Redis基础数据结构
Redis有5种基本数据结构:String(字符串)、list(列表)、set(集合)、hash(哈希)、zset(有序集合)
字符串string
字符串类型是Redis的value最简单的数据结构,类似与Java语言中的ArrayList(数字列表),不过在Redis里String是一种动态字符串
Redis里的String采用预分配冗余空间的方法
set & get
>set keyname test
OK
Redis有5种基本数据结构:String(字符串)、list(列表)、set(集合)、hash(哈希)、zset(有序集合)
字符串类型是Redis的value最简单的数据结构,类似与Java语言中的ArrayList(数字列表),不过在Redis里String是一种动态字符串
Redis里的String采用预分配冗余空间的方法
set & get
>set keyname test
OK
>get keyname
test
//key如果存在就返回0
>setnx keyname test
0
>exists keyname
>del keyname
1
//批量设置
>mset key1 test1 key2 test2
OK
//批量获取
>mget key1 key2
key过期
//设置5s后过期
>expire keyname 5
//setex是expire和set的复合写法
>setex keyname 5 test
OK
//5s后查询
>get keyname
NULL
计数
ps:value为数字的情况,可以使用incr和incrby计数
>set num 10
OK
//incr默认加1
>incr num
11
//incrby后面要加上数字
>incrby num
ERR wrong number of arguments for ‘incrby’ command
//正确计数
>incrby num 5
16
下面介绍一下redis的另外一种数据结构list
前面我们说redis里的string类似与java语言里面的ArrayList,则redis里的列表就类似于LinkList(链表),链表一个特别就是更新和新增特别快,查询索引慢。
为什么说类似与linklist?因为redis的list并非和linklist一样,它其实是一种快速列表(quicklist)的形式,列表结构如图:
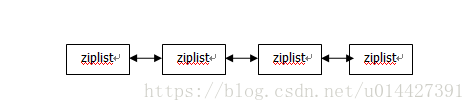
这里要介绍一下压缩列表(ziplist)了,压缩列表是什么?其实就是连续的内存空间
从图可以看出快速列表其实就是由压缩列表和双向的指针组成,不过我们知道链表是两个指针的,也就是prev和next执行,这就是快速列表和linklist的一个不同点了。
PS:然后redis设计时,为什么改成双向指针?假如和链表一样,用两个指针prev、next,同样可以实现遍历,不过双向指针有一个很明显的优点,就是占用的内存空间就相对少了。
队列和栈
/* 队列:First in first out */
//加两个value
>rpush keynames key1 key2
2
//计算
>llen keynames
2
>lpop keynames
key1
>lpop keynames
key2
//rpush会自动过期的
>rpop keynames
NULL
/* 栈:First in last out */
//同样,加两个元素
>rpush keynames key1 key2
2
>rpop keynames
key2
>rpop keynames
key1
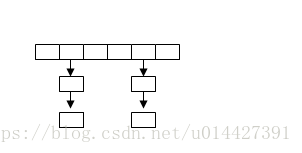
Redis的字典类似与java语言的hashmap,也是无序的二维结构,也即数组加列表的结构。这是redis字典和hashmap类似的地。
然后也有不同,比如rehash,刷新字典操作,hashmap是全部热hash,当字典足够多时,性能不是很好的,所以redis进行改造,采用渐进式的方式,为什么说是渐进式?因为redis不会全部reload,而是保存新旧两个字典,然后采用定时任务,将旧hash的数据搬到新的hash,搬后在回收hash内存空间
字典(hash)的数组加链接结构:
>hset keynames key1 "test1"
1
>hset keynames key2 “test2”
1
//批量set
>hmset keynames key1 “test1” key2 “test2”
OK
//获取key1的值
>hget keynames key1
test1
//获取hash为keynames的长度
>hlen keynames
2
//获取全部
>hgetall keynames
redis的set和java语言中的hashset类型,是一种无序唯一的。
>sadd keynames key1
1
//key1已经加过了,所以返回1
>sadd keynames key1 key2
1
>smembers keynames
//查询某个key是否存在,相当与contains
>sismember keynames key1
1
//相当于count
>scard keynames
2
//随意弹出key1
>spop keynames
key1
有序集合是redis里比较有特色的,它类似于SortedSet和HashMap的组合。其内部实现是一种被称作跳跃列表的数据结构。有序集合一方面它就是一个set,所以每个元素都是唯一的,然后它可以给每个value赋值一个score,再根据这个score进行排序,score就相当于一个权限排序的标识。
ps:因为这个原因,有序集合可以被用来存储粉丝信息,value值是粉丝id,score是关注时间
//9.0是score也就是权重
>zadd keyname 9.0 math
1
>zadd keyname 9.2 history
1
//顺序
>zrange keyname 0 -1
//逆序
>zrevrange keyname 0 -1
//相当于count()
>zcard keyname
2
获取指定key的score
>zscore keyname math
9
跳跃列表 TODO