Python scrapy爬虫框架使用教程与实战示例
目录
- 1. scrapy的安装
- 2. scrapy的使用
-
- 2.1 创建项目
- 2.2 项目代码编写
-
- 2.2.1 items.py
- 2.2.2 knowledge_graph.py
- 2.2.3 pipelines.py
- 2.2.4 middlewares.py
- 2.2.5 settings.py
- 2.3 运行爬虫
本文从零开始,讲解scrapy框架的安装和爬虫项目的创建和使用,遇到scrapy爬虫的知识点,重点突出讲解
1. scrapy的安装
-
Twisted依赖包的安装
因为scrapy依赖Twisted,所有我们先安装Twisted
pip的源没有Twisted的资源, 这里我们通过下载whl文件的方式进行安装
从python windows安装包下载,如下图所示,下载对应python版本和操作系统版本的Twisted安装包

下载完之后,通过命令pip install C:\Users\Administrator\Desktop\Twisted-20.3.0-cp36-cp36m-win_amd64.whl进行安装 -
安装scrapy
scrapy可以直接通过pip安装,安装命令:pip install scrapy -
测试是否安装成功
在命令行,输入scrapy进行测试,如果出现如下内容,就代表安装成功
也可以从下面的内容看到常用的scrapy子命令
C:\Users\Administrator\Desktop>scrapy
Scrapy 2.3.0 - no active project
Usage:
scrapy [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy -h" to see more info about a command
其中本文用到的scrapy命令:
scrapy startproject scrapy_project_name
表示创建一个爬虫项目,爬虫项目的名称为scrapy_project_name
2. scrapy的使用
2.1 创建项目
2.1.1 创建Python项目
首先我们在IDEA中创建一个Python项目,python项目名称为:disease_spider,项目结构如下图所示,目录为:C:\Users\Administrator\Desktop\disease_spider:

2.1.2 创建scrapy爬虫项目
接着我们在命令行中,cd到C:\Users\Administrator\Desktop\disease_spider目录下,执行scrapy startproject disease_spider创建一个爬虫项目,如下图所示:

现在的项目结构如下图所示:

我们接着执行cd disease_spider和scrapy命令,会发现scrapy的Available commands多了crawl等命令,如下所示:
C:\Users\Administrator\Desktop\disease_spider>cd disease_spider
C:\Users\Administrator\Desktop\disease_spider\disease_spider>scrapy
Scrapy 2.3.0 - project: disease_spider
Usage:
scrapy [options] [args]
Available commands:
bench Run quick benchmark test
check Check spider contracts
commands
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
Use "scrapy -h" to see more info about a command
其中本文用到的scrapy命令:
- scrapy genspider spider_name start_urls
表示创建一个爬虫,并指定start_urls - scrapy crawl spider_name
表示运行一个爬虫
2.1.3 新建爬虫文件
在C:\Users\Administrator\Desktop\disease_spider\disease_spider\disease_spider\spiders目录下,执行scrapy genspider knowledge_graph cmekg.pcl.ac.cn,会生成knowledge_graph.py文件

knowledge_graph.py内容如下:
import scrapy
class KnowledgeGraphSpider(scrapy.Spider):
name = 'knowledge_graph'
allowed_domains = ['cmekg.pcl.ac.cn']
start_urls = ['http://cmekg.pcl.ac.cn/']
def parse(self, response):
pass
2.1.4 新建项目启动文件
在C:\Users\Administrator\Desktop\disease_spider\disease_spider\disease_spider\spiders目录下,新建main.py文件,内容如下:
from scrapy import cmdline
cmdline.execute("scrapy crawl knowledge_graph".split())
其中cmdline是scrapy的一个模块,可以在python代码中直接执行scrapy的命令行命令,如果不想打印出日志,可以使用scrapy crawl knowledge_graph --nolog命令
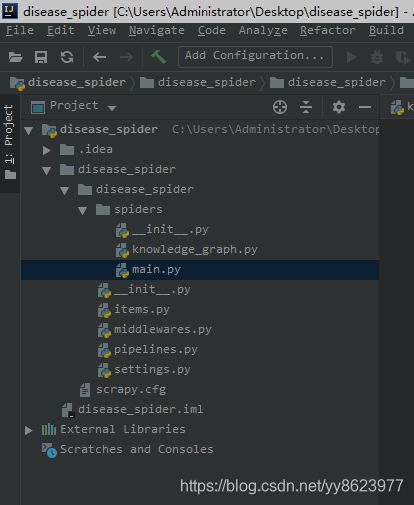
2.1.5 最终项目结构
到这里我们的项目结构就创建完毕了,接下来讲解具体的项目内容编写:
2.2 项目代码编写
本部分代码示例在实际代码开发的基础上,对不必要的内容进行了删减,旨在让读者学习scrapy框架的核心内容
本项目代码共5大模块:
- items.py:定义数据结构
- knowledge_graph.py:爬虫的具体实现
- pipelines.py:数据输出实现
- middlewares.py:UserAgent和Proxy代理实现
- settings.py:项目的配置文件
2.2.1 items.py
代码内容:
import scrapy
class ParameterItem(scrapy.Item):
id = scrapy.Field()
class Often_100_disease_spiderItem(scrapy.Item):
diseaseMapStr = scrapy.Field()
class Child_often_disease_spiderItem(scrapy.Item):
diseaseMapStr = scrapy.Field()
说明:
- Item是scrapy的数据结构模块,用于定义模块内或各个模块之间的数据传输的格式;如
knowledge_graph.py爬取到的数据,要以什么样的数据格式传输给pipelines.py - 定义1个Item的方式如下:
class SpiderItem1(scrapy.Item):
field1 = scrapy.Field()
field2 = scrapy.Field()
- 一个items.py文件可以定义多个Item
2.2.2 knowledge_graph.py
- knowledge_graph是爬虫的具体实现模块,包含url的解析和数据的处理
代码内容:
import scrapy
from disease_spider.items import Child_often_disease_spiderItem
from disease_spider.items import Often_100_disease_spiderItem
from disease_spider.items import ParameterItem
often_100_disease_label = 2
child_often_disease_label = 3
class KnowledgeGraphSpider(scrapy.Spider):
name = 'knowledge_graph'
allowed_domains = ['zstp.pcl.ac.cn:8002']
# 用来查看请求的ip地址
start_urls = ['https://zstp.pcl.ac.cn:8002/load_tree/疾病']
def parse(self, response):
# response.request.headers["User-Agent"]
disease_tree_str = response.body
# 此函数根据不同的label,从disease_tree_str中得到不同的子urls
disease_url2s = self.func1(disease_tree_str, often_100_disease_label)
for disease_url2 in disease_url2s:
parameterItem2 = ParameterItem()
parameterItem2["id"] = often_100_disease_label
yield scrapy.Request(disease_url2, callback=self.parse_disease_url, dont_filter=True,
meta={"parameterItem": parameterItem2})
disease_url3s = self.func1(disease_tree_str, child_often_disease_label)
for disease_url3 in disease_url3s:
parameterItem3 = ParameterItem()
parameterItem3["id"] = child_often_disease_label
yield scrapy.Request(disease_url3, callback=self.parse_disease_url, dont_filter=True,
meta={"parameterItem": parameterItem3})
def parse_disease_url(self, response):
disease_str = response.body
# 此函数经过一系列解析,得到符合条件的结果
diseaseMapStr = self.func2(disease_str)
if response.meta["parameterItem"]["id"] == often_100_disease_label:
often_100_disease_spiderItem = Often_100_disease_spiderItem()
often_100_disease_spiderItem["diseaseMapStr"] = diseaseMapStr
yield often_100_disease_spiderItem
if response.meta["parameterItem"]["id"] == child_often_disease_label:
child_often_disease_spiderItem = Child_often_disease_spiderItem()
child_often_disease_spiderItem["diseaseMapStr"] = diseaseMapStr
yield child_often_disease_spiderItem
说明:
- 本代码的主要执行流程是:
先解析start_urls的内容,根据不同的label形成不同的子urls,再循环爬取各个子url,再将子url的结果内容以不同的Item返回 - 爬虫参数的定义
name = 'knowledge_graph'
allowed_domains = ['zstp.pcl.ac.cn:8002']
# 可以用来查看请求的ip地址
start_urls = ['https://zstp.pcl.ac.cn:8002/load_tree/疾病']
分别定义爬虫的名称、允许爬取的域名、爬取的父urls
- 当启动爬虫时,会自动执行parse函数,返回start_urls的response
- 定义
ParameterItem以便向parse_disease_url函数传递参数 - yield scrapy.Request(…)会异步解析子url,所以返回值为
None- disease_url2:要爬取的url
- callback:调用此回调函数解析url
- dont_filter:是否对要爬取的url不过滤
- parse_disease_url函数负责解析子url的具体操作并将结果返回给pipeline
2.2.3 pipelines.py
- pipelines是数据的输出模块,knowledge_graph
yield的数据,需要通过pipelines输出到文件或数据库等
代码内容:
from disease_spider.items import Often_100_disease_spiderItem
from disease_spider.items import Child_often_disease_spiderItem
class DiseaseSpiderPipeline:
def __init__(self):
self.often_100_disease_filename= ...
self.child_often_disease_filename= ...
def process_item(self, item, spider):
if isinstance(item, Often_100_disease_spiderItem):
self.often_100_disease_filename.write(item["diseaseMapStr"])
if isinstance(item, Child_often_disease_spiderItem):
self.child_often_disease_filename.write(item["diseaseMapStr"])
return item
def close_spider(self, spider):
self.often_100_disease_filename.close()
self.child_often_disease_filename.close()
说明:
- 运行爬虫时,会自动执行process_item函数,根据不同的Item,输出到不同的文件中
- 在close_spider函数中记得对资源进行close
2.2.4 middlewares.py
- 进行Proxy代理和User-Agent的设置
代码内容:
class MyProxySpiderMiddleware:
def get_random_request_url(self):
# 从网上的链接获取代理ip, 格式为:http://xxx.xxx.xxx.xxx
request_url = requests.get("...").text
return request_url
def process_request(self,request, spider):
request_url = self.get_random_request_url()
request.meta["proxy"]=request_url
def process_response(self, request, response, spider):
if response.status != 200:
request_url = self.get_random_request_url()
request.meta["proxy"]=request_url
return request
return response
class MyUserAgentSpiderMiddleware:
def __init__(self):
self.user_agent_list = [
'Mozilla / 5.0(Macintosh;U;IntelMacOSX10_6_8;en - us) AppleWebKit / 534.50(KHTML, likeGecko) Version / 5.1Safari / 534.50',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1',
'Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11',
'Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60',
'Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50',
'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36',
'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Maxthon/4.4.3.4000 Chrome/30.0.1599.101 Safari/537.36',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.122 UBrowser/4.0.3214.0 Safari/537.36',
'Mozilla/5.0 (PlayBook; U; RIM Tablet OS 2.1.0; en-US) AppleWebKit/536.2+ (KHTML, like Gecko) Version/7.2.1.0 Safari/536.2+',
'Mozilla/5.0 (MeeGo; NokiaN9) AppleWebKit/534.13 (KHTML, like Gecko) NokiaBrowser/8.5.0 Mobile Safari/534.13',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10',
'Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13',
'Mozilla/5.0 (BlackBerry; U; BlackBerry 9800; en) AppleWebKit/534.1+ (KHTML, like Gecko) Version/6.0.0.337 Mobile Safari/534.1+',
'Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0',
'Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)',
'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPod; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (iPad; U; CPU OS 4_2_1 like Mac OS X; zh-cn) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8C148 Safari/6533.18.5',
'Mozilla/5.0 (iPad; U; CPU OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5',
'Mozilla/5.0 (Linux; U; Android 2.2.1; zh-cn; HTC_Wildfire_A3333 Build/FRG83D) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'Mozilla/5.0 (Linux; U; Android 2.3.7; en-us; Nexus One Build/FRF91) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1',
'Opera/9.80 (Android 2.3.4; Linux; Opera Mobi/build-1107180945; U; en-GB) Presto/2.8.149 Version/11.10',
'Mozilla/5.0 (Linux; U; Android 3.0; en-us; Xoom Build/HRI39) AppleWebKit/534.13 (KHTML, like Gecko) Version/4.0 Safari/534.13',
'Mozilla/5.0 (hp-tablet; Linux; hpwOS/3.0.0; U; en-US) AppleWebKit/534.6 (KHTML, like Gecko) wOSBrowser/233.70 Safari/534.6 TouchPad/1.0',
'Mozilla/5.0 (SymbianOS/9.4; Series60/5.0 NokiaN97-1/20.0.019; Profile/MIDP-2.1 Configuration/CLDC-1.1) AppleWebKit/525 (KHTML, like Gecko) BrowserNG/7.1.18124',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows Phone OS 7.5; Trident/5.0; IEMobile/9.0; HTC; Titan)',
'Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19',
'Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30',
'Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1'
]
def process_request(self,request, spider):
user_agent = random.choice(self.user_agent_list)
request.headers.setdefault("User-Agent", user_agent)
说明:
- 代理ip的格式为:http://xxx.xxx.xxx.xxx
- process_response函数的作用是,当response的status不等于200,表示爬虫失败,可能是被网页识别为爬虫,而禁止爬取,所以重新设置proxy代理,return request重新爬取
2.2.5 settings.py
- 进行爬虫项目的运行参数配置
代码内容:
ITEM_PIPELINES = {
'disease_spider.pipelines.DiseaseSpiderPipeline': 1,
}
DOWNLOADER_MIDDLEWARES = {
'disease_spider.middlewares.MyProxySpiderMiddleware': 543,
'disease_spider.middlewares.MyUserAgentSpiderMiddleware': 43
}
ROBOTSTXT_OBEY = False
COOKIES_ENABLED = False
DOWNLOAD_DELAY = 0.1 # 100ms
RETRY_ENABLED = True
RETRY_TIMES = 13
HTTPERROR_ALLOWED_CODES = [301,302]
REDIRECT_ENABLED = False
说明:
ITEM_PIPELINES:设置pipelines的实现类和优先级DOWNLOADER_MIDDLEWARES:设置proxy代理和User-Agent的实现类和优先级COOKIES_ENABLED:本文没有登录操作,关闭cookiesDOWNLOAD_DELAY:每次request的时间间隔RETRY_ENABLED和RETRY_TIMES:是否请求失败重试及重试的次数HTTPERROR_ALLOWED_CODES:指定spider能处理的错误response(非200)返回值REDIRECT_ENABLED:对重定向返回的url不进行处理
2.3 运行爬虫
直接执行main.py即可运行爬虫