ELK文档
背景
ELK日志系统
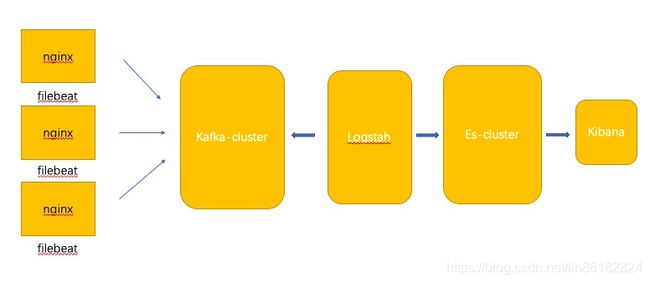
总体架构如上。以下为实现步骤。
环境准备及说明
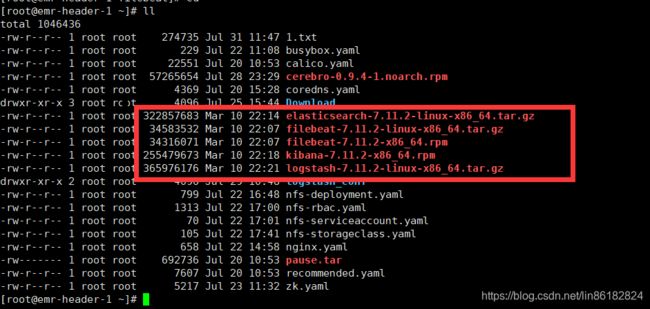
这几个包的自己到ES官网下载即可,软件的版本都建议一致,不一致可能会有问题。是二进制安装还是下载tar包自己解压也按照自己怎么方便怎么来。
注:es用root启动会有问题,所以我自己创建了个elk的用户。然后对应这些服务几乎都是用elk启动的,或者把这些服务的目录权限给到elk用户(改属主属组或者直接权限777)。
以下是我自己部署的时候直接改成777了。因为我这个也只是测试用,所以部署的有点混乱,如果是生产的话建议使用同一种部署方式不要那么混乱。
filebeat是直接rpm安装的:
es和logstash是tar包解压过来的:
zookeeper的环境因为我使用的是阿里云EMR的环境,本身就自带了,我就没有自己再安装一个了。zookeeper的部署安装可以自己参考一些开源的文档都是ok的,比较简单,这里就不写了。
kafka的环境虽然这个集群里面没有,但是我看到这些机器里的镜像里面还是打了这些软件栈的,有对应的软件包。所以我也懒得下载直接就使用现成的了。直接软连接一下然后改下对应配置即可。

ln -s /opt/apps/ecm/service/kafka/2.11-1.1.1-1.3.3/package/kafka_2.11-1.1.1-1.3.3 /lib/kafka-current
cd /lib/kafka-current/
这里为了方便我也改成了777权限没有用elk用户。生产上可以建议改成对应的用户。
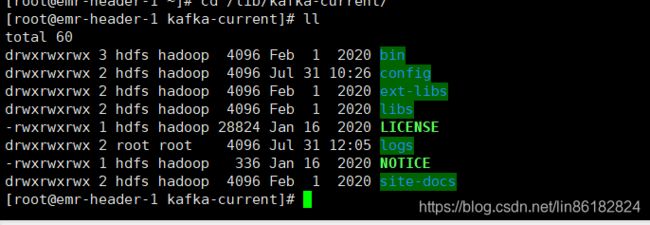
修改一下里面kafka的配置即可。参数意思可以自己查询下。
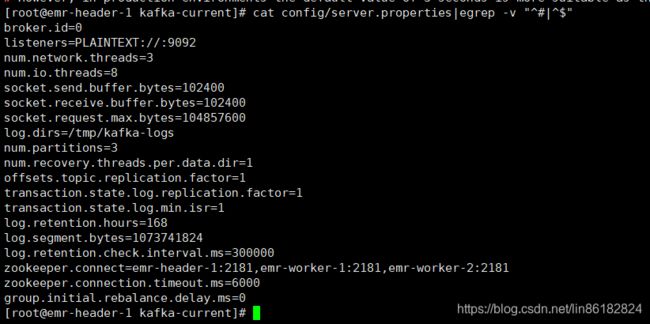
因为我的集群还有另外两台机器,所以我也在另外两台做了相同的操作。这里只需要改下broker.id即可。
然后加下/etc/profile环境变量再启动好kafka

export KAFKA_HEAP_OPTS="-Xmx1024M -Xms1024M"
kafka-server-start.sh -daemon config/server.properties

filebeat配置准备
vim /etc/filebeat/filebeat.yml
filebeat.inputs:
- type: log
enable: true
paths:
- /var/log/nginx/access.log
tags: ["access"]
- type: log
enable: true
paths:
- /var/log/nginx/error.log
tags: ["error"]
output.kafka:
hosts: ["k8s1:9092","k8s2:9092","k8s3:9092"]
topics:
- topic: "kafka-nginx-access"
when.contains:
tags: "access"
- topic: "kafka-nginx-error"
when.contains:
tags: "error"
这里配置尤其注意,因为一些小细节浪费了我一些时间。。这里的k8s1这种host解析和之前的emr-xxx是对应的。因为我在hosts文件里多添加了解析。三台机器其实还是对应关系。
这里配置好需要读取的目录即可。error日志如果是模拟的话可以随便复制一点报错贴上去即可。以下给条我的access日志格式。这里的日志文件自己准备或者采用自己的nginx的日志。
14.165.64.165 - - [10/Nov/2021:00:01:53 +0800] "POST /course/ajaxmediauser/ HTTP/1.1" 200 54 "www.lzc.com" "http://www.lzc.com/video/678" mid=678&time=60&learn_time=551.5 "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36" "-" 10.100.166.110:80 200 0.014 0.014
启动
systemctl start filebeat
systemctl status filebeat
es配置准备
[root@emr-header-1 ~]# cat /usr/local/elasticsearch/config/elasticsearch.yml|egrep -v "^#|^$"
cluster.name: my-application
node.name: k8s1
path.data: /var/lib/es
path.logs: /var/log/es
network.host: 0.0.0.0
http.port: 9200
discovery.seed_hosts: ["k8s1", "k8s2","k8s3"]
cluster.initial_master_nodes: ["k8s1", "k8s2","k8s3"]
另外两台机器的话修改下node.name即可。这里要注意的是我这里的path路径,我自己的elk用户是创建不了,要么更改成elk有权限创建的路径,要么root先创建出来然后赋予权限。这里es用root启动会报错,所以我用的是elk用户启动。
bin/elasticsearch -d
logstah配置准备
[elk@emr-header-1 ~]$ cat nginx_input_kafka_output_es.conf
input {
kafka {
bootstrap_servers => "emr-header-1:9092,emr-worker-1:9092,emr-worker-2:9092"
topics => ["kafka-nginx-access"]
group_id => "logstash"
consumer_threads => 3
codec => "json"
}
kafka {
bootstrap_servers => "emr-header-1:9092,emr-worker-1:9092,emr-worker-2:9092"
topics => ["kafka-nginx-error"]
group_id => "logstash"
consumer_threads => 3
codec => "json"
}
}
filter {
if "access" in [tags][0] {
grok {
match => { "message" => "%{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] \"%{WORD:method} %{URIPATHPARAM:request} HTTP/%{NUMBER:httpversion}\" %{NUMBER:response} (?:%{NUMBER:bytes}|-) %{QS:hostname} (?:%{QS:referrer}|-) (?:%{NOTSPACE:post_args}|-) %{QS:useragent} (?:%{QS:x_forward_for}|-) (?:%{URIHOST:upstream_host}|-) (?:%{NUMBER:upstream_response_code}|-) (?:%{NUMBER:upstream_response_time}|-) (?:%{NUMBER:response_time}|-)" }
}
useragent {
source => "useragent"
target => "useragent"
}
geoip {
source => "clientip"
}
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
convert => ["bytes","integer"]
convert => ["response_time","float"]
remove_field => ["message","agent","tags"]
add_field => { "target_index" => "logstash-kafka-nginx-access-%{+YYYY.MM}" }
}
#提取具体域名
if [referrer] =~ /^"http/ {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST:referrer_host}' }
}
}
#提取用户请求资源类型及资源id编号
if "lzc.com" in [referrer_host] {
grok {
match => { "referrer" => '%{URIPROTO}://%{URIHOST}/(%{NOTSPACE:lzc_type}/%{NOTSPACE:lzc_res_id})?"' }
}
}
}
else if "error" in [tags][0] {
date {
match => ["timestamp","dd/MMM/yyyy:HH:mm:ss Z"]
target => "@timestamp"
timezone => "Asia/Shanghai"
}
mutate {
add_field => { "target_index" => "logstash-kafka-nginx-error-%{+YYYY.MM}" }
}
}
}
output {
elasticsearch {
hosts => ["k8s1:9200","k8s2:9200","k8s3:9200"]
index => "%{[target_index]}"
template_overwrite => true
}
}
启动
/usr/local/logstash/bin/logstash -f nginx_input_kafka_output_es.conf
查看结果
这里可以用es命令或者kibana看。我这里之前安装了个cerebro。所以直接就用这个看了。这里我看了配置文件端口被集群其他服务占用了,所以自己改了端口(/etc/cerebro/application.conf里)。需要下载的可以到GitHub上去搜索cerebro。
这个就是cerebro页面,这里就可以看到已经到es里面了。
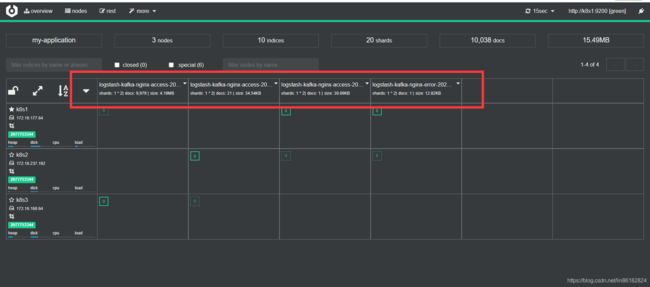
kibana
kibana这里我是rpm的安装方式,所以直接修改下配置然后system启动即可
[elk@emr-header-1 kibana]$ cat kibana.yml |egrep -v "^#|^$"
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://k8s1:9200","http://k8s2:9200","http://k8s3:9200"]
i18n.locale: "zh-CN"
启动
[elk@emr-header-1 kibana]$ systemctl start kibana