python爬取全站壁纸
python爬取全站壁纸
原由:电脑系统更新后原本电脑的壁纸全都丢失了,习惯不同时刻的壁纸画面,就想着批量下载点壁纸。于是就有了这个行为。
- 壁纸链接https://wallhaven.cc/
- 这里只列出个人梳理的思路——分享,学习
- 首先进入网站,获取图片的分类链接
- 进入分类链接,获取网页,这里需要F12查看下拉刷新时链接的变化,拼接请求参数即可获取完整的每一页的所有图片
- 此时,每一页中的所有图片的大小都不足以作为壁纸
- 继续进入每一个图片指向的链接,就能获取原图,进行下载保存
- 中间也尝试了其他的网站,貌似大致思路都是这样的。
资源库
主要用到两个
- requests网络请求
- lmxl html解析库
思路也有了,技术方案也有了,凎
import requests
from lxml import etree
import time
import random
import os
def get_header():
header={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'host': 'wallhaven.cc',
}
return header
def get_page_html():
url = "https://wallhaven.cc/"
response = requests.get(url=url, headers=get_header())
html = etree.HTML(response.text)
# 图片分类
categories = html.xpath('//div[@class="pop-tags"]/span/a/text()')[3:-1]
category_hrefs = html.xpath('//div[@class="pop-tags"]/span/a/@href')[3:-1]
for category, href in zip(categories, category_hrefs):
print("获取图片类别{},地址{}".format(category,href))
get_category_detail(category, href)
time.sleep(random.randint(2, 4))
def get_category_detail(category, href):
response = requests.get(href)
url = response.url
param = {
'page': '1'
}
for i in range(1, 5):
param['page'] = str(i)
res = requests.get(url=url, params=param)
html = etree.HTML(res.text)
# 每一页的图片指向的地址
images_page = html.xpath('//div[@id="thumbs"]/section/ul/li/figure/a/@href')
for image in images_page:
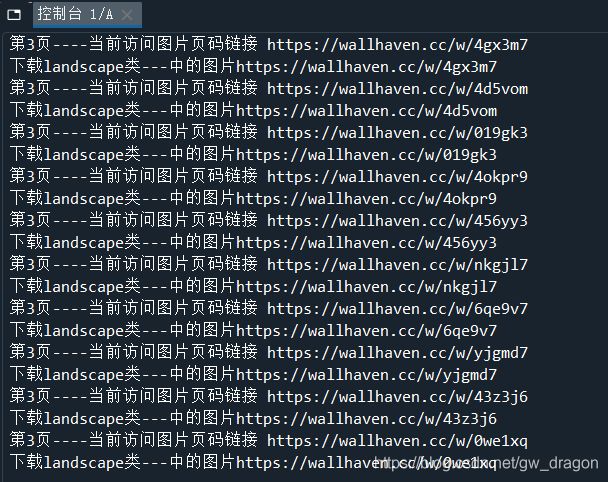
print("第{}页----当前访问图片页码链接 {}".format(i,image))
download_pic(category, image)
time.sleep(random.randint(1, 3))
def download_pic(category, url):
response = requests.get(url=url)
html = etree.HTML(response.text)
src = html.xpath('//main[@id="main"]/section/div/img/@src')[0]
print("下载{}类---中的图片{}".format(category, url))
# 创建文件夹
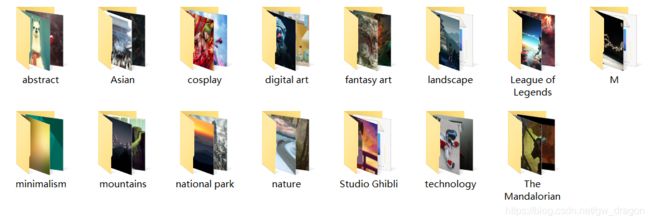
make_dir("wallhaven/{}".format(category))
with open('wallhaven/{}/{}'.format(category, src.split('/')[-1]), 'wb') as f:
f.write(requests.get(src).content)
def make_dir(name):
if not os.path.exists(name):
os.mkdir(name)
if __name__ == '__main__':
get_page_html()
潦草写下,随便搞搞,以满足需求。
建议:开启VPN好像下载的快很多