详解Rust编程中的生命周期
1.摘要
生命周期在Rust编程中是一个重要概念, 它能确保引用像预期的那样一直有效。在Rust语言中, 每一个引用都有其生命周期, 通俗讲就是每个引用在程序执行的过程中都有其自身的作用域, 一旦离开其作用域, 其生命周期也宣告结束, 值不再有效。幸运的是, 在绝大多数时间里, 生命周期是隐含且可以进行推断的, 类似于当有多种可能的类型时必须注明类型, 正因为如此, 所以Rust需要使用者使用泛型生命周期参数来注明它们的关系, 从而确保程序运行时实际使用的引用绝对有效。
2.悬垂引用问题
悬垂引用会导致Rust编程中出现一些潜在的安全问题, 例如: 程序在无意之中引用了非预期引用的数据, 而这种现象在没有任何约束的情况下很容易出现。Rust编程中引入生命周期的主要原因就是避免编程过程中出现的悬垂引用问题。
下面看一个代码示例:
fn main() {
let num;
{
let count = 5;
num = &count;
}
println!("num: {}", num);
}首先定义了一个变量num, 下面的花括号表示进入到一个作用域, 在该作用域中, 定义了一个变量count,并赋值为5, 在这个内部作用域中,&count表示一个对变量count的引用, 然后将其赋给变量num, 在作用域的外部, 调用println打印出num的值。
先尝试编译一下这段代码试试:
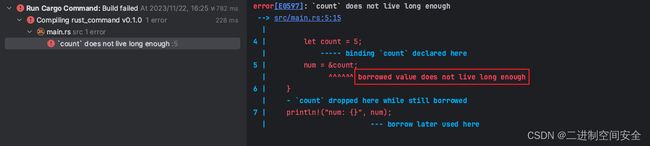
Rust编译器报错的地方指向代码: num = &count, 并报了一个错误:"borrowed value does not live long enough", 意思是&count的值并没有存在足够久, 并很贴心的用蓝色字告诉我们作用域的范围界定。那么有一个问题, Rust编译器是以什么机制来判定作用域使用的合法性呢?
3.Rust检查机制
在Rust编译器中, 有一个被称为借用检查器的机制, 它的主要工作原理是通过比较作用域来确保代码中所有的借用都是有效的, 看一下下面的代码标识:
fn main() {
let num; ------------------------- num_s
{ |
let count = 5; ------ count_s |
num = &count; --------- |
} |
println!("num: {}", num);------------
}这里将上面代码中的两个关键变量num和count分别引入一个各自代表其生命周期的标识:num_s和count_s。很明显可以看到, num变量的起点在作用域上面, 终点在作用域下面,。而count_s的生命周期起点在进入第一个花括号后面, 终点在第二个花括号前面, 也就是说, num变量的生命周期num_s包含了count_s的生命周期, 所以Rust编译器利用借用检查器比较两个变量的生命周期大小, 很容易推断出num的生命周期明显要长。
上面的代码被Rust编译器拒绝编译, 正是因为借用检查器首先发现 num_s的生命周期比count_s要长, 而num = &count这句代码, 被引用的对象&count比引用者num存在的时间更短, 因此产生了悬垂引用。
那么解决该问题的方式也比较简单, 只要被引用对象和引用者处于同一作用域即可解决, 如下代码:
方式一:
fn main() {
let count = 5;
let num = &count;
println!("num: {}", num);
}方式二:
fn main() {
let num;
{
let count = 5;
num = &count;
println!("num: {}", num);
}
}4.泛型生命周期
下面有一段代码, 主要完成了两个字符串的长度比较功能, 其中compare函数负责完成两个字符串的长度比较并返回长度最长的字符串的
切片。代码如下:
fn compare(a: &str, b: &str) -> &str {
if a.len() > b.len() {
a
} else {
b
}
}
fn main() {
let sample1 = String::from("sample for suntiger");
let sample2 = "suntiger";
let c_result = compare(sample1.as_str(), sample2);
println!("最长的字符串是 {}", c_result);
}这段代码编译时,Rust编译器的返回如下:
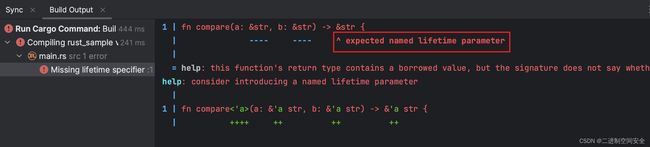
上面的错误提示分为三个部分: compare函数的两个参数以及返回值存在生命周期问题。首先, Rust编译器并不清楚将要返回的引用&str到底是指向参数a还是参数b, 其实作为程序员自己也是不知道的, 因为只有在运行时通过比较两个参数的长度大小后才知道哪个参数切片的字符串内容更长。
因此, 根据Rust编译器的绿色标记提示, 在编写compare函数时, 必须增加泛型生命周期参数来定义引用间的关系以便Rust的检查机制能够正确分析。
5.生命周期注解
在上面的编译器返回提示中, 绿色的部分: <'a>、&'a被称为生命周期注解, 这个也是Rust语言独特的语法, 看起来比较奇葩和抽象, 那么Rust如何去定义这个注解呢, 以下是简单的语法:
&str // 称为引用
&'a str // 称为带有显式生命周期的引用
&'a mut str // 称为带有显式生命周期的可变引用生命周期注解的一个重要作用就是告诉Rust编译器在多个引用的泛型生命周期参数存在期间它们如何相互联系。
尝试将compare函数代码修改如下:
fn compare<'a>(a: &'a str, b: &'a str) -> &'a str {
if a.len() > b.len() {
a
} else {
b
}
}再次尝试编译, Rust编译器返回如下:

这次返回了正确的结果, 当在函数中使用生命周期注解时, 这些注解只存在于函数签名中, 而不存在于函数体的任何代码中, 当在实际应用过程中, 参数的引用传给compare函数时, 被'a取代的具体生命周期是参数a的作用域与参数b的作用域重叠的那一部分, 换句话说就是两个参数中生命周期较小的那一个。
6.结构体生命周期注解
在定义结构体时, 也要在相应的地方加上生命周期注解, 结构体定义如下:
struct PersonInfo<'a> {
name: &'a str,
}在该结构体中定义了一个name的字段, 其中存放了一个字符串切片, 为了能够在结构体定义中使用生命周期参数, 必须在结构体名称后面的括号中声明泛型生命周期参数。
接下来需要在main函数中创建一个结构体实例, 将一个字符串切片内容传给结构体参数, 代码如下:
fn main() {
let sayinfo = String::from("今天天气不错#挺风和日丽的...");
let headerinfo = sayinfo.split('#').next().expect("找不到分隔符'#'");
let pi = PersonInfo {
name: headerinfo,
};
println!("分割name内容为: {}", pi.name);
}在上面的代码中, 对变量sayinfo中的内容作了字符串分割, 如果找到符号#,则取前面的内容,然后将该部分内容存到结构体字段中。
编译结果如下:

因为变量sayinfo在结构体PersonInfo之前创建, 且结构体离开作用域之后,变量sayinfo仍然不会离开作用域, 因此PersonInfo实例中的引用一直都是有效的, 并不会出问题。
7.静态生命周期
静态生命周期和静态变量一样, 都有一个关键字: static, 例子代码如下:
let sample: &'static str = "我是一个静态周期的例子.";现在变量sample的生命周期会一直持续, 在整个程序中都是有效的, 尽管静态生命周期会避免编码过程中的很多编译器检查错误, 但是一旦在编码过程中出现悬垂引用的错误编码时, 更正确的做法应该是想办法解决悬垂引用的问题,而不是靠静态生命周期避开错误。
8.总结
在本篇文章中我们探索了生命周期在Rust常见场景中的各种应用, 但在复杂的业务场景中, 可能还会遇到其它错误, 这时候依靠Rust编译器强大的提示功能应该能够准确找到出现问题的地方, 在这个过程中解决问题, 除了加深印象, 还能起到举一反三的作用。