Selenium自动化模块:在爬虫中的基础运用,ActionChains动作链:基础运用
文章目录
-
-
- Selenium自动化模块
-
- Selenium是什么?为什么要应用在爬虫中?应用场景是什么?
- 如何使用Selenium(附两个案例源码)
- ActionChains动作链
-
- 什么是ActionChains?用于解决什么问题?(附案例)
- 补充Selenium创建谷歌无头浏览器并进行截屏操作
-
Selenium自动化模块
Selenium是什么?为什么要应用在爬虫中?应用场景是什么?
Selenium是什么:
- selenium是一个基于浏览器自动化的模块,我们可以编写代码来制定相关的行为动作然后让这些行为动作映射在浏览器当中,一般用于自动化测试,那么我们为什么要应用在爬虫中呢?
为什么要应用在爬虫中(与爬虫之间的关联):
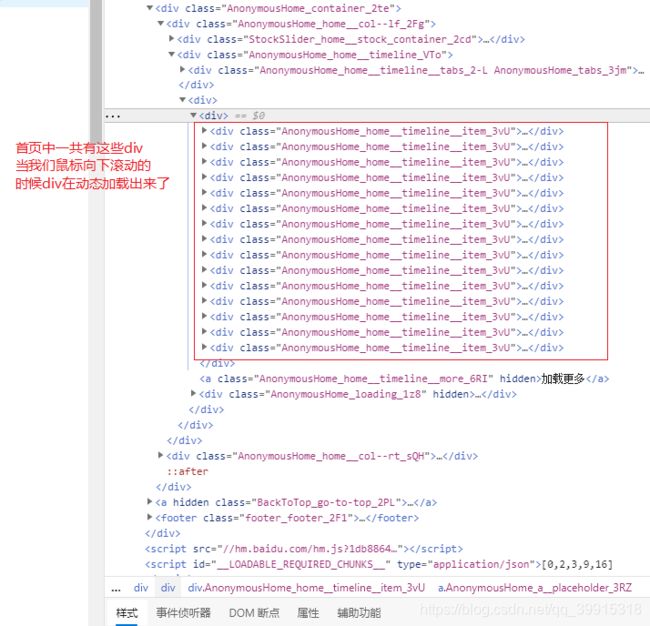
- 当我们在对一个网站发起request请求要捕获该网站的数据的时候,我们首先要判断该数据是不是动态加载的。
如果不是动态加载的数据那就好办了,直接用BeautifulSoup,或者xpath进行数据提取就好了。
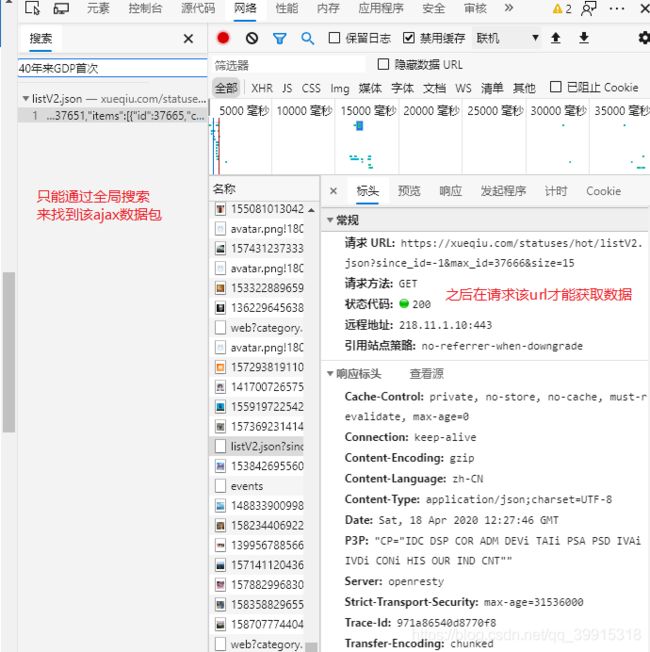
但是如果是动态加载的数据的话那么我们就不能简单的通过初始的请求url来获取数据,只能通过对存储数据的ajax数据包url发起请求来获取想要的数据了。
也就是说通过普通的request请求拿到的源码很有可能不包含我们想要的数据,无法实现可见即可得,但是Selenium可以实现可见即可得
应用场景:
- 当出现大量动态加载的数据的时候,我们感觉破解非常麻烦,就可以尝试使用Selenium进行破解,轻而易举的获取数据
弊端:
- Selenium这么强大,那么我们为什么还要一直用request来获取数据呢?
因为Selenium相比较request比较慢,你request1 秒钟发起10次请求,Selenium还要打开浏览器然后找到对应网页然后在获取数据就非常的慢了(所以只应用在动态加载的数据非常多,你又无法简单破解并且又必须要得到的情况下)
动态加载数据图示:



一般获取动态数据的流程是:
如何使用Selenium(附两个案例源码)
首先进行环境安装
pip install selenium
然后准备好某一款浏览器的驱动程序,我使用的是谷歌的驱动程序
推荐一个网址:http://chromedriver.storage.googleapis.com/index.html
查看驱动和浏览器的映射关系:https://blog.csdn.net/huilan_same/article/details/51896672
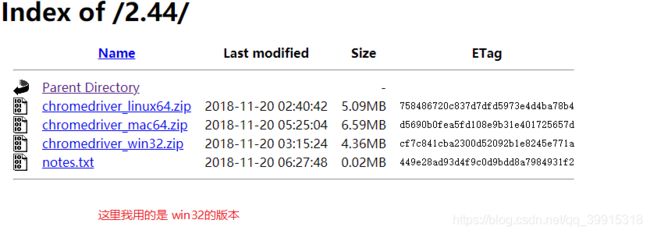
接下来上代码讲解:
自动打开百度搜索美女然后点击搜索后点击进入图片
from selenium import webdriver
from time import sleep
# 后面是你的浏览器驱动位置,记着前面加上r防止字符转义
# 如果驱动程序放入环境变量中就可以不写参数,但是我没配0.0
driver = webdriver.Chrome(executable_path='chromedriver.exe')
# 用get打开百度页面
driver.get('http://www.baidu.com')
# 查找页面的"设置"选项,并进行点击
driver.find_elements_by_link_text('设置')[0].click()
# 防止加载不出来停1秒
sleep(1)
# 点击搜索设置
driver.find_elements_by_link_text('搜索设置')[0].click()
sleep(1)
# 选中每页显示50条数据
m = driver.find_element_by_id('nr')
sleep(1)
m.find_element_by_xpath('//*[@id="nr"]/option[3]').click()
m.find_element_by_xpath('.//option[3]').click()
sleep(1)
# 点击保存设置
driver.find_elements_by_class_name("prefpanelgo")[0].click()
sleep(1)
# 处理弹出的警告页面,点击确定是accept() 点击取消dismiss()
driver.switch_to_alert().accept()
sleep(1)
# 找到百度的输入框,并输入 美女 也可以用xpath来做
driver.find_element_by_id('kw').send_keys('美女')
sleep(2)
# 点击搜索按钮进行跳转页面
driver.find_element_by_id('su').click()
# 注意一定要防止页面没加载出来
sleep(2)
# 在打开的页面中找到美女_海量精选高清图片_百度图片并逐个点击'
driver.find_element_by_xpath('//*[@id="1"]/h3/a').click()
sleep(1)
然后点击运行,就可以看到效果了
Selenium支持xpath解析但是你要确定你安装了lxml
pip install lxml
如何操作已经在代码注释中解释了,就不在赘述
这里补充几个方法:
一下方法都简历在创建好了浏览器实例的情况下
即driver = webdriver.Chrome(executable_path=‘chromedriver.exe’)
- driver.page_source 用于返回浏览器当前页面显示的源码
可以用作xpath中etree.HTML()使用 - driver.execute_script()用与进行js注入,
execute_script(‘window.scrollTo(0,document.body.scrollHeight)’)
window.scrollTo(x,y) x:向左右滑动x像素 y向上下滑动y像素,
document.body.scrollHeight是自动计算出到底部的距离,最终实现效果是滑动到底部 目的:让动态数据全部加载到html源码中,之后在通过page_source获取就可以解决动态加载数据的问题了,即可见即可得
实际案例:
自动打开京东搜索有滑动到屏幕最底部
from selenium import webdriver
from time import sleep
#1.基于浏览器的驱动程序实例化一个浏览器对象
# 如果驱动程序放入环境变量中就可以不写参数,但是我没配0.0
bro = webdriver.Chrome(executable_path='chromedriver.exe')
# 对目的网站发起请求(用浏览器发起,就是你的驱动程序)
bro.get('https://www.jd.com/')
# 我想在京东的搜索框中录入一个东西点击搜索
# 先定位到搜索框
search_text = bro.find_element_by_xpath('//*[@id="key"]')
search_text.send_keys('苹果') # 向标签中录入数据
# 定位到搜索按钮
btn = bro.find_element_by_xpath('//*[@id="search"]/div/div[2]/button')
btn.click() # 模拟鼠标单击一下
sleep(1) # 停2S
# 在搜索结果页面进行滚轮向下滑动的操作(执行JS操作:js注入)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
bro.execute_script('window.scrollTo(0,document.body.scrollHeight)')
输出源码
print(bro.page_source)
# 2s后关闭浏览器
sleep(2)
ActionChains动作链
什么是ActionChains?用于解决什么问题?(附案例)
- ActionChains动作链:一系列连续的动作(点击,多次点击,滑动等)
- 解决的问题:爬虫中会有很多种类型的验证码有的是输入文字数字或者回答问题,有的则是模拟真人进行点击滑动等操作


动作链可以在基于Selenium自动化的情况下模拟真人解决验证码问题(Selenium也可以自动输入账号密码,最终目的:实现模拟登陆)
实际案例:
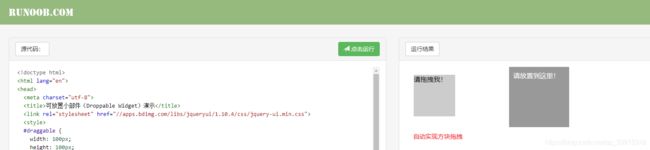
# 动作链:一系列连续的动作(滑动动作)
from selenium.webdriver import ActionChains
from selenium import webdriver
from time import sleep
url = 'https://www.runoob.com/try/try.php?filename=jqueryui-api-droppable'
bro = webdriver.Chrome(executable_path='chromedriver.exe')
bro.get(url)
sleep(1)
# 如果通过find系列的函数进行标签定位发现标签是存在
# 与iframe(第二窗口)下面,就会定位失败
# 解决方案使用switch_to即可
bro.switch_to.frame('iframeResult')
div_tag = bro.find_element_by_xpath('//*[@id="draggable"]')
# 对div_tag进行滑动操作
action = ActionChains(bro) # 选中的对象是bro 浏览器打开的对象
action.click_and_hold(div_tag)# 单击且长按 这样才能滑动
for i in range(6):
# perform让动作链立即执行
action.move_by_offset(10,15).perform()#右下10,15像素
sleep(0.5)
action.release() # 松开长按
补充Selenium创建谷歌无头浏览器并进行截屏操作
无头浏览器即无界面浏览器,我们在请求数据的时候有时并不需要看到打开浏览
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
# 创建一个参数对象,用来控制chrome以无界面模式打开
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
# 创建浏览器对象
browser = webdriver.Chrome(executable_path='chromedriver.exe', chrome_options=chrome_options)
# 上网
browser.set_window_size(1920, 1080)
browser.get('http://www.baidu.com/')
time.sleep(3)
# 进行截屏并保存图片到本地
browser.save_screenshot('baidu.png')
# 输出源码
print(browser.page_source)
# 关闭浏览器
browser.quit()
以上就是Selenium模块和ActionChains的基础运用了,复杂的运用正在研究中,如有问题欢迎指出