hive 报错return code 40000 from org.apache.hadoop.hive.ql.exec.MoveTask解决思路
参考学习
https://github.com/apache/hive/blob/2b57dd27ad61e552f93817ac69313066af6562d9/ql/src/java/org/apache/hadoop/hive/ql/ErrorMsg.java#L47
为啥学习error code
开发过程中遇到以下错误,大家觉得应该怎么办?从哪方面入手呢?
1.百度?
2.源码查看报错地方
3.忽略(这个错是偶发的)
Error: Error while compiling statement: FAILED: Execution Error, return code 40000 from org.apache.hadoop.hive.ql.exec.MoveTask. org.apache.hadoop.hive.ql.metadata.HiveException
at org.apache.hadoop.hive.ql.metadata.Hive.copyFiles(Hive.java:4792)
at org.apache.hadoop.hive.ql.metadata.Hive.loadTable(Hive.java:3180)
at org.apache.hadoop.hive.ql.exec.MoveTask.execute(MoveTask.java:412)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:213)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:105)
at org.apache.hadoop.hive.ql.Executor.launchTask(Executor.java:357)
at org.apache.hadoop.hive.ql.Executor.launchTasks(Executor.java:330)
at org.apache.hadoop.hive.ql.Executor.runTasks(Executor.java:246)
at org.apache.hadoop.hive.ql.Executor.execute(Executor.java:109)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:749)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:504)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:498)
at org.apache.hadoop.hive.ql.reexec.ReExecDriver.run(ReExecDriver.java:166)
at org.apache.hive.service.cli.operation.SQLOperation.runQuery(SQLOperation.java:226)
at org.apache.hive.service.cli.operation.SQLOperation.access$700(SQLOperation.java:88)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork$1.run(SQLOperation.java:327)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1898)
at org.apache.hive.service.cli.operation.SQLOperation$BackgroundWork.run(SQLOperation.java:345)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.run(FutureTask.java:266)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748) (state=08S01,code=40000)
但是这个错是hive的错,我们开发过程 中会遇到很多hive问题,都怎么解决呢?我建议看源码,但先不要看报错源码,直接看errorCode源码,别人hive的开发者也是人,也知道这里会报错,可能会好心告诉我们怎么解决。
// 10000 to 19999: Errors occurring during semantic analysis and compilation of the query.
// 20000 to 29999: Runtime errors where Hive believes that retries are unlikely to succeed.
// 30000 to 39999: Runtime errors which Hive thinks may be transient and retrying may succeed.
// 40000 to 49999: Errors where Hive is unable to advise about retries.
比如上面我们的措施40000,别人明确告诉我们 retries就行,实际情况就是重试确实ok。
但是还是想知道为什么报错,能不能有更好的解决办法。还是得看源码 哈哈哈。
以上述为例,因为我使用的集群是cdp3.1的hive版本

源码cdp肯定是不会给的,或者我不知道。那么直接看hive的源码,毕竟cdp也是抄的hive官方的代码。根据报错信息
at org.apache.hadoop.hive.ql.metadata.Hive.copyFiles(Hive.java:4792)
at org.apache.hadoop.hive.ql.metadata.Hive.loadTable(Hive.java:3180)
at org.apache.hadoop.hive.ql.exec.MoveTask.execute(MoveTask.java:412)
定位到
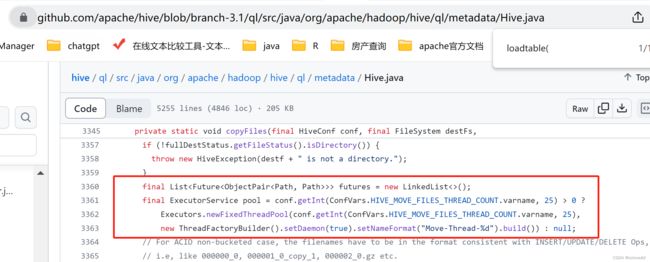
看到这里获取配置项,就舒服了,毕竟就算我们发现假设hive源码有问题,我也没法修改cdp的源码。但是配置有问题我们可以修改配置项。
HIVE_MOVE_FILES_THREAD_COUNT("hive.mv.files.thread", 15, new SizeValidator(0L, true, 1024L, true), "Number of threads"
+ " used to move files in move task. Set it to 0 to disable multi-threaded file moves. This parameter is also used by"
+ " MSCK to check tables."),
HIVE_LOAD_DYNAMIC_PARTITIONS_THREAD_COUNT("hive.load.dynamic.partitions.thread", 15,
new SizeValidator(1L, true, 1024L, true),
"Number of threads used to load dynamic partitions.")
顾名思义 这个配置项是move files的线程数,后面会根据这个线程数new一个线程池newFixedThreadPool
然后开始move file
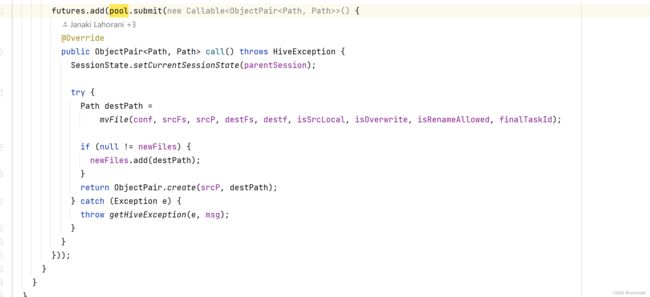
感受了 就是这里真正move的时候出错了。继续看mvFile干嘛。
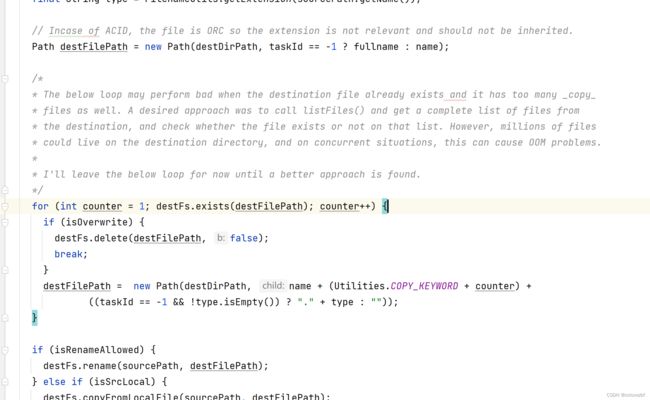
这里翻译下代码做了啥,和我们在干嘛。
我们做的是
insert into tableA select * from table1
insert into tableA select * from table2
比如说 table1中间有十个文件 table2也有10个文件 此时要把20个文件都mv到tableA目录下。此时默认开启了两个线程池各有15个线程。
以上代码逻辑是
从0开始命名 如果存在则+1
如果一个文件insert没有问题,但是此时有两个pool
pool1 发现没有0文件 pool2也发现没有0文件。
pool1 mv table1/0000 to tableA/0001
pool2 mv table2/0000 to tableA/0001
此时产生了冲突,这种在多线池情况下没法避免。。。所以hive保留这个bug,告诉我们就是重试吧。
那我们怎么解决呢?还记得上面的配置项吗?
1.设置线程数为1,线程数越少,产生bug的几率就越小 。
set hive.mv.files.thread=1
2.insert into 非分区表时 串行执行
3.改为分区表,此时不在一个目录了,就不会有这个问题了。
4.union 将多个操作合并为一个操作
居然这么多人点赞,我又想到一个问题,我举例的是非分区表,那么分区表会不会也出现这个问题呢?答案是可能的,和上面的案例同理,同时向一个分区插入数据也会报错,解决还是如上
1.设置线程数set hive.mv.files.thread=1
2.串行执行 多个插入同一个分区的操作
3.union 将多个操作合并为一个操作
如果帮到你,点个赞是对我最大的支持
附上hive的errorMsg
public enum ErrorMsg {
// The error codes are Hive-specific and partitioned into the following ranges:
// 10000 to 19999: Errors occurring during semantic analysis and compilation of the query.
// 20000 to 29999: Runtime errors where Hive believes that retries are unlikely to succeed.
// 30000 to 39999: Runtime errors which Hive thinks may be transient and retrying may succeed.
// 40000 to 49999: Errors where Hive is unable to advise about retries.
// In addition to the error code, ErrorMsg also has a SQLState field.
// SQLStates are taken from Section 22.1 of ISO-9075.
// See http://www.contrib.andrew.cmu.edu/~shadow/sql/sql1992.txt
// Most will just rollup to the generic syntax error state of 42000, but
// specific errors can override the that state.
// See this page for how MySQL uses SQLState codes:
// http://dev.mysql.com/doc/refman/5.0/en/connector-j-reference-error-sqlstates.html
GENERIC_ERROR(40000, "Exception while processing"),
//========================== 10000 range starts here ========================//
INVALID_TABLE(10001, "Table not found", "42S02"),
INVALID_COLUMN(10002, "Invalid column reference"),
INVALID_TABLE_OR_COLUMN(10004, "Invalid table alias or column reference"),
AMBIGUOUS_TABLE_OR_COLUMN(10005, "Ambiguous table alias or column reference"),
INVALID_PARTITION(10006, "Partition not found"),
AMBIGUOUS_COLUMN(10007, "Ambiguous column reference"),
AMBIGUOUS_TABLE_ALIAS(10008, "Ambiguous table alias"),
INVALID_TABLE_ALIAS(10009, "Invalid table alias"),
NO_TABLE_ALIAS(10010, "No table alias"),
INVALID_FUNCTION(10011, "Invalid function"),
INVALID_FUNCTION_SIGNATURE(10012, "Function argument type mismatch"),
INVALID_OPERATOR_SIGNATURE(10013, "Operator argument type mismatch"),
INVALID_ARGUMENT(10014, "Wrong arguments"),
INVALID_ARGUMENT_LENGTH(10015, "Arguments length mismatch", "21000"),
INVALID_ARGUMENT_TYPE(10016, "Argument type mismatch"),
@Deprecated INVALID_JOIN_CONDITION_1(10017, "Both left and right aliases encountered in JOIN"),
@Deprecated INVALID_JOIN_CONDITION_2(10018, "Neither left nor right aliases encountered in JOIN"),
@Deprecated INVALID_JOIN_CONDITION_3(10019, "OR not supported in JOIN currently"),
INVALID_TRANSFORM(10020, "TRANSFORM with other SELECT columns not supported"),
UNSUPPORTED_MULTIPLE_DISTINCTS(10022, "DISTINCT on different columns not supported" +
" with skew in data"),
NO_SUBQUERY_ALIAS(10023, "No alias for subquery"),
NO_INSERT_INSUBQUERY(10024, "Cannot insert in a subquery. Inserting to table "),
NON_KEY_EXPR_IN_GROUPBY(10025, "Expression not in GROUP BY key"),
INVALID_XPATH(10026, "General . and [] operators are not supported"),
INVALID_PATH(10027, "Invalid path"),
ILLEGAL_PATH(10028, "Path is not legal"),
INVALID_NUMERICAL_CONSTANT(10029, "Invalid numerical constant"),
INVALID_ARRAYINDEX_TYPE(10030,
"Not proper type for index of ARRAY. Currently, only integer type is supported"),
INVALID_MAPINDEX_CONSTANT(10031, "Non-constant expression for map indexes not supported"),
INVALID_MAPINDEX_TYPE(10032, "MAP key type does not match index expression type"),
NON_COLLECTION_TYPE(10033, "[] not valid on non-collection types"),
SELECT_DISTINCT_WITH_GROUPBY(10034, "SELECT DISTINCT and GROUP BY can not be in the same query"),
COLUMN_REPEATED_IN_PARTITIONING_COLS(10035, "Column repeated in partitioning columns"),
DUPLICATE_COLUMN_NAMES(10036, "Duplicate column name:"),
INVALID_BUCKET_NUMBER(10037, "Bucket number should be bigger than zero"),
COLUMN_REPEATED_IN_CLUSTER_SORT(10038, "Same column cannot appear in CLUSTER BY and SORT BY"),
SAMPLE_RESTRICTION(10039, "Cannot SAMPLE on more than two columns"),
SAMPLE_COLUMN_NOT_FOUND(10040, "SAMPLE column not found"),
NO_PARTITION_PREDICATE(10041, "No partition predicate found"),
INVALID_DOT(10042, ". Operator is only supported on struct or list of struct types"),
INVALID_TBL_DDL_SERDE(10043, "Either list of columns or a custom serializer should be specified"),
TARGET_TABLE_COLUMN_MISMATCH(10044,
"Cannot insert into target table because column number/types are different"),
TABLE_ALIAS_NOT_ALLOWED(10045, "Table alias not allowed in sampling clause"),
CLUSTERBY_DISTRIBUTEBY_CONFLICT(10046, "Cannot have both CLUSTER BY and DISTRIBUTE BY clauses"),
ORDERBY_DISTRIBUTEBY_CONFLICT(10047, "Cannot have both ORDER BY and DISTRIBUTE BY clauses"),
CLUSTERBY_SORTBY_CONFLICT(10048, "Cannot have both CLUSTER BY and SORT BY clauses"),
ORDERBY_SORTBY_CONFLICT(10049, "Cannot have both ORDER BY and SORT BY clauses"),
CLUSTERBY_ORDERBY_CONFLICT(10050, "Cannot have both CLUSTER BY and ORDER BY clauses"),
NO_LIMIT_WITH_ORDERBY(10051, "In strict mode, if ORDER BY is specified, "
+ "LIMIT must also be specified"),
UNION_NOTIN_SUBQ(10053, "Top level UNION is not supported currently; "
+ "use a subquery for the UNION"),
INVALID_INPUT_FORMAT_TYPE(10054, "Input format must implement InputFormat"),
INVALID_OUTPUT_FORMAT_TYPE(10055, "Output Format must implement HiveOutputFormat, "
+ "otherwise it should be either IgnoreKeyTextOutputFormat or SequenceFileOutputFormat"),
NO_VALID_PARTN(10056, HiveConf.StrictChecks.NO_PARTITIONLESS_MSG),
NO_OUTER_MAPJOIN(10057, "MAPJOIN cannot be performed with OUTER JOIN"),
INVALID_MAPJOIN_HINT(10058, "All tables are specified as map-table for join"),
INVALID_MAPJOIN_TABLE(10059, "Result of a union cannot be a map table"),
NON_BUCKETED_TABLE(10060, "Sampling expression needed for non-bucketed table"),
BUCKETED_NUMERATOR_BIGGER_DENOMINATOR(10061, "Numerator should not be bigger than "
+ "denominator in sample clause for table"),
NEED_PARTITION_ERROR(10062, "Need to specify partition columns because the destination "
+ "table is partitioned"),
CTAS_CTLT_COEXISTENCE(10063, "Create table command does not allow LIKE and AS-SELECT in "
+ "the same command"),
LINES_TERMINATED_BY_NON_NEWLINE(10064, "LINES TERMINATED BY only supports "
+ "newline '\\n' right now"),
CTAS_COLLST_COEXISTENCE(10065, "CREATE TABLE AS SELECT command cannot specify "
+ "the list of columns "
+ "for the target table"),
CTLT_COLLST_COEXISTENCE(10066, "CREATE TABLE LIKE command cannot specify the list of columns for "
+ "the target table"),
INVALID_SELECT_SCHEMA(10067, "Cannot derive schema from the select-clause"),
CTAS_PARCOL_COEXISTENCE(10068, "CREATE-TABLE-AS-SELECT does not support "
+ "partitioning in the target table "),
CTAS_MULTI_LOADFILE(10069, "CREATE-TABLE-AS-SELECT results in multiple file load"),
CTAS_EXTTBL_COEXISTENCE(10070, "CREATE-TABLE-AS-SELECT cannot create external table"),
INSERT_EXTERNAL_TABLE(10071, "Inserting into a external table is not allowed"),
DATABASE_NOT_EXISTS(10072, "Database does not exist:"),
TABLE_ALREADY_EXISTS(10073, "Table already exists:", "42S02"),
COLUMN_ALIAS_ALREADY_EXISTS(10074, "Column alias already exists:", "42S02"),
UDTF_MULTIPLE_EXPR(10075, "Only a single expression in the SELECT clause is "
+ "supported with UDTF's"),
@Deprecated UDTF_REQUIRE_AS(10076, "UDTF's require an AS clause"),
UDTF_NO_GROUP_BY(10077, "GROUP BY is not supported with a UDTF in the SELECT clause"),
UDTF_NO_SORT_BY(10078, "SORT BY is not supported with a UDTF in the SELECT clause"),
UDTF_NO_CLUSTER_BY(10079, "CLUSTER BY is not supported with a UDTF in the SELECT clause"),
UDTF_NO_DISTRIBUTE_BY(10080, "DISTRUBTE BY is not supported with a UDTF in the SELECT clause"),
UDTF_INVALID_LOCATION(10081, "UDTF's are not supported outside the SELECT clause, nor nested "
+ "in expressions"),
UDTF_LATERAL_VIEW(10082, "UDTF's cannot be in a select expression when there is a lateral view"),
UDTF_ALIAS_MISMATCH(10083, "The number of aliases supplied in the AS clause does not match the "
+ "number of columns output by the UDTF"),
UDF_STATEFUL_INVALID_LOCATION(10084, "Stateful UDF's can only be invoked in the SELECT list"),
LATERAL_VIEW_WITH_JOIN(10085, "JOIN with a LATERAL VIEW is not supported"),
LATERAL_VIEW_INVALID_CHILD(10086, "LATERAL VIEW AST with invalid child"),
OUTPUT_SPECIFIED_MULTIPLE_TIMES(10087, "The same output cannot be present multiple times: "),
INVALID_AS(10088, "AS clause has an invalid number of aliases"),
VIEW_COL_MISMATCH(10089, "The number of columns produced by the SELECT clause does not match the "
+ "number of column names specified by CREATE VIEW"),
DML_AGAINST_VIEW(10090, "A view cannot be used as target table for LOAD or INSERT"),
ANALYZE_VIEW(10091, "ANALYZE is not supported for views"),
VIEW_PARTITION_TOTAL(10092, "At least one non-partitioning column must be present in view"),
VIEW_PARTITION_MISMATCH(10093, "Rightmost columns in view output do not match "
+ "PARTITIONED ON clause"),
PARTITION_DYN_STA_ORDER(10094, "Dynamic partition cannot be the parent of a static partition"),
DYNAMIC_PARTITION_DISABLED(10095, "Dynamic partition is disabled. Either enable it by setting "
+ "hive.exec.dynamic.partition=true or specify partition column values"),
DYNAMIC_PARTITION_STRICT_MODE(10096, "Dynamic partition strict mode requires at least one "
+ "static partition column. To turn this off set hive.exec.dynamic.partition.mode=nonstrict"),
NONEXISTPARTCOL(10098, "Non-Partition column appears in the partition specification: "),
UNSUPPORTED_TYPE(10099, "DATETIME type isn't supported yet. Please use "
+ "DATE or TIMESTAMP instead"),
CREATE_NON_NATIVE_AS(10100, "CREATE TABLE AS SELECT cannot be used for a non-native table"),
LOAD_INTO_NON_NATIVE(10101, "A non-native table cannot be used as target for LOAD"),
LOCKMGR_NOT_SPECIFIED(10102, "Lock manager not specified correctly, set hive.lock.manager"),
LOCKMGR_NOT_INITIALIZED(10103, "Lock manager could not be initialized, check hive.lock.manager "),
LOCK_CANNOT_BE_ACQUIRED(10104, "Locks on the underlying objects cannot be acquired. "
+ "retry after some time"),
ZOOKEEPER_CLIENT_COULD_NOT_BE_INITIALIZED(10105, "Check hive.zookeeper.quorum "
+ "and hive.zookeeper.client.port"),
OVERWRITE_ARCHIVED_PART(10106, "Cannot overwrite an archived partition. " +
"Unarchive before running this command"),
ARCHIVE_METHODS_DISABLED(10107, "Archiving methods are currently disabled. " +
"Please see the Hive wiki for more information about enabling archiving"),
ARCHIVE_ON_MULI_PARTS(10108, "ARCHIVE can only be run on a single partition"),
UNARCHIVE_ON_MULI_PARTS(10109, "ARCHIVE can only be run on a single partition"),
ARCHIVE_ON_TABLE(10110, "ARCHIVE can only be run on partitions"),
RESERVED_PART_VAL(10111, "Partition value contains a reserved substring"),
OFFLINE_TABLE_OR_PARTITION(10113, "Query against an offline table or partition"),
NEED_PARTITION_SPECIFICATION(10115, "Table is partitioned and partition specification is needed"),
INVALID_METADATA(10116, "The metadata file could not be parsed "),
NEED_TABLE_SPECIFICATION(10117, "Table name could be determined; It should be specified "),
PARTITION_EXISTS(10118, "Partition already exists"),
TABLE_DATA_EXISTS(10119, "Table exists and contains data files"),
INCOMPATIBLE_SCHEMA(10120, "The existing table is not compatible with the import spec. "),
EXIM_FOR_NON_NATIVE(10121, "Export/Import cannot be done for a non-native table. "),
INSERT_INTO_BUCKETIZED_TABLE(10122, "Bucketized tables do not support INSERT INTO:"),
PARTSPEC_DIFFER_FROM_SCHEMA(10125, "Partition columns in partition specification are "
+ "not the same as that defined in the table schema. "
+ "The names and orders have to be exactly the same."),
PARTITION_COLUMN_NON_PRIMITIVE(10126, "Partition column must be of primitive type."),
INSERT_INTO_DYNAMICPARTITION_IFNOTEXISTS(10127,
"Dynamic partitions do not support IF NOT EXISTS. Specified partitions with value :"),
UDAF_INVALID_LOCATION(10128, "Not yet supported place for UDAF"),
DROP_PARTITION_NON_STRING_PARTCOLS_NONEQUALITY(10129,
"Drop partitions for a non-string partition column is only allowed using equality"),
ALTER_COMMAND_FOR_VIEWS(10131, "To alter a view you need to use the ALTER VIEW command."),
ALTER_COMMAND_FOR_TABLES(10132, "To alter a base table you need to use the ALTER TABLE command."),
ALTER_VIEW_DISALLOWED_OP(10133, "Cannot use this form of ALTER on a view"),
ALTER_TABLE_NON_NATIVE(10134, "ALTER TABLE can only be used for " + AlterTableTypes.nonNativeTableAllowedTypes + " to a non-native table "),
SORTMERGE_MAPJOIN_FAILED(10135,
"Sort merge bucketed join could not be performed. " +
"If you really want to perform the operation, either set " +
"hive.optimize.bucketmapjoin.sortedmerge=false, or set " +
"hive.enforce.sortmergebucketmapjoin=false."),
BUCKET_MAPJOIN_NOT_POSSIBLE(10136,
"Bucketed mapjoin cannot be performed. " +
"This can be due to multiple reasons: " +
" . Join columns dont match bucketed columns. " +
" . Number of buckets are not a multiple of each other. " +
"If you really want to perform the operation, either remove the " +
"mapjoin hint from your query or set hive.enforce.bucketmapjoin to false."),
BUCKETED_TABLE_METADATA_INCORRECT(10141,
"Bucketed table metadata is not correct. " +
"Fix the metadata or don't use bucketed mapjoin, by setting " +
"hive.enforce.bucketmapjoin to false."),
JOINNODE_OUTERJOIN_MORETHAN_16(10142, "Single join node containing outer join(s) " +
"cannot have more than 16 aliases"),
INVALID_JDO_FILTER_EXPRESSION(10143, "Invalid expression for JDO filter"),
ALTER_BUCKETNUM_NONBUCKETIZED_TBL(10145, "Table is not bucketized."),
TRUNCATE_FOR_NON_MANAGED_TABLE(10146, "Cannot truncate non-managed table {0}.", true),
TRUNCATE_FOR_NON_NATIVE_TABLE(10147, "Cannot truncate non-native table {0}.", true),
PARTSPEC_FOR_NON_PARTITIONED_TABLE(10148, "Partition spec for non partitioned table {0}.", true),
INVALID_TABLE_IN_ON_CLAUSE_OF_MERGE(10149, "No columns from target table ''{0}'' found in ON " +
"clause ''{1}'' of MERGE statement.", true),
LOAD_INTO_STORED_AS_DIR(10195, "A stored-as-directories table cannot be used as target for LOAD"),
ALTER_TBL_STOREDASDIR_NOT_SKEWED(10196, "This operation is only valid on skewed table."),
ALTER_TBL_SKEWED_LOC_NO_LOC(10197, "Alter table skewed location doesn't have locations."),
ALTER_TBL_SKEWED_LOC_NO_MAP(10198, "Alter table skewed location doesn't have location map."),
SKEWED_TABLE_NO_COLUMN_NAME(10200, "No skewed column name."),
SKEWED_TABLE_NO_COLUMN_VALUE(10201, "No skewed values."),
SKEWED_TABLE_DUPLICATE_COLUMN_NAMES(10202,
"Duplicate skewed column name:"),
SKEWED_TABLE_INVALID_COLUMN(10203,
"Invalid skewed column name:"),
SKEWED_TABLE_SKEWED_COL_NAME_VALUE_MISMATCH_1(10204,
"Skewed column name is empty but skewed value is not."),
SKEWED_TABLE_SKEWED_COL_NAME_VALUE_MISMATCH_2(10205,
"Skewed column value is empty but skewed name is not."),
SKEWED_TABLE_SKEWED_COL_NAME_VALUE_MISMATCH_3(10206,
"The number of skewed column names and the number of " +
"skewed column values are different: "),
ALTER_TABLE_NOT_ALLOWED_RENAME_SKEWED_COLUMN(10207,
" is a skewed column. It's not allowed to rename skewed column"
+ " or change skewed column type."),
HIVE_GROUPING_SETS_AGGR_NOMAPAGGR(10209,
"Grouping sets aggregations (with rollups or cubes) are not allowed if map-side " +
" aggregation is turned off. Set hive.map.aggr=true if you want to use grouping sets"),
HIVE_GROUPING_SETS_AGGR_EXPRESSION_INVALID(10210,
"Grouping sets aggregations (with rollups or cubes) are not allowed if aggregation function " +
"parameters overlap with the aggregation functions columns"),
HIVE_GROUPING_SETS_EMPTY(10211,
"Empty grouping sets not allowed"),
HIVE_UNION_REMOVE_OPTIMIZATION_NEEDS_SUBDIRECTORIES(10212,
"In order to use hive.optimize.union.remove, the hadoop version that you are using " +
"should support sub-directories for tables/partitions. If that is true, set " +
"hive.hadoop.supports.subdirectories to true. Otherwise, set hive.optimize.union.remove " +
"to false"),
HIVE_GROUPING_SETS_EXPR_NOT_IN_GROUPBY(10213,
"Grouping sets expression is not in GROUP BY key"),
INVALID_PARTITION_SPEC(10214, "Invalid partition spec specified"),
ALTER_TBL_UNSET_NON_EXIST_PROPERTY(10215,
"Please use the following syntax if not sure " +
"whether the property existed or not:\n" +
"ALTER TABLE tableName UNSET TBLPROPERTIES IF EXISTS (key1, key2, ...)\n"),
ALTER_VIEW_AS_SELECT_NOT_EXIST(10216,
"Cannot ALTER VIEW AS SELECT if view currently does not exist\n"),
REPLACE_VIEW_WITH_PARTITION(10217,
"Cannot replace a view with CREATE VIEW or REPLACE VIEW or " +
"ALTER VIEW AS SELECT if the view has partitions\n"),
EXISTING_TABLE_IS_NOT_VIEW(10218,
"Existing table is not a view\n"),
NO_SUPPORTED_ORDERBY_ALLCOLREF_POS(10219,
"Position in ORDER BY is not supported when using SELECT *"),
INVALID_POSITION_ALIAS_IN_GROUPBY(10220,
"Invalid position alias in Group By\n"),
INVALID_POSITION_ALIAS_IN_ORDERBY(10221,
"Invalid position alias in Order By\n"),
HIVE_GROUPING_SETS_THRESHOLD_NOT_ALLOWED_WITH_SKEW(10225,
"An additional MR job is introduced since the number of rows created per input row " +
"due to grouping sets is more than hive.new.job.grouping.set.cardinality. There is no need " +
"to handle skew separately. set hive.groupby.skewindata to false."),
HIVE_GROUPING_SETS_THRESHOLD_NOT_ALLOWED_WITH_DISTINCTS(10226,
"An additional MR job is introduced since the cardinality of grouping sets " +
"is more than hive.new.job.grouping.set.cardinality. This functionality is not supported " +
"with distincts. Either set hive.new.job.grouping.set.cardinality to a high number " +
"(higher than the number of rows per input row due to grouping sets in the query), or " +
"rewrite the query to not use distincts."),
OPERATOR_NOT_ALLOWED_WITH_MAPJOIN(10227,
"Not all clauses are supported with mapjoin hint. Please remove mapjoin hint."),
ANALYZE_TABLE_NOSCAN_NON_NATIVE(10228, "ANALYZE TABLE NOSCAN cannot be used for " + "a non-native table"),
PARTITION_VALUE_NOT_CONTINUOUS(10234, "Partition values specified are not continuous." +
" A subpartition value is specified without specifying the parent partition's value"),
TABLES_INCOMPATIBLE_SCHEMAS(10235, "Tables have incompatible schemas and their partitions " +
" cannot be exchanged."),
EXCHANGE_PARTITION_NOT_ALLOWED_WITH_TRANSACTIONAL_TABLES(10236, "Exchange partition is not allowed with "
+ "transactional tables. Alternatively, shall use load data or insert overwrite to move partitions."),
TRUNCATE_COLUMN_NOT_RC(10237, "Only RCFileFormat supports column truncation."),
TRUNCATE_COLUMN_ARCHIVED(10238, "Column truncation cannot be performed on archived partitions."),
TRUNCATE_BUCKETED_COLUMN(10239,
"A column on which a partition/table is bucketed cannot be truncated."),
TRUNCATE_LIST_BUCKETED_COLUMN(10240,
"A column on which a partition/table is list bucketed cannot be truncated."),
TABLE_NOT_PARTITIONED(10241, "Table {0} is not a partitioned table", true),
DATABSAE_ALREADY_EXISTS(10242, "Database {0} already exists", true),
CANNOT_REPLACE_COLUMNS(10243, "Replace columns is not supported for table {0}. SerDe may be incompatible.", true),
BAD_LOCATION_VALUE(10244, "{0} is not absolute. Please specify a complete absolute uri."),
UNSUPPORTED_ALTER_TBL_OP(10245, "{0} alter table options is not supported"),
INVALID_BIGTABLE_MAPJOIN(10246, "{0} table chosen for streaming is not valid", true),
MISSING_OVER_CLAUSE(10247, "Missing over clause for function : "),
PARTITION_SPEC_TYPE_MISMATCH(10248, "Cannot add partition column {0} of type {1} as it cannot be converted to type {2}", true),
UNSUPPORTED_SUBQUERY_EXPRESSION(10249, "Unsupported SubQuery Expression"),
INVALID_SUBQUERY_EXPRESSION(10250, "Invalid SubQuery expression"),
INVALID_HDFS_URI(10251, "{0} is not a hdfs uri", true),
INVALID_DIR(10252, "{0} is not a directory", true),
NO_VALID_LOCATIONS(10253, "Could not find any valid location to place the jars. " +
"Please update hive.jar.directory or hive.user.install.directory with a valid location", false),
UNSUPPORTED_AUTHORIZATION_PRINCIPAL_TYPE_GROUP(10254,
"Principal type GROUP is not supported in this authorization setting", "28000"),
INVALID_TABLE_NAME(10255, "Invalid table name {0}", true),
INSERT_INTO_IMMUTABLE_TABLE(10256, "Inserting into a non-empty immutable table is not allowed"),
UNSUPPORTED_AUTHORIZATION_RESOURCE_TYPE_GLOBAL(10257,
"Resource type GLOBAL is not supported in this authorization setting", "28000"),
UNSUPPORTED_AUTHORIZATION_RESOURCE_TYPE_COLUMN(10258,
"Resource type COLUMN is not supported in this authorization setting", "28000"),
TXNMGR_NOT_SPECIFIED(10260, "Transaction manager not specified correctly, " +
"set hive.txn.manager"),
TXNMGR_NOT_INSTANTIATED(10261, "Transaction manager could not be " +
"instantiated, check hive.txn.manager"),
TXN_NO_SUCH_TRANSACTION(10262, "No record of transaction {0} could be found, " +
"may have timed out", true),
TXN_ABORTED(10263, "Transaction manager has aborted the transaction {0}. Reason: {1}", true),
DBTXNMGR_REQUIRES_CONCURRENCY(10264,
"To use DbTxnManager you must set hive.support.concurrency=true"),
TXNMGR_NOT_ACID(10265, "This command is not allowed on an ACID table {0}.{1} with a non-ACID transaction manager", true),
LOCK_NO_SUCH_LOCK(10270, "No record of lock {0} could be found, " +
"may have timed out", true),
LOCK_REQUEST_UNSUPPORTED(10271, "Current transaction manager does not " +
"support explicit lock requests. Transaction manager: "),
METASTORE_COMMUNICATION_FAILED(10280, "Error communicating with the " +
"metastore"),
METASTORE_COULD_NOT_INITIATE(10281, "Unable to initiate connection to the " +
"metastore."),
INVALID_COMPACTION_TYPE(10282, "Invalid compaction type, supported values are 'major' and " +
"'minor'"),
NO_COMPACTION_PARTITION(10283, "You must specify a partition to compact for partitioned tables"),
TOO_MANY_COMPACTION_PARTITIONS(10284, "Compaction can only be requested on one partition at a " +
"time."),
DISTINCT_NOT_SUPPORTED(10285, "Distinct keyword is not support in current context"),
NONACID_COMPACTION_NOT_SUPPORTED(10286, "Compaction is not allowed on non-ACID table {0}.{1}", true),
MASKING_FILTERING_ON_ACID_NOT_SUPPORTED(10287,
"Detected {0}.{1} has row masking/column filtering enabled, " +
"which is not supported for query involving ACID operations", true),
UPDATEDELETE_PARSE_ERROR(10290, "Encountered parse error while parsing rewritten merge/update or " +
"delete query"),
UPDATEDELETE_IO_ERROR(10291, "Encountered I/O error while parsing rewritten update or " +
"delete query"),
UPDATE_CANNOT_UPDATE_PART_VALUE(10292, "Updating values of partition columns is not supported"),
INSERT_CANNOT_CREATE_TEMP_FILE(10293, "Unable to create temp file for insert values "),
ACID_OP_ON_NONACID_TXNMGR(10294, "Attempt to do update or delete using transaction manager that" +
" does not support these operations."),
VALUES_TABLE_CONSTRUCTOR_NOT_SUPPORTED(10296,
"Values clause with table constructor not yet supported"),
ACID_OP_ON_NONACID_TABLE(10297, "Attempt to do update or delete on table {0} that is " +
"not transactional", true),
ACID_NO_SORTED_BUCKETS(10298, "ACID insert, update, delete not supported on tables that are " +
"sorted, table {0}", true),
ALTER_TABLE_TYPE_PARTIAL_PARTITION_SPEC_NO_SUPPORTED(10299,
"Alter table partition type {0} does not allow partial partition spec", true),
ALTER_TABLE_PARTITION_CASCADE_NOT_SUPPORTED(10300,
"Alter table partition type {0} does not support cascade", true),
DROP_NATIVE_FUNCTION(10301, "Cannot drop native function"),
UPDATE_CANNOT_UPDATE_BUCKET_VALUE(10302, "Updating values of bucketing columns is not supported. Column {0}.", true),
IMPORT_INTO_STRICT_REPL_TABLE(10303,"Non-repl import disallowed against table that is a destination of replication."),
CTAS_LOCATION_NONEMPTY(10304, "CREATE-TABLE-AS-SELECT cannot create table with location to a non-empty directory."),
CTAS_CREATES_VOID_TYPE(10305, "CREATE-TABLE-AS-SELECT creates a VOID type, please use CAST to specify the type, near field: "),
TBL_SORTED_NOT_BUCKETED(10306, "Destination table {0} found to be sorted but not bucketed.", true),
//{2} should be lockid
LOCK_ACQUIRE_TIMEDOUT(10307, "Lock acquisition for {0} timed out after {1}ms. {2}", true),
COMPILE_LOCK_TIMED_OUT(10308, "Attempt to acquire compile lock timed out.", true),
CANNOT_CHANGE_SERDE(10309, "Changing SerDe (from {0}) is not supported for table {1}. File format may be incompatible", true),
CANNOT_CHANGE_FILEFORMAT(10310, "Changing file format (from {0}) is not supported for table {1}", true),
CANNOT_REORDER_COLUMNS(10311, "Reordering columns is not supported for table {0}. SerDe may be incompatible", true),
CANNOT_CHANGE_COLUMN_TYPE(10312, "Changing from type {0} to {1} is not supported for column {2}. SerDe may be incompatible", true),
REPLACE_CANNOT_DROP_COLUMNS(10313, "Replacing columns cannot drop columns for table {0}. SerDe may be incompatible", true),
REPLACE_UNSUPPORTED_TYPE_CONVERSION(10314, "Replacing columns with unsupported type conversion (from {0} to {1}) for column {2}. SerDe may be incompatible", true),
HIVE_GROUPING_SETS_AGGR_NOMAPAGGR_MULTIGBY(10315,
"Grouping sets aggregations (with rollups or cubes) are not allowed when " +
"HIVEMULTIGROUPBYSINGLEREDUCER is turned on. Set hive.multigroupby.singlereducer=false if you want to use grouping sets"),
CANNOT_RETRIEVE_TABLE_METADATA(10316, "Error while retrieving table metadata"),
INVALID_AST_TREE(10318, "Internal error : Invalid AST"),
ERROR_SERIALIZE_METASTORE(10319, "Error while serializing the metastore objects"),
IO_ERROR(10320, "Error while performing IO operation "),
ERROR_SERIALIZE_METADATA(10321, "Error while serializing the metadata"),
INVALID_LOAD_TABLE_FILE_WORK(10322, "Invalid Load Table Work or Load File Work"),
CLASSPATH_ERROR(10323, "Classpath error"),
IMPORT_SEMANTIC_ERROR(10324, "Import Semantic Analyzer Error"),
INVALID_FK_SYNTAX(10325, "Invalid Foreign Key syntax"),
INVALID_CSTR_SYNTAX(10326, "Invalid Constraint syntax"),
ACID_NOT_ENOUGH_HISTORY(10327, "Not enough history available for ({0},{1}). " +
"Oldest available base: {2}", true),
INVALID_COLUMN_NAME(10328, "Invalid column name"),
UNSUPPORTED_SET_OPERATOR(10329, "Unsupported set operator"),
LOCK_ACQUIRE_CANCELLED(10330, "Query was cancelled while acquiring locks on the underlying objects. "),
NOT_RECOGNIZED_CONSTRAINT(10331, "Constraint not recognized"),
INVALID_CONSTRAINT(10332, "Invalid constraint definition"),
REPLACE_VIEW_WITH_MATERIALIZED(10400, "Attempt to replace view {0} with materialized view", true),
REPLACE_MATERIALIZED_WITH_VIEW(10401, "Attempt to replace materialized view {0} with view", true),
UPDATE_DELETE_VIEW(10402, "You cannot update or delete records in a view"),
MATERIALIZED_VIEW_DEF_EMPTY(10403, "Query for the materialized view rebuild could not be retrieved"),
MERGE_PREDIACTE_REQUIRED(10404, "MERGE statement with both UPDATE and DELETE clauses " +
"requires \"AND \" on the 1st WHEN MATCHED clause of <{0}>" , true),
MERGE_TOO_MANY_DELETE(10405, "MERGE statment can have at most 1 WHEN MATCHED ... DELETE clause: <{0}>", true),
MERGE_TOO_MANY_UPDATE(10406, "MERGE statment can have at most 1 WHEN MATCHED ... UPDATE clause: <{0}>", true),
INVALID_JOIN_CONDITION(10407, "Error parsing condition in join"),
INVALID_TARGET_COLUMN_IN_SET_CLAUSE(10408, "Target column \"{0}\" of set clause is not found in table \"{1}\".", true),
HIVE_GROUPING_FUNCTION_EXPR_NOT_IN_GROUPBY(10409, "Expression in GROUPING function not present in GROUP BY"),
ALTER_TABLE_NON_PARTITIONED_TABLE_CASCADE_NOT_SUPPORTED(10410,
"Alter table with non-partitioned table does not support cascade"),
HIVE_GROUPING_SETS_SIZE_LIMIT(10411,
"Grouping sets size cannot be greater than 64"),
REBUILD_NO_MATERIALIZED_VIEW(10412, "Rebuild command only valid for materialized views"),
LOAD_DATA_ACID_FILE(10413,
"\"{0}\" was created created by Acid write - it cannot be loaded into anther Acid table",
true),
ACID_OP_ON_INSERTONLYTRAN_TABLE(10414, "Attempt to do update or delete on table {0} that is " +
"insert-only transactional", true),
LOAD_DATA_LAUNCH_JOB_IO_ERROR(10415, "Encountered I/O error while parsing rewritten load data into insert query"),
LOAD_DATA_LAUNCH_JOB_PARSE_ERROR(10416, "Encountered parse error while parsing rewritten load data into insert query"),
//========================== 20000 range starts here ========================//
SCRIPT_INIT_ERROR(20000, "Unable to initialize custom script."),
SCRIPT_IO_ERROR(20001, "An error occurred while reading or writing to your custom script. "
+ "It may have crashed with an error."),
SCRIPT_GENERIC_ERROR(20002, "Hive encountered some unknown error while "
+ "running your custom script."),
SCRIPT_CLOSING_ERROR(20003, "An error occurred when trying to close the Operator " +
"running your custom script."),
DYNAMIC_PARTITIONS_TOO_MANY_PER_NODE_ERROR(20004, "Fatal error occurred when node " +
"tried to create too many dynamic partitions. The maximum number of dynamic partitions " +
"is controlled by hive.exec.max.dynamic.partitions and hive.exec.max.dynamic.partitions.pernode. "),
/**
* {1} is the transaction id;
* use {@link org.apache.hadoop.hive.common.JavaUtils#txnIdToString(long)} to format
*/
OP_NOT_ALLOWED_IN_IMPLICIT_TXN(20006, "Operation {0} is not allowed in an implicit transaction ({1}).", true),
/**
* {1} is the transaction id;
* use {@link org.apache.hadoop.hive.common.JavaUtils#txnIdToString(long)} to format
*/
OP_NOT_ALLOWED_IN_TXN(20007, "Operation {0} is not allowed in a transaction ({1},queryId={2}).", true),
OP_NOT_ALLOWED_WITHOUT_TXN(20008, "Operation {0} is not allowed without an active transaction", true),
ACCESS_DENIED(20009, "Access denied: {0}", "42000", true),
QUOTA_EXCEEDED(20010, "Quota exceeded: {0}", "64000", true),
UNRESOLVED_PATH(20011, "Unresolved path: {0}", "64000", true),
FILE_NOT_FOUND(20012, "File not found: {0}", "64000", true),
WRONG_FILE_FORMAT(20013, "Wrong file format. Please check the file's format.", "64000", true),
SPARK_CREATE_CLIENT_INVALID_QUEUE(20014, "Spark job is submitted to an invalid queue: {0}."
+ " Please fix and try again.", true),
SPARK_RUNTIME_OOM(20015, "Spark job failed because of out of memory."),
//if the error message is changed for REPL_EVENTS_MISSING_IN_METASTORE, then need modification in getNextNotification
//method in HiveMetaStoreClient
REPL_EVENTS_MISSING_IN_METASTORE(20016, "Notification events are missing in the meta store."),
REPL_BOOTSTRAP_LOAD_PATH_NOT_VALID(20017, "Target database is bootstrapped from some other path."),
REPL_FILE_MISSING_FROM_SRC_AND_CM_PATH(20018, "File is missing from both source and cm path."),
REPL_LOAD_PATH_NOT_FOUND(20019, "Load path does not exist."),
REPL_DATABASE_IS_NOT_SOURCE_OF_REPLICATION(20020,
"Source of replication (repl.source.for) is not set in the database properties."),
// An exception from runtime that will show the full stack to client
UNRESOLVED_RT_EXCEPTION(29999, "Runtime Error: {0}", "58004", true),
//========================== 30000 range starts here ========================//
STATSPUBLISHER_NOT_OBTAINED(30000, "StatsPublisher cannot be obtained. " +
"There was a error to retrieve the StatsPublisher, and retrying " +
"might help. If you dont want the query to fail because accurate statistics " +
"could not be collected, set hive.stats.reliable=false"),
STATSPUBLISHER_INITIALIZATION_ERROR(30001, "StatsPublisher cannot be initialized. " +
"There was a error in the initialization of StatsPublisher, and retrying " +
"might help. If you dont want the query to fail because accurate statistics " +
"could not be collected, set hive.stats.reliable=false"),
STATSPUBLISHER_CONNECTION_ERROR(30002, "StatsPublisher cannot be connected to." +
"There was a error while connecting to the StatsPublisher, and retrying " +
"might help. If you dont want the query to fail because accurate statistics " +
"could not be collected, set hive.stats.reliable=false"),
STATSPUBLISHER_PUBLISHING_ERROR(30003, "Error in publishing stats. There was an " +
"error in publishing stats via StatsPublisher, and retrying " +
"might help. If you dont want the query to fail because accurate statistics " +
"could not be collected, set hive.stats.reliable=false"),
STATSPUBLISHER_CLOSING_ERROR(30004, "StatsPublisher cannot be closed." +
"There was a error while closing the StatsPublisher, and retrying " +
"might help. If you dont want the query to fail because accurate statistics " +
"could not be collected, set hive.stats.reliable=false"),
COLUMNSTATSCOLLECTOR_INVALID_PART_KEY(30005, "Invalid partitioning key specified in ANALYZE " +
"statement"),
COLUMNSTATSCOLLECTOR_INVALID_PARTITION(30007, "Invalid partitioning key/value specified in " +
"ANALYZE statement"),
COLUMNSTATSCOLLECTOR_PARSE_ERROR(30009, "Encountered parse error while parsing rewritten query"),
COLUMNSTATSCOLLECTOR_IO_ERROR(30010, "Encountered I/O exception while parsing rewritten query"),
DROP_COMMAND_NOT_ALLOWED_FOR_PARTITION(30011, "Partition protected from being dropped"),
COLUMNSTATSCOLLECTOR_INVALID_COLUMN(30012, "Column statistics are not supported "
+ "for partition columns"),
STATSAGGREGATOR_SOURCETASK_NULL(30014, "SourceTask of StatsTask should not be null"),
STATSAGGREGATOR_CONNECTION_ERROR(30015,
"Stats aggregator of type {0} cannot be connected to", true),
STATS_SKIPPING_BY_ERROR(30017, "Skipping stats aggregation by error {0}", true),
INVALID_FILE_FORMAT_IN_LOAD(30019, "The file that you are trying to load does not match the" +
" file format of the destination table."),
SCHEMA_REQUIRED_TO_READ_ACID_TABLES(30020, "Neither the configuration variables " +
"schema.evolution.columns / schema.evolution.columns.types " +
"nor the " +
"columns / columns.types " +
"are set. Table schema information is required to read ACID tables"),
ACID_TABLES_MUST_BE_READ_WITH_ACID_READER(30021, "An ORC ACID reader required to read ACID tables"),
ACID_TABLES_MUST_BE_READ_WITH_HIVEINPUTFORMAT(30022, "Must use HiveInputFormat to read ACID tables " +
"(set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat)"),
ACID_LOAD_DATA_INVALID_FILE_NAME(30023, "{0} file name is not valid in Load Data into Acid " +
"table {1}. Examples of valid names are: 00000_0, 00000_0_copy_1", true),
CONCATENATE_UNSUPPORTED_FILE_FORMAT(30030, "Concatenate/Merge only supported for RCFile and ORCFile formats"),
CONCATENATE_UNSUPPORTED_TABLE_BUCKETED(30031, "Concatenate/Merge can not be performed on bucketed tables"),
CONCATENATE_UNSUPPORTED_PARTITION_ARCHIVED(30032, "Concatenate/Merge can not be performed on archived partitions"),
CONCATENATE_UNSUPPORTED_TABLE_NON_NATIVE(30033, "Concatenate/Merge can not be performed on non-native tables"),
CONCATENATE_UNSUPPORTED_TABLE_NOT_MANAGED(30034, "Concatenate/Merge can only be performed on managed tables"),
CONCATENATE_UNSUPPORTED_TABLE_TRANSACTIONAL(30035,
"Concatenate/Merge can not be performed on transactional tables"),
SPARK_GET_JOB_INFO_TIMEOUT(30036,
"Spark job timed out after {0} seconds while getting job info", true),
SPARK_JOB_MONITOR_TIMEOUT(30037, "Job hasn''t been submitted after {0}s." +
" Aborting it.\nPossible reasons include network issues, " +
"errors in remote driver or the cluster has no available resources, etc.\n" +
"Please check YARN or Spark driver''s logs for further information.\n" +
"The timeout is controlled by " + HiveConf.ConfVars.SPARK_JOB_MONITOR_TIMEOUT + ".", true),
// Various errors when creating Spark client
SPARK_CREATE_CLIENT_TIMEOUT(30038,
"Timed out while creating Spark client for session {0}.", true),
SPARK_CREATE_CLIENT_QUEUE_FULL(30039,
"Failed to create Spark client because job queue is full: {0}.", true),
SPARK_CREATE_CLIENT_INTERRUPTED(30040,
"Interrupted while creating Spark client for session {0}", true),
SPARK_CREATE_CLIENT_ERROR(30041,
"Failed to create Spark client for Spark session {0}", true),
SPARK_CREATE_CLIENT_INVALID_RESOURCE_REQUEST(30042,
"Failed to create Spark client due to invalid resource request: {0}", true),
SPARK_CREATE_CLIENT_CLOSED_SESSION(30043,
"Cannot create Spark client on a closed session {0}", true),
SPARK_JOB_INTERRUPTED(30044, "Spark job was interrupted while executing"),
REPL_FILE_SYSTEM_OPERATION_RETRY(30045, "Replication file system operation retry expired."),
//========================== 40000 range starts here ========================//
SPARK_JOB_RUNTIME_ERROR(40001,
"Spark job failed during runtime. Please check stacktrace for the root cause.")
;