.create_table(table_name,families)
def insertData(self,table_name,row,data):
table = self.conn.table(table_name)
table.put(row=row,data=data)
def deletTable(self,table_name,flag):
self.conn.delete_table(table_name,flag)
def getRow(self,table_name):
table = self.conn.table(table_name)
print(table.scan())
i=0
for key, value in table.scan():
print(key)
print(value)
i+=1
print(i)
def closeTable(self):
self.conn.close()
htb = hbase()
table_name = 'test'
families = {'info':{}}
htb.createTable(table_name,families)
htb.insertData(table_name,'row',{'info:content':'rongqiao','info:price':'12990'})
"""
htb.deletTable(table_name,True)
"""
htb.getRow(table_name)运行结果:
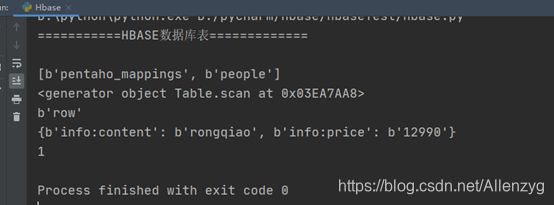
在hbase上查看数据:
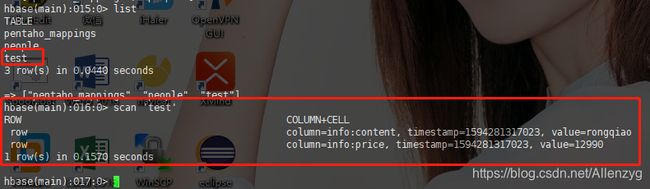
5. 案例
上述介绍了所有的安装与使用,下面来实战。
5.1 Kafka消费
流程如下:
往Mysql中实时更新,插入数据等操作,会记录到binlog中,然后使用maxwell解析binlog,用Kafka进行消费。
依次启动maxwell,Kafka以及消费Kafka。
1.启动maxwell
bin/maxwell --user='maxwell' --password='maxwell' --host='127.0.0.1' --producer=kafka --kafka.bootstrap.servers=localhost:9093 --kafka_topic=test
2.启动Kafka
先启动zookeeper(所有节点)
zkServer.sh start
kafka-server-start.sh config/server1.properties
3.启动消费Kafka
./kafka-console-consumer.sh --bootstrap-server localhost:9093 --topic test创建数据库:test
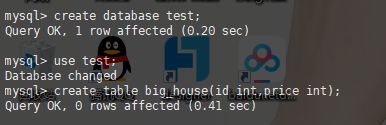
在Maxwell查看到信息:
![]()
在binlog日志查看到信息:

插入并更新操作,在消费Kafka看到的信息:
![]()
5.2 Hbase消费
Hbase消费则是在Kafka消费基础上做的一个调用,通过pykafka进行消费生产者的数据到Hbase中。流程为:
binlog->maxwell->python操作Kafka->python操作hbase->Hbase。
完整实现如下:
pip install pykafka

代码:
from pykafka import KafkaClient
import happybase
import json
class mysqlToHbase():
def __init__(self):
self.client = KafkaClient(hosts="node4:9093")
self.topic = self.client.topics['test']
self.consumer = self.topic.get_balanced_consumer(consumer_group='my_group', auto_commit_enable=True,
zookeeper_connect='node4:2181')
#print(self.consumer)
self.conn = happybase.Connection("node4", 9090)
print("===========HBASE数据库表=============\n")
print(self.conn.tables())
self.conn.open()
def putTohbase(self,table_name):
for m in self.consumer:
database = json.loads(m.value.decode('utf-8'))["database"]
name = json.loads(m.value.decode('utf-8'))["table"]
row_data = json.loads(m.value.decode('utf-8'))["data"]
if database == 'test' and name == 'big_house':
print(json.loads(m.value.decode('utf-8')))
row_id = row_data["id"]
row = str(row_id)
del row_data["id"]
data = {}
for each in row_data:
neweach='info:'+each
data[neweach] = row_data[each]
data['info:price'] = str(data['info:price'])
self.insertData(table_name,row,data)
def createTable(self,table_name,families):
self.conn.create_table(table_name,families)
# htb.insertData(table_name, 'row', {'info:content': 'asdas', 'info:price': '299'})
def insertData(self,table_name,row,data):
table = self.conn.table(table_name)
table.put(row=row,data=data)
def deletTable(self,table_name,flag):
self.conn.delete_table(table_name,flag)
def getRow(self,table_name):
table = self.conn.table(table_name)
print(table.scan())
i=0
for key, value in table.scan():
print(key)
print(value)
i+=1
print(i)
def closeTable(self):
self.conn.close()
htb = mysqlToHbase()
table_name = 'sql_hbase'
families = {'info':{}}
#htb.createTable(table_name,families)
htb.putTohbase(table_name)
htb.closeTable()
#htb.deletTable(table_name,True)
# htb.getRow(table_name)小插曲1:
| 运行代码,报错:
意思是:需要下载python-snappy,但使用pip install python-snappy下载失败。会报错:is not a supported wheel on this platform。出现这个问题的原因是版本不匹配。 使用pip install安装.whl文件出现is not a supported wheel on this platform解决办法。 解决办法: Step1:查看本机python的版本以及匹配哪些文件 >python >>> import pip._internal >>> print(pip._internal.pep425tags.get_supported())
Step2:下载安装对应的版本文件即可(本机python pip命令匹配的版本是python_snappy-0.5.4-cp38-cp38-win32.whl这个文件) 补充:各版本python_snappy下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/ Step3:使用命令pip install python_snappy-0.5.4-cp38-cp38-win32.whl安装成功。 注意:安装的时候注意路径要设置成自己下载的文件存在的路径下安装,否则会出现找不到文件的情况 |


小插曲2:
| 再次运行代码,发现只能同步历史数据,新增的数据并不会同步到hbase,并报如下信息:raise TTransportException(type=TTransportException.END_OF_FILE, thriftpy2.transport.base.TTransportException: TTransportException(type=4, message='TSocket read 0 bytes') 原因:问题出在protocol的协议使用上,python要使用TCompactProtocol,而不能使用TBinaryProtocol。thrift 的server端和client端的协议不匹配造成的。 补充:
解决办法:修改hbase-site.xml,禁用TFramedTransport和TCompactProtocol功能,即:(如果有,把true改为false,如果没有,添加即可): 重启thrift 服务器:./bin/hbase-daemon.sh restart thrift |
运行代码:
先查看一下数据:
导入数据之前:Hbase查看数据
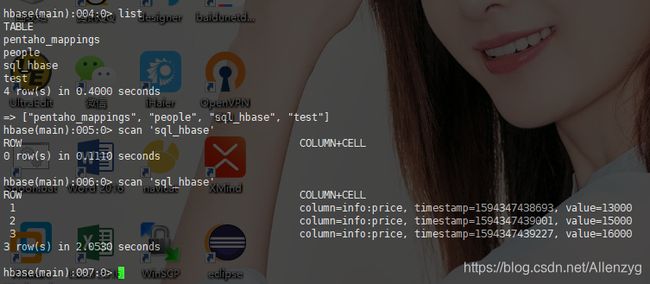
插入数据:

代码运行界面:这里由于不稳定造成了心跳检测超时,重新连接了。不影响结果。

Hbase查看数据:
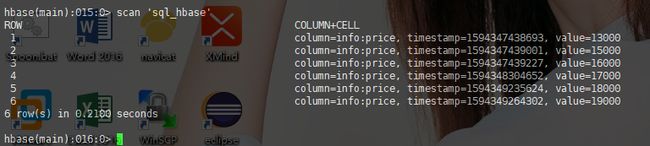
以上说明:当mysql中进行相应操作,hbase便会同步。
补充:上述过程会把MySQL数据库中表历史数据先同步到Hbase表,然后数据增量同步。