基于WSL2+Docker+VScode搭建机器学习(深度学习)开发环境
基于WSL2+Docker+VScode搭建机器学习(深度学习)开发环境
内容概述:由于最近配发了新的工作电脑但不想装双系统,因此通过本博文来记录基于Windows子系统WSL+Docker搭建机器学习与深度学习开发环境的流程步骤,同时记录该过程中所遇到的相关问题及解决方案。期待为同行学习者提供参考;
最终效果:在Windows电脑上,无需安装VMware等虚拟机(显式)或双系统,即可使用Linux,并基于Linux使用docker或其他依赖于Linux的机器学习工具包;
注意:这篇Post分为如下两个部分:
第一部分:利用WSL2+Vscode实现开发环境的搭建。
第二部分:进一步在WSL2中配置Docker与Nvidia docker Toolkit,实现基于Docker的开发环境搭建。
其中,第一部分内容已经可以满足日常开发的需要,没有Docker使用需求的同行可直接跳过第二部分。
但博主本人日常工作需要用到Docker及相关工具,且本人认为基于Docker容器来管理日常开发环境,可以更好地避免日常项目中的包版本间的冲突关系。同时,利用Docker搭建开发环境,其试错成本低,不会对物理机环境有任何影响,可充分保持物理机环境的干净,即便重装系统,也可快速地恢复本地开发环境(前提是已经把自己的Docker开发环境打包成镜像,并上传pull至docker hub, 以便可随时拉取至本地)。
第一部分:利用WSL2+Vscode搭建开发环境
(1) 开启系统功能
由于WSL是Windows子系统,因此首先需要启用相关系统功能:
- 适用于Linux的Windows子系统;
- 虚拟机平台;
具体地,需要在Windows控制面板中开启如下图所示的功能选项;同时待系统搜索安装完成后,重启系统;

(2) 将WSL2设置为默认版本
在Windows系统中打开 PowerShell, 将 WSL 2 设置为默认版本,如下图所示:

出现如图所示的提示信息,即为设置成功。
(3) 安装Ubuntu
在微软商店,搜索安装Ubuntu,这里选择安装ubuntu22.04:
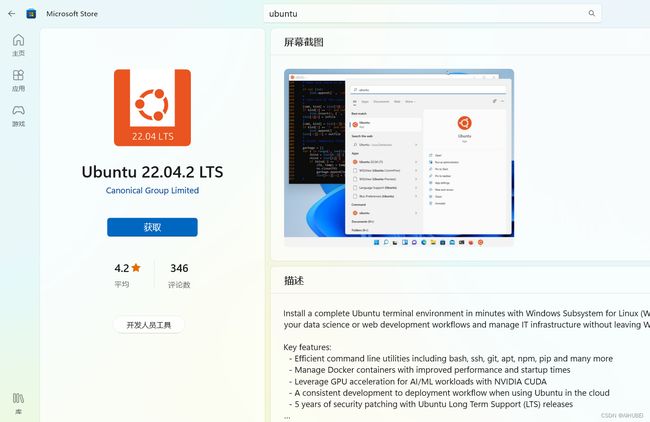
安装完成后,在开始菜单即可选中启动。
可选步骤(可跳过),其中,点击启动后可能出现如下错误:

对上述错误,按照错误解决方法即可解决。具体地,下载如下图所示的Linux内核更新包,即可:
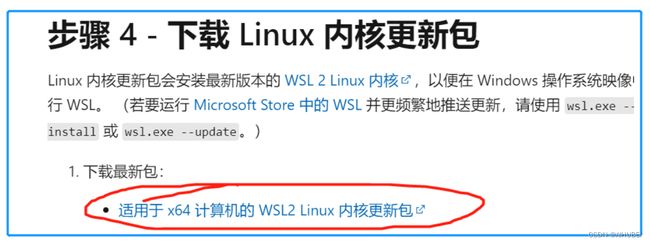
问题解决方法链接:https://github.com/microsoft/WSL/issues/5393
具体解决步骤链接: https://learn.microsoft.com/zh-cn/windows/wsl/install-manual#step-4—download-the-linux-kernel-update-package
上述步骤完成后,即可正常启动,然后提示设置用户名和密码,设置完成后 启动界面如下图所示:

(4) 安装Anaconda并配置环境变量
在上述Linux子系统中,安装Anaconda3,以提供虚拟环境管理工具。具体地,命令如下:
# Step one: 下载安装包.
wget https://repo.anaconda.com/archive/Anaconda3-2021.05-Linux-x86_64.sh
# Step two: 执行bash命令,其中会多次输入yes确认.
# note:需进入到安装包所在目录或键入绝对路径.
bash Anaconda3-2021.05-Linux-x86_64.sh
安装完成,如下图所示:

然后是配置环境变量,方便使用conda来进行虚拟环境创建管理,步骤如下:
# Step three.
# 使用vim编辑器将anaconda安装路径的bin目录添加到配置文件
vim ~/.bashrc
# 按i进入插入模式,如下图所示,添加安装路径到行末
PATH=/home/user/anaconda3/bin:$PATH
# note: 其中,usr需要根据实际情况修改,对应步骤三的用户名;

# Step four:保存退出vim编辑器
按键盘ESC键,退出插入模式,然后输入冒号wq并回车保存编辑内容
:wq
# Step five:刷新配置文件,效果如下图所示.
source .bashrc

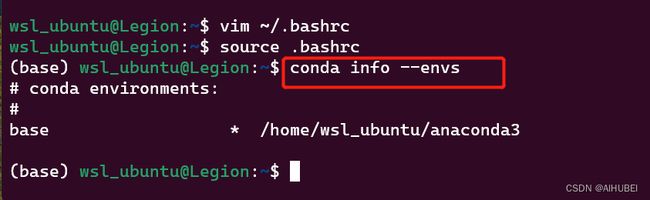
这时候,Anaconda及环境便令均安装配置完成。后面就可以像在Windowns上一样,新增管理conda虚拟环境
(5) 安装Vscode及相关扩展
在Windows上的Vscode安装过程简单,此处省略。仅说明需要安装的关键插件,实现Vscode能够链接WSL2里面的开发环境。具体如下:
- 安装WSL插件,用于连接WSL中的Conda虚拟环境;
- 安装remote-ssh, 用于连接公司的服务器;

安装完成后,点击左下角的远程连接,如下图所示:

此时,即可连接到WSL2 子系统。

打开Linux子系统的某个目录:这里以home目录下的用户目录(wsl_ubuntu)为例:确定目录后回车,即可打开对应目录:
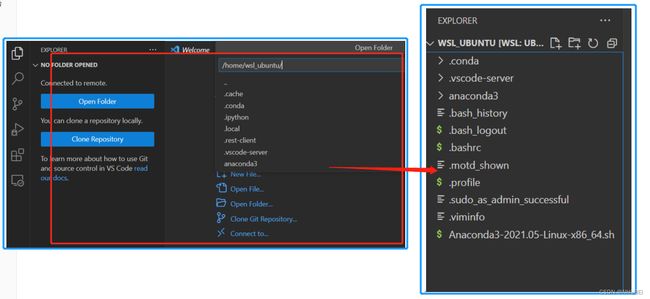
在打开的目录中,创建jupyter notebook文件,命名为Script_test.ipynb。如下图所示:

(6) 选择虚拟环境
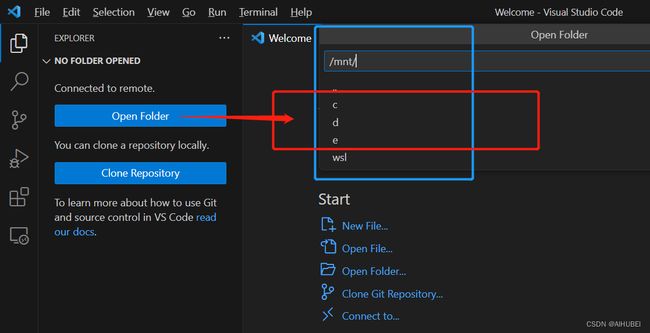
- 注意,此实例打开的是/home/wsl_ubuntu/目录,该文件夹位于Linux子系统的文件目录中,如下图:

- 如果此时需要在Windows系统中的盘符进行项目创建,需要在Open Folder的时候,进行切换,选中mnt,如下图,这里的C、D、E分别代表Windows本地磁盘,C盘,D盘,等;
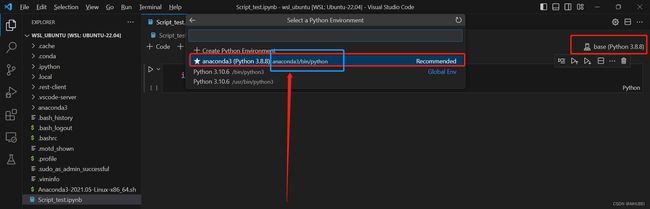
此时,所创建的Python文件还没有对应的虚拟环境提供Python解释器,我们点击右上角,select kernel,选择前面安装anaconda后提供的虚拟环境,如下图:
到此,我们实现了基于WSL2+Vscode的开发环境搭建。如若没有docker使用需求,即可结束配置步骤。上述执行效果如下:

第二部分:利用WSL2+Docker+Vscode搭建开发环境
考虑到Docker容器的便捷性与隔离性,这里进一步在WSL2安装docker及Nvidia docker toolkit。实现深度学习开发环境的容器化管理。具体地,我将通过Docker搭建起TensorFlow及Pytorch开发环境,因为不想麻烦地装cuda、cudnn等。相较之下,使用容器,这些东西都打包好了,直接用。
一个前提,得保证本地Windows物理机已经安装了较高版本的Nvidia Driver,如下图:

(1) 在WSL中安装docker及Nvidia docker toolkit
实际上,如果不是为了使用Nvidia官方提供的Pytorch和TensorFlow镜像,直接安装Docker就可以了。这里为了使用Nvidia提供的深度学习框架镜像,因此需要安装Nvidia docker toolkit。
- 安装Nvidia docker toolkit[可选步骤,可以直接跳过到docker安装步骤]。实际上就是安装了一些docker的插件吧。
安装命令来自官网,这里是地址,基于apt安装的具体过程如下:
# Step one: Configure the repository
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list \
&& \
sudo apt-get update
# Step two: Install the NVIDIA Container Toolkit packages.
sudo apt-get install -y nvidia-container-toolkit
这个过程比较简单,耐心安装完即可。
- 在WSL2的Ubuntu22.04中安装Docker,命令来自于Docker官网,注意查看支持的系统版本,具体如下:
# Step one: Uninstall old versions
for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done
# Step two: Set up Docker's official GPG key:
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get update
# Step three: Install the Docker packages.
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Step four: alternative to verify .
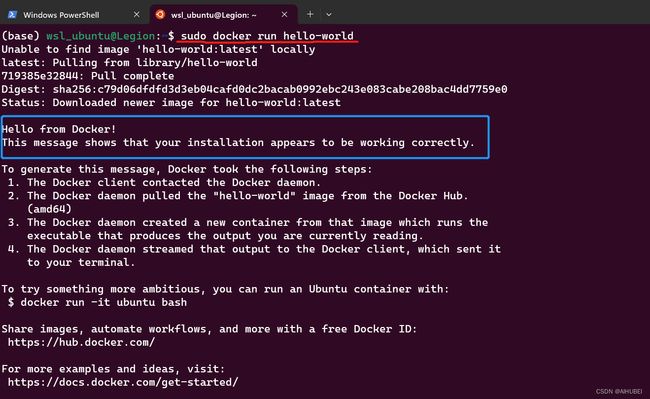
sudo docker run hello-world
到这一步就安装结束了。但没想到是的,出现了如下图所示“尴尬提示”。可以看出,查看docker 版本的时候,一切正常,然而,执行sudo docker run hello-world命令的时候,报错。
报错信息为:”“docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?.”

看起来像是说,我们的Docker没有启动。但是,实际发现通过service docker status启动后还是不行。如上图所示。这种情况在几个月前的另一台电脑上,没有出现。经过查找发现如下信息:

[此处感谢博友1:]: https://juejin.cn/post/7197594278083919932
[感谢博友2:]: https://www.cnblogs.com/towinar/p/17344345.html
因此,通过执行如下命令,上述问题得以解决。具体如下:
# Step one:
sudo update-alternatives --set iptables /usr/sbin/iptables-legacy
# Step two:
sudo update-alternatives --set ip6tables /usr/sbin/ip6tables-legacy
"""
该命令将 /usr/sbin/iptables-legacy 和 /usr/sbin/ip6tables-legacy 分别设置为 iptables 和 ip6tables 的备选方案.
"""
# Step three:
sudo service docker start
至此,Docker已经安装成功。如下图所示:

实际上,到这一步,我们的Docker和Nvidia Docker Toolkit都已经安装完成了。但是在基于WSL2的实际使用过程中我们发现一个“BUG”。如下图所示:


实际上,我们已经拉取过很多镜像到本地,但是通过命令查看结果显示,这里只有两个(对比与上图的客户端查看结果)。深度怀疑这是官方在搞鬼,大概就是强推客户端吧。
(2) 安装Docker Desktop[可选]
因此,为了折腾(配合命令行使用),进一步选择安装了Docker Desktop,即在Windows上安装Docker客户端。实际上我是拒绝的!这个过程简单,不做赘述!

至此,客户端安装完毕。日常的使用,通过命令行足以满足,但为了避免一些问题,还是配合客户端一起使用。
(3) 拉取目标Pytorch镜像文件
这里以Nvidia Pytorch镜像(网址:https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch)为例,拉取镜像,并创建容器,如下图所示:

# 根据Docker版本,选择安装命令。当前安装的Docker版本为24.0.7
# 命令中的xx.xx是容器的版本,例如:22.10
# Docker 19.03 or later, a typical command to launch the container is:
docker run --gpus all -it --rm nvcr.io/nvidia/pytorch:xx.xx-py3
# Docker 19.02 or earlier, a typical command to launch the container is:
nvidia-docker run -it --rm -v nvcr.io/nvidia/pytorch:xx.xx-py3
注意,这里需要考虑自己电脑已经安装的显卡驱动(Nvidia driver version)。建议安装比较新的显卡驱动,否则一些容器的功能会受限。当然,在选择容器版本之前,也可以考虑使用旧一点的容器版本。

我这里还是安装上一个电脑正在使用的版本,23.08。因此,结合使用端口映射等命令,对该版本的镜像文件拉取过程如下(简单起见,可以直接运行,本地没有找到的话,自动开始网络拉取):
# excute commands
sudo docker run --gpus all -it --rm -p 8888:8888 -v ~:/workspace \
--ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
nvcr.io/nvidia/pytorch:23.08-py3
# 拉取Nvidia Tensorflow镜像的命令类似
sudo docker run --gpus all -it --rm -p 8888:8888 -v ~:/workspace \
--ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \
nvcr.io/nvidia/tensorflow:23.08-py3
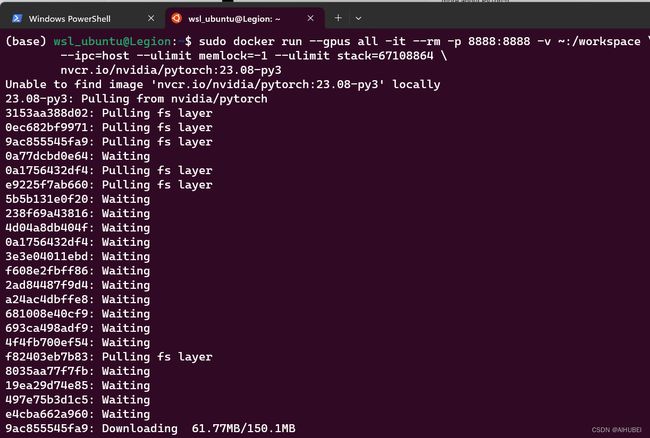
拉取完之后,便基于该镜像文件创建并启动了容器,如下图所示:
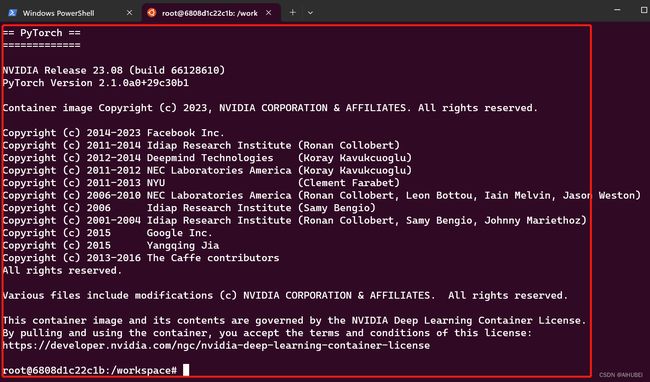
此时,我们就可以直接在这里输入 jupyter notebook,启动记事本了。对于TensorFlow也是一样的,无需手动安装cuda、cudnn等。进一步,查看是否可以获取到GPU,如下图:

没有问题。下面我将关闭所有打开的命令行,关闭上述运行的容器,从头使用Vscode,以及利用Vscode集成的终端,连接容器中的Pytorch开发环境,进一步测试安装是否成功!
(4) 在VScode中连接容器中的开发环境
- 启动Vscode,连接到WSL2并创建jupyter notebook文件。因为我们的容器环境在WSL2系统中。
# Script_test.
# Print the pytorch version.
import torch
print(torch.__version__)
# # Test the GPU is available or not.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device)
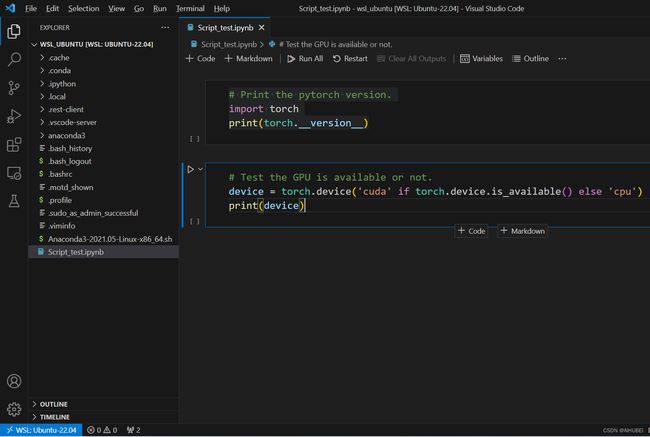
- 启动Vscode集成终端,基于上述拉取的Pytorch镜像创建容器,同时启动jupyter notebook服务,如下图:
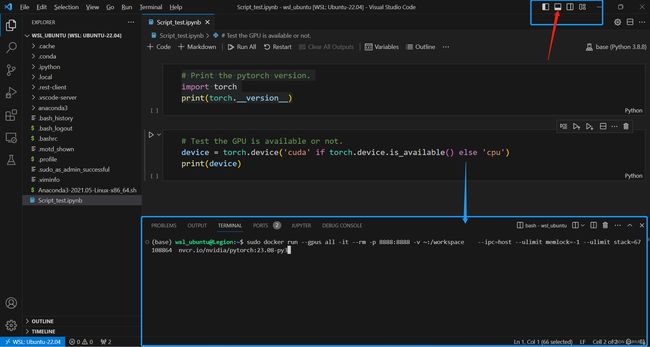
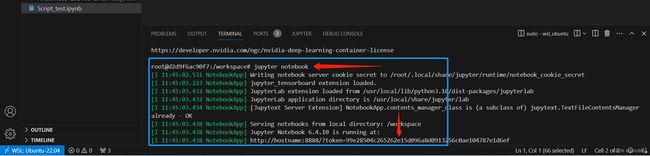
jupyter notebook服务已经启动,如下图所示的访问地址:
- 更改当前jupyter notebook的kernel,并连接到当前运行在容器里面的jupyter服务器,如下图:
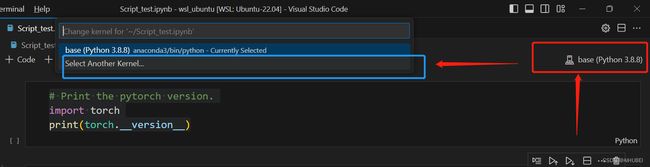

选择Existing Jupyter Server, 输入上述所启动的Jupyter notebook访问地址,【http://hostname:8888/?token=99e28504c265262e15d096a8d0913256c0ae104787e1d6ef】,并将hostname修改为localhost,回车即可。此时,当前记事本的kernel已经变更为Python 3(ipykernel):

至此,基于WSL2+Docker+VScode的机器学习(深度学习)环境配置结束。
参考链接
[1] 关于ubuntu安装后,启动报错"WslRegisterDistribution failed with error" 的解决方案:参照 https://github.com/microsoft/WSL/issues/5393 和 https://learn.microsoft.com/zh-cn/windows/wsl/install-manual#step-4—download-the-linux-kernel-update-package 。
[2] 关于启动Docker后,提示报错“docker: Cannot connect to the Docker daemon at unix:///var/run/docker.sock. Is the docker daemon running?.”,参照 https://stackoverflow.com/questions/57267776/why-is-the-docker-service-stopping 。