【C++代码】链表
-
算法:搜索、查找、排序、双指针、回溯、分治、动态规划、贪心、位运算、数学等。
-
数据结构:数组、栈、队列、字符串、链表、树、图、堆、哈希表等。
-
数据结构是为实现对计算机数据有效使用的各种数据组织形式,服务于各类计算机操作。不同的数据结构具有各自对应的适用场景,旨在降低各种算法计算的时间与空间复杂度,达到最佳的任务执行效率。常见的数据结构可分为「线性数据结构」与「非线性数据结构」,具体为:「数组」、「链表」、「栈」、「队列」、「树」、「图」、「散列表」、「堆」。数组是将相同类型的元素存储于连续内存空间的数据结构,其长度不可变。链表以节点为单位,每个元素都是一个独立对象,在内存空间的存储是非连续的。链表的节点对象具有两个成员变量:「值
val」,「后继节点引用next」 。栈是一种具有 「先入后出」 特点的抽象数据结构,可使用数组或链表实现。通过常用操作「入栈push()」,「出栈pop()」,展示了栈的先入后出特性。队列是一种具有 「先入先出」 特点的抽象数据结构,可使用链表实现。通过常用操作「入队push()」,「出队pop()」,展示了队列的先入先出特性。 -
树是一种非线性数据结构,根据子节点数量可分为 「二叉树」 和 「多叉树」,最顶层的节点称为「根节点 root」。以二叉树为例,每个节点包含三个成员变量:「值 val」、「左子节点 left」、「右子节点 right」 。图是一种非线性数据结构,由「节点(顶点)vertex」和「边 edge」组成,每条边连接一对顶点。根据边的方向有无,图可分为「有向图」和「无向图」。
-
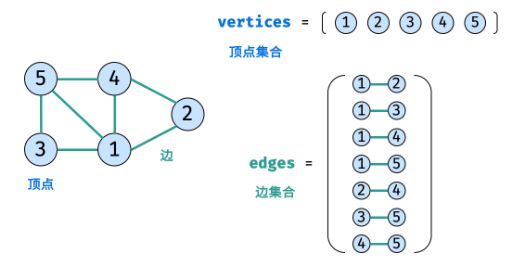
-
表示图的方法通常有两种:邻接矩阵: 使用数组 vertices 存储顶点,邻接矩阵 edges 存储边;edges[i] [j] 代表节点 i+1 和 节点 j+1 之间是否有边。
-
vertices = [1, 2, 3, 4, 5] edges = [[0, 1, 1, 1, 1], [1, 0, 0, 1, 0], [1, 0, 0, 0, 1], [1, 1, 0, 0, 1], [1, 0, 1, 1, 0]] -
邻接表: 使用数组 vertices 存储顶点,邻接表 edges 存储边。 edges 为一个二维容器,第一维 i 代表顶点索引,第二维 edges[i] 存储此顶点对应的边集和;例如 edges[0]=[1,2,3,4] 代表 vertices[0] 的边集合为 [1,2,3,4] 。
-
vertices = [1, 2, 3, 4, 5] edges = [[1, 2, 3, 4], [0, 3], [0, 4], [0, 1, 4], [0, 2, 3]] -
邻接矩阵 VS 邻接表 :
邻接矩阵的大小只与节点数量有关,即 N 2 N^2 N2 ,其中 N 为节点数量。因此,当边数量明显少于节点数量时,使用邻接矩阵存储图会造成较大的内存浪费。因此,邻接表 适合存储稀疏图(顶点较多、边较少); 邻接矩阵 适合存储稠密图(顶点较少、边较多)。
-
-
散列表是一种非线性数据结构,通过利用 Hash 函数将指定的「键
key」映射至对应的「值value」,以实现高效的元素查找。则可通过建立姓名为key,学号为value的散列表实现此需求,代码如下:-
# 初始化散列表 dic = {} # 添加 key -> value 键值对 dic["小力"] = 10001 dic["小特"] = 10002 dic["小扣"] = 10003 # 从姓名查找学号 dic["小力"] # -> 10001 dic["小特"] # -> 10002 dic["小扣"] # -> 10003 -
实际的 Hash 函数需保证低碰撞率、 高鲁棒性等,以适用于各类数据和场景。
-
-
堆是一种基于「完全二叉树」的数据结构,可使用数组实现。以堆为原理的排序算法称为「堆排序」,基于堆实现的数据结构为「优先队列」。堆分为「大顶堆」和「小顶堆」,大(小)顶堆:任意节点的值不大于(小于)其父节点的值。
- 完全二叉树定义: 设二叉树深度为 k ,若二叉树除第 k 层外的其它各层(第 1 至 k−1 层)的节点达到最大个数,且处于第 k 层的节点都连续集中在最左边,则称此二叉树为完全二叉树。
-
为包含
1, 4, 2, 6, 8元素的小顶堆。将堆(完全二叉树)中的结点按层编号,即可映射到右边的数组存储形式。-
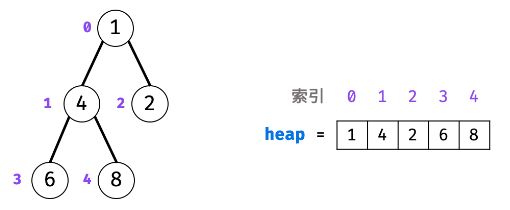
-
通过使用「优先队列」的「压入
push()」和「弹出pop()」操作,即可完成堆排序,实现代码如下: -
from heapq import heappush, heappop # 初始化小顶堆 heap = [] # 元素入堆 heappush(heap, 1) heappush(heap, 4) heappush(heap, 2) heappush(heap, 6) heappush(heap, 8) # 元素出堆(从小到大) heappop(heap) # -> 1 heappop(heap) # -> 2 heappop(heap) # -> 4 heappop(heap) # -> 6 heappop(heap) # -> 8
-
-
算法复杂度旨在计算在输入数据量 N 的情况下,算法的「时间使用」和「空间使用」情况;体现算法运行使用的时间和空间随「数据大小 N 」而增大的速度。算法复杂度主要可从 时间 、空间 两个角度评价:
-
时间: 假设各操作的运行时间为固定常数,统计算法运行的「计算操作的数量」 ,以代表算法运行所需时间;
-
空间: 统计在最差情况下,算法运行所需使用的「最大空间」;
-
根据输入数据的特点,时间复杂度具有「最差」、「平均」、「最佳」三种情况,分别使用 O , Θ , Ω 三种符号表示。
-
根据从小到大排列,常见的算法时间复杂度主要有:
-
O ( 1 ) < O ( l o g N ) < O ( N ) < O ( N l o g N ) < O ( N 2 ) < O ( 2 N ) < O ( N ! ) O(1)
-

-
空间复杂度涉及的空间类型有:
- 输入空间: 存储输入数据所需的空间大小;
- 暂存空间: 算法运行过程中,存储所有中间变量和对象等数据所需的空间大小;
- 输出空间: 算法运行返回时,存储输出数据所需的空间大小;
-
通常情况下,空间复杂度指在输入数据大小为 N 时,算法运行所使用的「暂存空间」+「输出空间」的总体大小。
-
-
编译后,程序指令所使用的内存空间。算法中的各项变量使用的空间,包括:声明的常量、变量、动态数组、动态对象等使用的内存空间。程序调用函数是基于栈实现的,函数在调用期间,占用常量大小的栈帧空间,直至返回后释放。
-
对于算法的性能,需要从时间和空间的使用情况来综合评价。优良的算法应具备两个特性,即时间和空间复杂度皆较低。而实际上,对于某个算法问题,同时优化时间复杂度和空间复杂度是非常困难的。降低时间复杂度,往往是以提升空间复杂度为代价的,反之亦然。
题目:书店店员有一张链表形式的书单,每个节点代表一本书,节点中的值表示书的编号。为更方便整理书架,店员需要将书单倒过来排列,就可以从最后一本书开始整理,逐一将书放回到书架上。请倒序返回这个书单链表。
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: vectorreverseBookList(ListNode* head) { stack st; vector ve; while(head){ st.push(head->val); head = head->next; } while(!st.empty()){ ve.push_back(st.top()); st.pop(); } return ve; } }; -
反转的实现就是一点小技巧,需要用到三个指针变量,类似于两个数交换的思想,层次递进。现在假设定义pre、phead、temp三个指针变量,用phead指向链表的头结点,而pre代表phead的前一个节点。具体实现代码如下:
-
ListNode* InvertList(link head){ ListNode* pre,phead,temp; phead = &head; //将phead指向链表头,做游标使用 pre = NULL; //pre为头指针之前的节点 while(phead != NULL){ temp = pre; pre = phead; phead = phead->next; pre->next = temp; //pre接到之前的节点 } return pre; }
-
-
利用递归,先递推至链表末端;回溯时,依次将节点值加入列表,即可实现链表值的倒序输出。
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: vectorres; void track(ListNode* head){ if(head==nullptr){ return ; } track(head->next); res.push_back(head->val); } vector reverseBookList(ListNode* head) { track(head); return res; } };
-
题目:给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。返回删除后的链表的头节点。
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: ListNode* deleteNode(ListNode* head, int val) { ListNode* prenode = new ListNode(-1); prenode->next = head; ListNode* temp = prenode; while(temp->next){ if(temp->next->val == val){ temp->next = temp->next->next; break; } temp = temp->next; } return prenode->next; } }; -
本题删除值为
val的节点分需为两步:定位节点、修改引用。定位节点: 遍历链表,直到 head.val == val 时跳出,即可定位目标节点。修改引用: 设节点 cur 的前驱节点为 pre ,后继节点为 cur.next ;则执行 pre.next = cur.next ,即可实现删除 cur 节点。对于头节点没有前驱,可以设置一个虚拟节点。
题目:给定一个头节点为 head 的单链表用于记录一系列核心肌群训练编号,请将该系列训练编号 倒序 记录于链表并返回。
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* trainningPlan(ListNode* head) { ListNode *pre,*cur; pre = nullptr; cur = head; while(head){ cur = head; head = head->next; cur->next = pre; pre = cur; } return pre; } }; -
时间复杂度 O(N) : 遍历链表使用线性大小时间。空间复杂度 O(1) : 变量 pre 和 cur 使用常数大小额外空间。
题目:给定一个头节点为 head 的链表用于记录一系列核心肌群训练项目编号,请查找并返回倒数第 cnt 个训练项目编号。
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* trainingPlan(ListNode* head, int cnt) { int n=0; ListNode* node = nullptr; for(node=head;node;node=node->next){ n++; } for(node = head;n>cnt;n--){ node = node->next; } return node; } }; -
两次遍历,用双指针只需要一次遍历
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* trainingPlan(ListNode* head, int cnt) { ListNode* left =head; ListNode* right = head; while(right && cnt>0){ right = right->next; cnt--; } while(right){ right = right->next; left = left->next; } return left; } };
题目:给定两个以 有序链表 形式记录的训练计划 l1、l2,分别记录了两套核心肌群训练项目编号,请合并这两个训练计划,按训练项目编号 升序 记录于链表并返回。注意:新链表是通过拼接给定的两个链表的所有节点组成的。
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* trainningPlan(ListNode* l1, ListNode* l2) { if(!l1){ return l2; } if(!l2) return l1; ListNode* res; ListNode* head; if(l1->val < l2->val){ head = l1; l1 = l1->next; }else{ head = l2; l2 = l2->next; } res = head; while(l1 && l2){ if(l1->val < l2->val){ res->next = l1; l1 = l1->next; }else{ res->next = l2; l2 = l2->next; } res = res->next; } if(l1){ res->next = l1; } if(l2){ res->next = l2; } return head; } }; -
链表 l1 , l2 是 递增 的,因此容易想到使用双指针 l1 和 l2 遍历两链表,根据 l1.val 和 l2.val 的大小关系确定节点添加顺序,两节点指针交替前进,直至遍历完毕。引入伪头节点: 由于初始状态合并链表中无节点,因此循环第一轮时无法将节点添加到合并链表中。解决方案:初始化一个辅助节点 dum 作为合并链表的伪头节点,将各节点添加至 dum 之后。
-
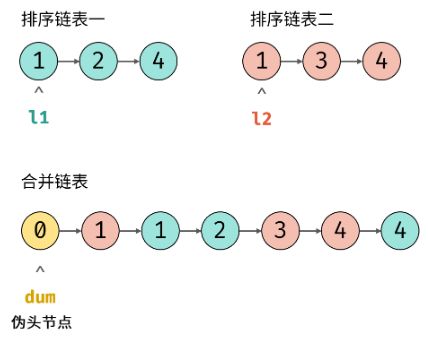
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode() : val(0), next(nullptr) {} * ListNode(int x) : val(x), next(nullptr) {} * ListNode(int x, ListNode *next) : val(x), next(next) {} * }; */ class Solution { public: ListNode* trainningPlan(ListNode* l1, ListNode* l2) { ListNode* dumy = new ListNode(0); ListNode* cur =dumy; while(l1 && l2){ if(l1->val < l2->val){ cur->next = l1; l1 = l1->next; }else{ cur->next = l2; l2 = l2->next; } cur = cur->next; } cur->next = l1!=nullptr?l1:l2; return dumy->next; } };
题目:某教练同时带教两位学员,分别以链表 l1、l2 记录了两套核心肌群训练计划,节点值为训练项目编号。两套计划仅有前半部分热身项目不同,后续正式训练项目相同。请设计一个程序找出并返回第一个正式训练项目编号。如果两个链表不存在相交节点,返回 null 。
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { // ListNode* pa = headA; // ListNode* pb = headB; if(!headB || !headA){ return NULL; } ListNode* cur =headA,*res = NULL; while(cur){ cur->val *= -1; cur = cur->next; } cur = headB; while(cur){ if(cur->val < 0){ res = cur; break; } cur = cur->next; } cur = headA; while(cur){ cur->val *= -1; cur = cur->next; } return res; } }; -
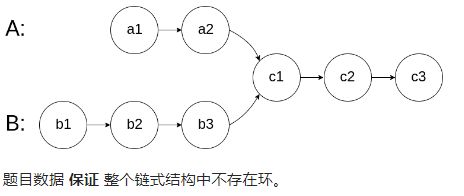
-
/** * Definition for singly-linked list. * struct ListNode { * int val; * ListNode *next; * ListNode(int x) : val(x), next(NULL) {} * }; */ class Solution { public: ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) { if(!headA || !headB){ return nullptr; } ListNode *pa=headA,*pb=headB; while(pa != pb){ pa = pa==nullptr?headB:pa->next; pb = pb==nullptr?headA:pb->next; } return pa; } };
题目:请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
-
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
-
/* // Definition for a Node. class Node { public: int val; Node* next; Node* random; Node(int _val) { val = _val; next = NULL; random = NULL; } }; */ class Solution { public: Node* copyRandomList(Node* head) { if(head==nullptr){ return nullptr; } for(Node* node = head;node!=nullptr;node=node->next->next){ Node* newnode = new Node(node->val); newnode->next = node ->next; node->next = newnode; } for(Node* node =head;node!=nullptr;node = node->next->next){ Node* newnode = node->next; newnode->random = (node->random != nullptr)?node->random->next:nullptr; } Node* newhead = head->next; for(Node* node=head;node!=nullptr;node = node->next){ Node* newnode = node->next; node->next = node->next->next; newnode->next = (newnode->next!=nullptr)?newnode->next->next:nullptr; } return newhead; } };