【论文】MCAN
【论文】zhou Yu, Jun Yu, Yuhao Cui, Dacheng Tao, and Qi Tian. Deep modular co-attention networks for visual question answering. (pdf)
What is MCAN
MCAN 主要工作可以总结为下面两点:
- 模仿 transformer 设计了两个注意力单元作为 Modular Co-Attention(MAC) layer 的基本组成元件—— general attention units 和 self-attention unit, 通过 GA unit 实现问题对图像注意的引导,SA unit 则主要对模态内的交互进行建模
- 通过 MAC layer 堆叠形成 deep co-attention model 实现对视觉内容和文本内容的细粒度理解
从 MCAN 的工作内容也很容易看出作者的 motivation —— 现有 co-attetnion learning 不足。之前的 co-attention learning 只在浅层模型中实现,即使通过串联形成深层的 co-attention model 性能提升却并不显著。这样的注意力机制只能够学习到不同模态之间粗糙的交互,也不够进行图像和问题关键词的关系推断。于是,作者提出了 MCAN,a deep Modular Co-Attention Network
Modular Co-Attention Layer
Self-Attention and Guided-Attention Units
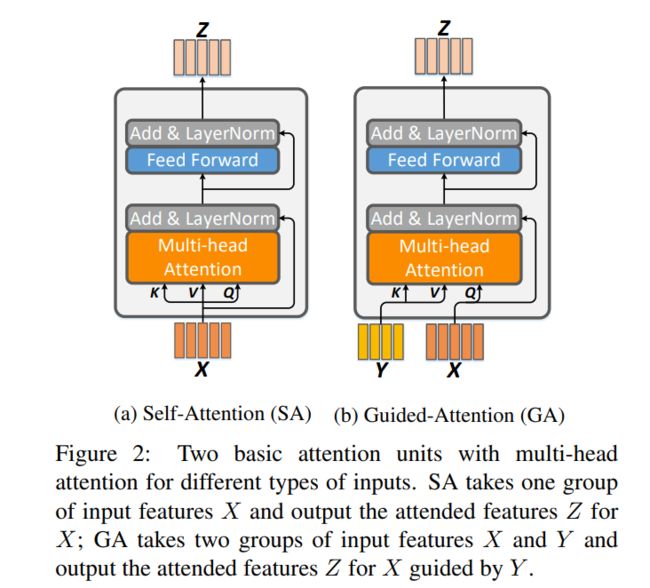
受 transformer 中注意力模块单元的启发,作者设计了如下两个类似的注意力单元作为 MCA layer 的基础组成元件
- SA unit 作为自注意模块, 输入一组输入特征 X = [ x 1 ; ⋯ ; x m ] ∈ R m × d x X=[x_1;\cdots;x_m]\in\mathbb R^{m\times d_x} X=[x1;⋯;xm]∈Rm×dx,multi-head attention 学习 X X X 中样本对 < x i , x j >
- GA unit 作为 co-attention 模块,输入两组特征 X X X 和 Y = [ y 1 ; ⋯ ; y m ] ∈ R n × d y Y=[y_1;\cdots;y_m]\in\mathbb R^{n\times d_y} Y=[y1;⋯;ym]∈Rn×dy, Y Y Y 用于引导 X X X 的注意学习。 X , Y X,Y X,Y 的形式不固定可以表示任何不同的模态特征,这里multi-head attention 学习的就是两个模态的样本对 < x i , y j >
Modular Composition for VQA
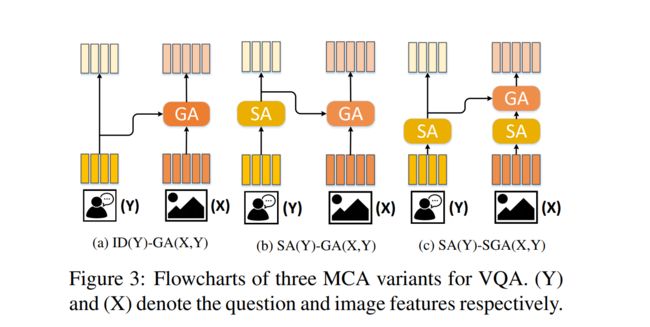
MCA layer 有三种变体将两个注意力单元结合起来:
- ID (Y) - GA (X, Y) 中输入的问题特征直接恒等映射到输出特征,在 GA (X, Y) unit 中将每个图像区域 x i x_i xi 和每个单词 y i y_i yi 结合产生 attended image feature
- SA (Y) - GA (X, Y) 在 ID (Y) - GA (X, Y)的基础上添加了对问题的自注意力学习,关注问题中单词之间的关系 { y i , y j } ∈ Y \left\{y_i,y_j\right\}\in Y {yi,yj}∈Y
- SA (Y) - SGA (X, Y) 在 SA (Y) - GA (X, Y) 的基础上添加了图像区域的自注意力学习,关注图像区域之间的关系 { x i , x j } ∈ X \left\{x_i,x_j\right\}\in X {xi,xj}∈X
Modular Co-Attention Networks
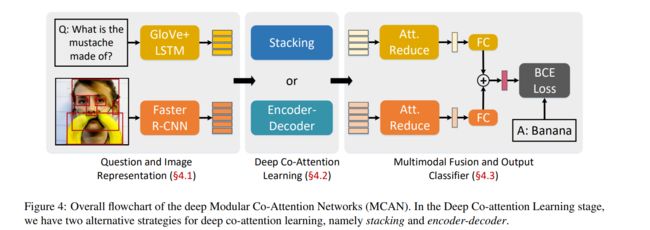
整个网络如下图所示,分为了三个模块,下面将分别介绍每个模块的详细内容。由于 Deep Co-Attention Learning 有两种方式,对采用 stacking 结果的 L L L 层 MAC 的模型称为 MCANsk-L,采用 encoder-decoder 结构的模型称为 MCANed-L
Question and Image Representations
与之前的工作一样使用 Faster RCNN 提取视觉特征, x i ∈ R d x x_i\in\mathbb R^{d_x} xi∈Rdx 表示第 i i i 个物体。不同的是,作者对检测到物体的概率设定了一个置信度阈值,这样检测到的物体数量就不是固定的, m ∈ [ 10 , 100 ] m\in[10,100] m∈[10,100]。最终图像的特征矩阵为 X ∈ R m × d x X\in\mathbb R^{m\times d_x} X∈Rm×dx
将问题拆分为 n n n 个单词后分别经过 Glove word embedding 和具有 d y d_y dy 个隐藏单元的单层 LSTM ,保留所有单词的输出构成问题的特征矩阵 Y ∈ R n × d y Y\in\mathbb R^{n\times d_y} Y∈Rn×dy
为了处理 m , n m,n m,n 不固定的问题,使用 zero-padding 将 X 、 Y X、Y X、Y 填充到最大长度 m = 100 , n = 14 m=100,n=14 m=100,n=14
Deep Co-Attention Learning
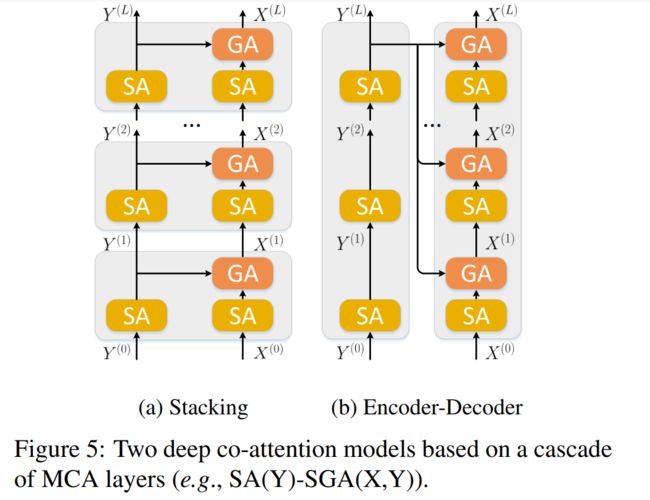
首先,deep co-attention model 由 L L L 层 MAC layer 堆叠而成,即满足 [ X ( l ) , Y ( l ) ] = M C A ( l ) ( [ X ( l − 1 ) , Y ( l − 1 ) ] ) [X^{(l)},Y^{(l)}]=MCA^{(l)}\left([X^{(l-1)},Y^{(l-1)}]\right) [X(l),Y(l)]=MCA(l)([X(l−1),Y(l−1)])
这里有两种构成方式,如下图所示
Multimodal Fusion and Output Classifier
记 deep co-attention model 的输出分别为 X ( L ) = [ x 1 ( L ) , ⋯ , x m ( L ) ] X^{(L)}=\left[x_1^{(L)},\cdots,x_m^{(L)} \right] X(L)=[x1(L),⋯,xm(L)] 和 Y ( L ) = [ y 1 ( L ) , ⋯ , y n ( L ) ] Y^{(L)}=\left[y_1^{(L)},\cdots,y_n^{(L)} \right] Y(L)=[y1(L),⋯,yn(L)],接着两个输出都会经过一个 attention reduction model 最终输出 x ~ \tilde x x~ 和 y ~ \tilde y y~,该模型由两层的 MLP 构成( FC (4 d d d) - ReLU - Dropout (0.1) - FC (1) )
以 X ( L ) X^{(L)} X(L) 为例,
α = s o f t m a x ( M L P ( X ( L ) ) ) x ~ = ∑ i = 1 m α i x i ( L ) \alpha=softmax(MLP(X^{(L)}))\\ \tilde x=\sum_{i=1}^m\alpha_ix^{(L)}_i α=softmax(MLP(X(L)))x~=i=1∑mαixi(L)
y ~ \tilde y y~ 同理,然后两者一起输入到一个线性的多模态融合函数中
z = L a y e r N o r m ( W x T x ~ + W y T y ~ ) z=LayerNorm(W^T_x\tilde x+W^T_y\tilde y) z=LayerNorm(WxTx~+WyTy~)
其中, W x T , W y T ∈ R d × d z W^T_x,W^T_y\in\mathbb R^{d\times d_z} WxT,WyT∈Rd×dz 表示两个可学习的权重矩阵
最后,使用 binary cross-entropy(BCE)损失在融合特征 z z z 上训练一个 N-way 分类器
Experiments
下图是论文中一些消融实验的结果
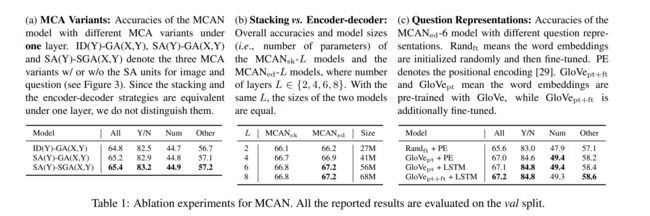
下图展示了 MCA layer 三种变体在 VQA 子任务上的表现
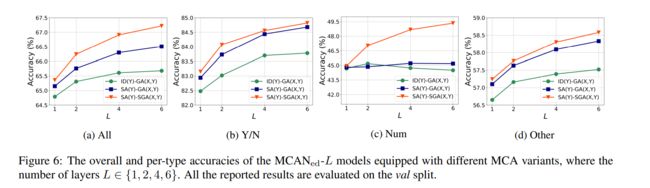
下图可视化了 MCANsk-6 和 MCANed-6 的注意力分布
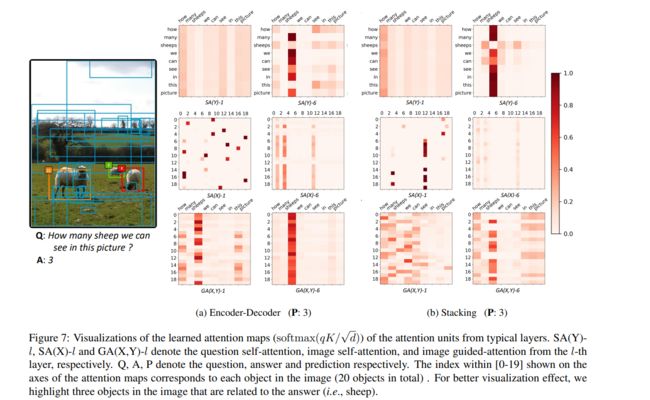
下图展示了一些图像和文本 co-attention 的例子,其实这里有一个非常有意思的问题,要区分黑莓手机还是诺基亚,或者要区分击球手还是捕手,这类的 co-attention learning 或多或少依赖属于数据集对他们的区分,或者需要借鉴外部知识

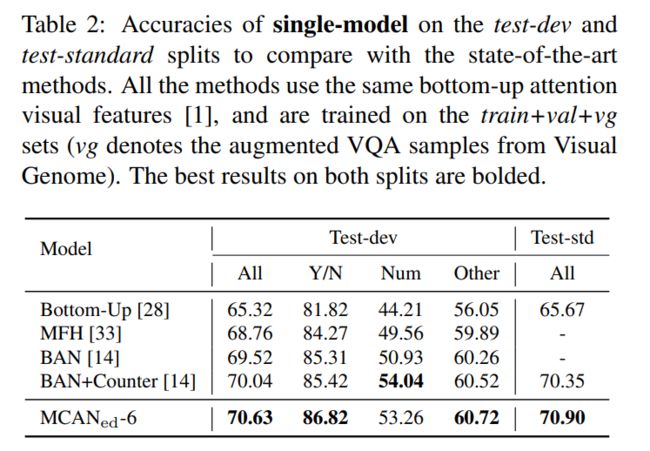
下图是 MCAN 和其他一些比较新的 VQA 模型性能的比较
Referrence
- 用于视觉问答的深度模块化共同注意网络 《Deep Modular Co-Attention Networks for Visual Question Answering》