【数据结构】二叉排序树(c风格、结合c++引用)
目录
1 基本概念
结构体定义
各种接口
2 二叉排序树的构建和中序遍历
递归版单次插入
非递归版单次插入
3 二叉排序树的查找
非递归版本
递归版本
4 二叉排序树的删除(难点)
1 基本概念
普通二叉排序树是一种简单的数据结构,节点的值根据特定顺序(通常是升序或降序)排列。然而,如果普通二叉排序树不平衡,即左、右子树的高度相差很大时,查询效率可能会降低。因此引出了avl树、红黑树等一系列高阶数据结构。
基本性质:
- 若它的左子树不空,则左子树上所有结点的值均小于它根结点的值。
- 若它的右子树不空,则右子树上所有结点的值均大于它根结点的值。
- 它的左、右子树均为为⼆叉排序树。
- 二叉排序树的查找时间复杂度为树的高度,即为O(以2为底N的对数) ,下面全写成O(logN)
- 二叉排序树的中序遍历输出是一个递增的数列。
结构体定义
typedef struct BSTreeNode
{
int val;
struct BSTreeNode* left;
struct BSTreeNode* right;
}BSTNode,*BiTree;各种接口

关于用到C++中的引用:
BSTNode是结构体struct BSTreeNode的别名,BiTree是结构体struct BSTreeNode指针。
在链表中,首次插入时需要修改头节点,由于头节点的定义也是一个指针,所以要修改一个一级指针,必须传入二级指针或者一级指针的引用,二叉树也是一样,首次插入需要修改根节点的指向,所以这里用引用,当然也可以用二级指针,严蔚敏老师编写的数据结构中也经常用到C++的引用。
而再次或多次进行插入时,我们用cur去遍历链表或二叉树,其实是修改链表和二叉树的一个个结构体,这时我们只需要结构体指针,其实就只需要一级指针即可。
因此,我们直接用二级指针或一级指针的引用,就能解决所有的问题。
2 二叉排序树的构建和中序遍历
构建原则:
①根节点为空,先构建根节点。
②插入节点的值小于根节点的值,去根节点的左子树寻找插入位置。
③插入节点的值大于根节点的值,去根节点的右子树寻找插入位置。
void Create(BiTree& root,int* a,int n)
{
for (int i = 0; i < n; ++i)
{
BST_InsertR(root, a[i]);
//BST_Insert(root, a[i]);
}
}遍历数组O(N),数组每个元素插入O(logN),因此构建的时间复杂度是O(NlogN)。
递归版单次插入
int BST_InsertR(BiTree& root, int x)
{
//先申请节点
BSTNode* newnode = (BiTree)malloc(sizeof(BSTNode));
if (newnode == nullptr)
{
perror("malloc fail");
exit(-1);
}
newnode->val = x;
newnode->left = newnode->right = nullptr;
//进行插入
if (root == nullptr)//空树或者走到空
{
root = newnode;
return 1;//插入成功
}
if (root->val == x)
return -1;//插入失败,节点元素值不能相同
if (root->val > x)//x小于根节点的值,就去左子树插入
return BST_InsertR(root->left, x);
if (root->val < x)//x大于于根节点的值,就去右子树插入
return BST_InsertR(root->right, x);
}非递归版单次插入
⭕定义两个指针,cur和prev,prev指向cur的根节点,cur最后走到空,对prev的左右指针进行操作,比对prev->val和x,如果val
right指向新节点,反之。
int BST_Insert(BiTree& root, int x)
{
//二叉排序树左孩子的值比根的值要小,右孩子的值比根的值要大
BSTNode* newnode = (BiTree)malloc(sizeof(BSTNode));
if (newnode == nullptr)
{
perror("malloc fail");
exit(-1);
}
newnode->val = x;
newnode->left = newnode->right = nullptr;
//第一次进来root为空
if (root == nullptr)
{
root = newnode;
return 0;
}
//第二次开始往后遍历
BSTNode* cur = root;
BSTNode* prev = nullptr;
while (cur)//让cur走到空
{
prev = cur;
if (cur->val < x)
{
cur = cur->right;
}
else if (cur->val > x)
{
cur = cur->left;
}
else
{
return -1;//插入失败,不能有元素相等的情况
}
}
if (prev->val < x)
{
prev->right = newnode;
}
if (prev->val > x)
{
prev->left = newnode;
}
return 0;//插入成功
}假设我们用这个数组去构建一棵树:

结果是这样的:
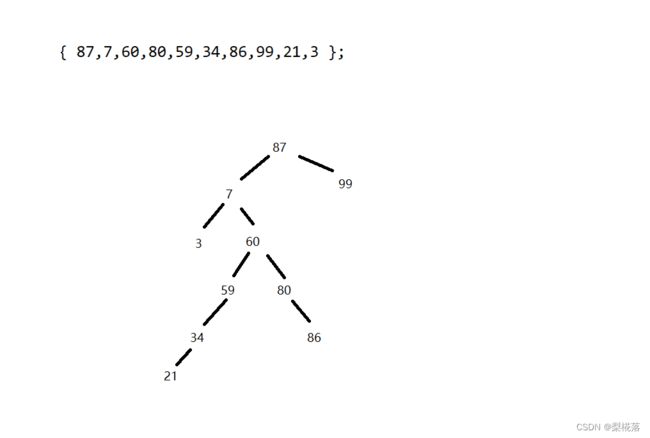
中序遍历:
void InOrder(BiTree root)
{
if (root == nullptr)//空树或走到空
return;
InOrder(root->left);//左子树
printf("%d ", root->val);//根
InOrder(root->right);//右子树
}输出的结果一定是一个递增序列,因此二叉排序树的中序遍历才有意义。
3 二叉排序树的查找
查找原则:
①所查找的值比当前节点的值要小,就去左子树找
②所查找的值比当前节点的值要大,就去右子树找
③查找成功,返回结构体指针BSTNode*/BiTree
二叉排序树的最大查找次数,就是树的深度,类似于折半查找,每查一次排除一半的树。
因此二叉排序树的查找时间复杂度为O(logN) 。
非递归版本
BSTNode* BinarySearch(BiTree root,int x)
{
BSTNode* cur = root;
while (cur)
{
if (cur->val < x)
{
cur = cur->right;
}
else if (cur->val > x)
{
cur = cur->left;
}
else
{
return cur;
}
}
return nullptr;
}递归版本
BSTNode* BinarySearchR(BiTree root, int x)
{
if (root == nullptr)//空树或者找到空了还没找到
return nullptr;
if (x == root->val)
return root;
if (x > root->val)//大于就去右子树找
return BinarySearchR(root->right, x);
if(x < root->val)//小于就去左子树找
return BinarySearchR(root->left, x);
}4 二叉排序树的删除(难点)
删除原则:
①删除节点的右子树为空,左子树不为空,把左子树顶上来。
②删除节点的左子树为空,右子树不为空,把右子树顶上来。
③删除节点的左右子树都不为空,要么在左子树中找最大的数据和根的数据交换,要么在右子树中找最小的数据和根的数据交换。
void DeleteNode(BiTree& root, int x)
{
if (root == nullptr)//找不到或者根为空,直接返回
{
return;
}
//先找后删除,递归
if (x < root->val)
{
DeleteNode(root->left, x);
}
if (x > root->val)
{
DeleteNode(root->right, x);
}
//找到了,执行删除
if (root->val == x)
{
if (root->left == nullptr)//左子树为空,把右子树顶上去
{
BiTree tmp = root;
root = root->right;
free(tmp);
}
else if (root->right == nullptr)//右子树为空,把左子树顶上去
{
BiTree tmp = root;
root = root->left;
free(tmp);
}
else//左右子树均不为空,要么在左子树中找最大的数据和根的数据交换,要么在右子树中找最小的数据和根的数据交换
//采用前者即可,左子树的最大数据就是左子树的最右结点
{
BiTree left = root->left;
while (left->right)
{
left = left->right;
}
root->val = left->val;
//free(left);//不能这么做,万一这个结点有左子树怎么办?
//只能重新在T的左子树找这个结点,复用递归删除这个结点
DeleteNode(root->left, left->val);
}
}
}图解何为“顶上来”
由于函数传参用到引用,因此root就是上一层函数root->left或者root->right的别名:
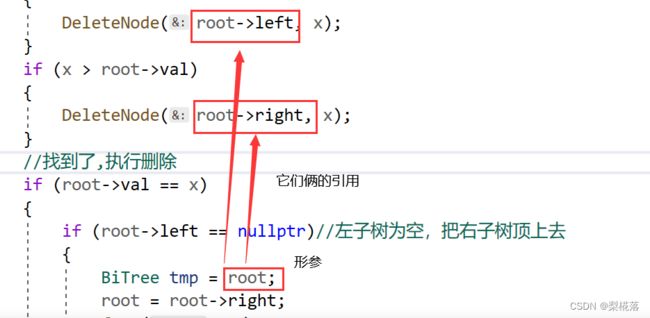
定义指针tmp去指向root形参,root形参用root(1)表示一下:

这时我们想让root->right变为root(1)->right,而root(1)就是root->right的别名,因此我们直接让root(1)=root(1)->right,然后去free(tmp),用代码表示就是这样:

同理,右子树为空,把左子树顶上去:

当左右子树都不为空时,要么去左子树中找最大的数据去替换删除节点,要么去右子树中找最小的数据去替换删除节点。
而左子树中的最大数据位于左子树的最右深处节点,右子树中的最小数据位于右子树的最左深处节点。
什么是“替换”:把要删除的根节点的值与左子树最右节点的值交换,然后“删除”掉左子树最右节点;或者把要删除的根节点的值与右子树最左节点的值交换,然后“删除”掉右子树最左节点。

何为删除?真的是直接free掉吗?
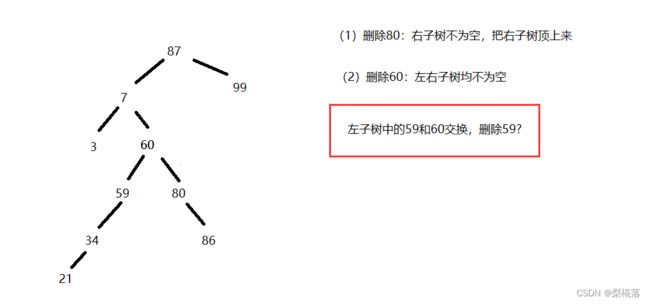 删除59,那它的左子树咋办?直接free就坑了!
删除59,那它的左子树咋办?直接free就坑了!
复用函数去递归删除59,让59的左子树顶上去:
