大数据集群高可用组建搭建部署
大数据集群高可用安装部署包有:
redis-3.2.10.tar.gz
spark-2.2.0-bin-hadoop2.7.tgz
hbase-1.2.1-bin.tar.gz
hadoop-2.8.1.tar.gz
apache-hive-1.2.1-bin.tar.gz
kafka_2.11-0.8.2.2.tgz
apache-flume-1.6.0-bin.tar.gz
zookeeper-3.4.6.tar.gz
MySQL-5.6.26-1.linux_glibc2.5.x86_64.rpm-bundle.tar
jdk-8u152-linux-x64.tar.gz
jce_policy-8.zip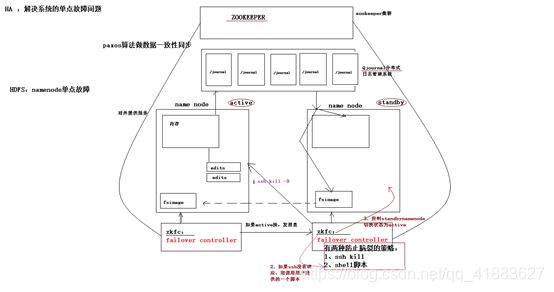
1.修改linux主机名
2.修改IP
3.修改主机名和IP的映射关系 /etc/hosts
租用的服务器或是使用的云主机(如华为用主机、阿里云主机等)
/etc/hosts里面要配置的是内网IP地址和主机名的映射关系
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
7:各主要端口
Journalnode:8485
spark:8080
nn:50070
dn:50075
yarn:8088
zk:2181
HM:16000
hb:9000
集群规划:
主机名 IP 运行的进程
hadoop00 xxx NameNode、DFSZKFailoverController(zkfc)、Hregionserver、Hmaster、redis
hadoop01 xxx NameNode、DFSZKFailoverController(zkfc)、redis
hadoop02 xxx ResourceManager、hiveserver2、mysql、flume、master、work、redis
hadoop03 xxx ResourceManager、hiveserver2、flume、master、work、redis
hadoop04 xxx DataNode、NodeManager、hive、flume、work、hiveserver2、kafka、redis
hadoop05 xxx DataNode、NodeManager、JournalNode、QuorumPeerMain、Hregionserver、kafka
hadoop06 xxx DataNode、NodeManager、JournalNode、QuorumPeerMain、Hregionserver、kafka
hadoop07 xxx DataNode、NodeManager、JournalNode、QuorumPeerMain、Hregionserver、kafka说明:
hadoop2.0官方提供了两种HDFS HA的解决方案,一种NFS,另一种是QJM。这里我们使用简单QJM。在该方案中,主备NameNode之间通过一JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。通常配置奇数个JournalNode
这里还配置了一个zookeeper集群用于ZKFC( DFSZKFailover
Controller)故障转移,当Active的NameNode挂掉了,会自动切换Standby NameNode为standby状态
2.hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.6.4解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调
安装步骤:
1.安装配置zooekeeper集群(在hadoop05,06,07上)
1.1解压
tar -zxvf zookeeper-3.4.5.tar.gz -C /home/hadoop/app/1.2修改配置
cd /home/hadoop/app/zookeeper-3.4.5/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg修改
:dataDir=/home/hadoop/app/zookeeper-3.4.5/tmp在最后添加:
server.1=hadoop05:2888:3888
server.2=hadoop06:2888:3888
server.3=hadoop07:2888:3888保存
退出
然后创建一个tmp文件夹
mkdir /home/hadoop/app/zookeeper-3.4.5/tmp
echo 1 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid1.3将配置好的zookeeper拷贝到其他节点(首先分别在hadoop06、hadoop07根目录下创建一个hadoop目录:mkdir /hadoop)
scp -r /home/hadoop/app/zookeeper-3.4.5/
hadoop06:/home/hadoop/app/
scp -r /home/hadoop/app/zookeeper-3.4.5/
hadoop07:/home/hadoop/app/
注意:修改hadoop06、hadoop07对应/hadoop/zookeeper-3.4.5/tmp/myid内容
hadoop06:
echo 2 > /home/hadoop/app/zookeeper-3.4.5/tmp/myidhadoop07:
echo 3 > /home/hadoop/app/zookeeper-3.4.5/tmp/myid启动zookeeper集群
zookeeper没有提供自动批量启动脚本,需要手动一台一台地起zookeeper进程
在每一台节点上,运行命令:
bin/zkServer.sh start启动后,用jps应该能看到一个进程:QuorumPeerMain
但是,光有进程不代表zk已经正常服务,需要用命令检查状态:
bin/zkServer.sh status能看到角色模式:为leader或follower,即正常了。
2.安装配置hadoop集群(在hadoop00上操作)
2.1解压
tar -zxvf hadoop-2.6.4.tar.gz -C /home/hadoop/app/2.2配置HDFS(hadoop2.0所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下)
#将hadoop添加到环境变量中
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_55
export HADOOP_HOME=/hadoop/hadoop-2.6.4
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/binhadoop2.0的配置文件全部在$HADOOP_HOME/etc/hadoop下
cd /home/hadoop/app/hadoop-2.6.4/etc/hadoop2.2.1修改hadoo-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_552.2.2修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://jike/</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hdptmp/</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop05:2181,hadoop06:2181,hadoop07:2181</value>
</property>
</configuration>2.2.3修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为bi,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>jike</value>
</property>
<!-- jike下面有两个NameNode,分别是nn1,nn2
-->
<property>
<name>dfs.ha.namenodes.</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.jike.nn1</name>
<value> hadoop01:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.jike.nn1</name>
<value> hadoop01:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.jike.nn2</name>
<value> hadoop02:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.jike.nn2</name>
<value> hadoop02:50070</value>
</property>
<!-- 指定NameNode的edits元数据在机器本地磁盘的存放位置 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hdpdata/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hdpdata/data</value>
</property>
<!-- 指定NameNode的共享edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal:// hadoop05:8485; hadoop06:8485; hadoop07:8485/jike </value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/root/hdpdata/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式
-->
<property>
<name>dfs.client.failover.proxy.provider.jike
</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>2.2.4修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 5修改yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的逻辑名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hadoop03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop04</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value> hadoop05:2181, hadoop06:2181, hadoop07:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>2.2.6修改slaves(slaves是指定子节点的位置,因为要在hadoop01上启动HDFS、在hadoop03启动yarn,所以hadoop01上的slaves文件指定的是datanode的位置,hadoop03上的slaves文件指定的是nodemanager的位置)
hadoop05
hadoop06
hadoop07
2.2.7配置免密码登陆
#首先要配置hadoop00到hadoop01、hadoop02、hadoop03、hadoop04、hadoop05、hadoop06、hadoop07的免密码登陆
#在hadoop01上生产一对钥匙
ssh-keygen -t rsa#将公钥拷贝到其他节点,包括自己
ssh-coyp-id hadoop00
ssh-coyp-id hadoop01
ssh-coyp-id hadoop02
ssh-coyp-id hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
ssh-coyp-id hadoop07#配置hadoop02到
hadoop04、hadoop05、hadoop06、hadoop07的免密码登陆
#在hadoop02上生产一对钥匙
ssh-keygen -t rsa#将公钥拷贝到其他节点
ssh-coyp-id
hadoop03
ssh-coyp-id hadoop04
ssh-coyp-id hadoop05
ssh-coyp-id hadoop06
ssh-coyp-id hadoop07#注意:两个namenode之间要配置ssh免密码登陆,别忘了配置hadoop01到hadoop00的免登陆
在hadoop01上生产一对钥匙
ssh-keygen -t rsa
ssh-coyp-id -i
hadoop00 2.4将配置好的hadoop拷贝到其他节点
scp -r /hadoop/ hadoop02:/
scp -r /hadoop/ hadoop03:/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hadoop04:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hadoop05:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hadoop06:/hadoop/
scp -r /hadoop/hadoop-2.6.4/ hadoop@hadoop07:/hadoop/
#注意:严格按照下面的步骤
2.5启动zookeeper集群(分别在hadoop05、hadoop06、hadoop07上启动zk)
cd /hadoop/zookeeper-3.4.5/bin/
./zkServer.sh start#查看状态:一个leader,两个follower
./zkServer.sh status2.6手动启动journalnode(分别在在hadoop05、hadoop06、hadoop07上执行)
cd /hadoop/hadoop-2.6.4
sbin/hadoop-daemon.sh start journalnode#运行jps命令检验,hadoop05、hadoop06、hadoop07上多了JournalNode进程
2.7格式化namenode
#在hadoop01上执行命令:
hdfs namenode -format#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/hadoop/hadoop-2.6.4/tmp,然后将/hadoop/hadoop-2.6.4/tmp拷贝到hadoop02的/hadoop/hadoop-2.6.4/下。
scp -r tmp/ hadoop02:/home/hadoop/app/hadoop-2.6.4/##也可以这样,建议hdfs
namenode -bootstrapStandby2.8格式化ZKFC(在hadoop01上执行即可)
hdfs zkfc -formatZK2.9启动HDFS(在hadoop00上执行)
sbin/start-dfs.sh2.10启动YARN(#####注意#####:是在hadoop02上执行start-yarn.sh,把namenode和resourcemanager分开是因为性能问题,因为他们都要占用大量资源,所以把他们分开了,他们分开了就要分别在不同的机器上启动)
sbin/start-yarn.sh到此,hadoop-2.6.4配置完毕,可以统计浏览器访问:
http://hadoop00:50070
NameNode ‘hadoop01:9000’ (active)
http://hadoop01:50070
NameNode ‘hadoop02:9000’ (standby)
验证HDFS HA
首先向hdfs上传一个文件
hadoop fs -put /etc/profile /profile
hadoop fs -ls /然后再kill掉active的NameNode
kill -9 <pid of NN>通过浏览器访问:http://hadoop00:50070
NameNode ‘hadoop02:9000’ (active)
这个时候hadoop02上的NameNode变成了active
在执行命令:
hadoop fs -ls /
-rw-r–r-- 3 root
supergroup 1926 2014-02-06 15:36
/profile
刚才上传的文件依然存在!!!
手动启动那个挂掉的NameNode
sbin/hadoop-daemon.sh start namenode通过浏览器访问:http://hadoop01:50070
NameNode ‘hadoop01:9000’ (standby)
验证YARN:
运行一下hadoop提供的demo中的WordCount程序:
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.1.jar
wordcount /profile /out测试集群工作状态的一些指令 :
查看hdfs的各节点状态信息
bin/hdfs dfsadmin -report 获取一个namenode节点的HA状态
bin/hdfs haadmin -getServiceStatenn1 单独启动一个namenode进程
sbin/hadoop-daemon.sh start namenode 单独启动一个zkfc进程
./hadoop-daemon.sh start zkfc Hive
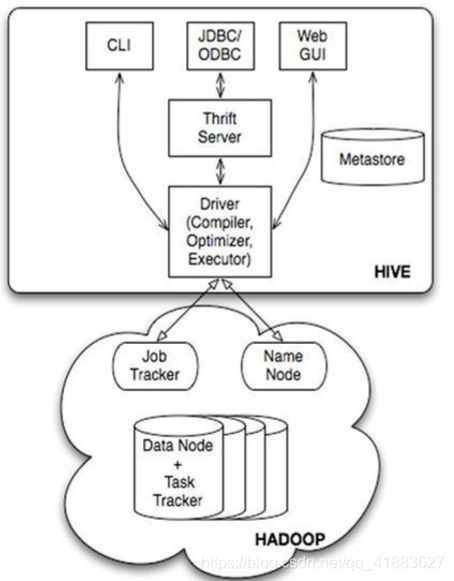
Hive 安装(1.2.1)
1Linux下Mysql数据库
删除原本依赖
rpm-e--nodeps`rpm-qa|grepMySQL` 然后 yum 在线安装 yuminstall-ymysql-server
启动 mysql 服务
sudoservicemysqldstart 初始化配置
mysql_secure_installation加入到开机启动项
chkconfigmysqldon 权限授予
grantallprivilegeson*.*to'root'@'%'identifiedby'root'; flushprivileges;2,解压一个 hive 安装包到集群的任意一台机器上
3,配置 hive 的目录到环境变量中
4,将 hive 的 lib 中的 jline.2.12.jar 替换掉 hadoop2.6.4/share/hadoop/yarn/lib/jline.0.94.jar
5,修改配置文件 在 hive的 conf 目录中
vi hive-site.xml<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop02:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBCconnectstringforaJDBCmetastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>DriverclassnameforaJDBCmetastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>usernametouseagainstmetastoredatabase</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>passwordtouseagainstmetastoredatabase</description>
</property>
</configuration>
数据库前提
1、远程连接 mysql 权限被拒绝时,先在 mysql
服务器上用客户端连上,
然后敲如下命令:
grantallprivilegeson*.*to‘root’@’%’identifiedby‘root 的密码’withgrantoption; flushprivileges;2、数据库的排序规则必须为 latin1
3、在 hive 的 lib 中放置一个 mysql 的 jdbc 驱动 jar
包
5、启动hive注意 :先保证你的hdfs和 yarn正常运行,hadoop已配置在环境变量中
否则:Cannot find hadoop
installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoopmustbeinthepath
启动命令:bin/hive 测试:showdatabases; showtables;
Thrift 服务端 JDBC 的方式
hive 启动 hiveThrift
服务端 (默认端口 10000,可通过 hive.server2.thrift.port 参数调整)
hive--servicehiveserver2 启动时指定端口
hive--servicehiveserver2--hiveconfhive.server2.thrift.port=10002 后台启动
nohup./hive--servicehiveserver2--hiveconfhive.server2.thrift.port=10002 &org.apache.hive.jdbc.HiveDriver
在 java 代码中调用 hive 的 JDBC 建立连接 url:
jdbc:hive2://mini3:10002/testbeeline 里连接
!connectjdbc:hive2://mini3:10002WebGUI 的方式
这里简单的说一下,WebGUI 的搭建和访问过程
1 、解压 hive 源码包
2进入 hwi 子目录 tar-zxvf apache-hive-0.14.0-src.tar.gz
3 、制作 war 包 jar -cvf Mhive-hwi-1.2.1.war -C web/.
4 、 拷 贝
hive-hwi-0.14.0.war 至 $HIVE_HOME/lib 目 录 cp hive-hwi-1.2.1.war$HIVE_HOME/lib
cp$JAVA_HOME/lib/tools.jar$HIVE_HOME/lib5 、修改
hive-site.xml 配置文件
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-1.2.1.war</value>
</property>5 、启动 hive,及其访问 nohup bin/hive–servicehwi &
访问地址:hadoop00:9999/hwi 执行查询 进入会话管理页面:
在 ResultFile 中填入结果保存文件;注意:这个文件必须存在。
在 Query 中填入要执行的 HQL 语句; StartQuery 选择 YES; 点击 Submit 开始执行 HQL 语句。
Hbase
解压hbase安装包
修改hbase-env.sh
export JAVA_HOME=/home/hadoop/app/jdk1.7.0_55
export HBASE_MANAGES_ZK=false(用自己的zk)修改hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop00:9000/hbase</value>
</property>
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop05:2181,hadoop06:2181,hadoop07:2181</value>
</property>
</configuration>修改 regionservers
hadoop00
hadoop05
hadoop06
hadoop07
启动hbase集群:
bin/start-hbase.sh启动完后,还可以在集群中找任意一台机器启动一个备用的master
bin/hbase-daemon.sh start master新启的这个master会处于backup状态
启动hbase的命令行客户端
bin/hbase shell
Hbase> list // 查看表
Hbase> status // 查看集群状态
Hbase> version // 查看集群版本
flume
解压包:
1、Flume的安装非常简单,只需要解压即可,当然,前提是已有hadoop环境
上传安装包到数据源所在节点上
然后解压 tar -zxvf apache-flume-1.6.0-bin.tar.gz
然后进入flume的目录,修改conf下的flume-env.sh,在里面配置JAVA_HOME
2、根据数据采集的需求配置采集方案,描述在配置文件中(文件名可任意自定义)
3、指定采集方案配置文件,在相应的节点上启动flume agent
先用一个最简单的例子来测试一下程序环境是否正常
在flume的conf目录下
vi netcat-logger.properties定义这个agent中各组件的名字
a1.sources = r1
a1.sinks = k1
a1.channels = c1
描述和配置source组件:r1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
描述和配置sink组件:k1
a1.sinks.k1.type = logger描述和配置channel组件,此处使用是内存缓存的方式
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
描述和配置source channel sink之间的连接关系
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1执行:
bin/flume-ng agent -c conf -f conf/netcat-logger.properties-n
a1 -D flume.root.logger=INFO,console-c conf 指定flume自身的配置文件所在目录
-f conf/netcat-logger.con 指定我们所描述的采集方案
-n a1 指定我们这个agent的名字
测试
先要往agent的source所监听的端口上发送数据,让agent有数据可采
随便在一个能跟agent节点联网的机器上
telnet anget-hostname port (telnet localhost 44444)spark
park-安装包到Linux上
解压安装包到指定位置
tar -zxvf spark-2.1.0-bin-hadoop2.6.tgz -C /usr/local配置Spark
进入到Spark安装目录
cd /usr/local/spark-2.1.0-bin-hadoop2.6进入conf目录并重命名并修改spark-env.sh.template文件
cd conf/
mv spark-env.sh.template spark-env.sh
vi spark-env.sh在该
配置文件中添加如下配置
export JAVA_HOME=/usr/java/jdk1.8.0_111
#export SPARK_MASTER_IP=hadoop02
#export SPARK_MASTER_PORT=7077保存
退出
重命名并修改slaves.template文件
mv slaves.template slaves
vi slaves在该文件中添加子节点所在的位置(Worker节点)
保存退出
将配置好的Spark拷贝到其他节点上
Spark集群配置完毕,目前是1个Master,3个Work,在hadoop02上启动Spark集群
/usr/local/spark-2.1.0-bin-hadoop2.6/sbin/start-all.sh启动后执行jps命令,主节点上有Master进程,其他子节点上有Work进行,登录Spark管理界面查看集群状态(主节点):http://hadoop02:8080/
到此为止,Spark集群安装完毕,但是有一个很大的问题,那就是Master节点存在单点故障,要解决此问题,就要借助zookeeper,并且启动至少两个Master节点来实现高可靠,配置方式比较简单:
Spark集群规划:hadoop02,hadoop03是Master;hadoop02,hadoop03,hadoop04是Worker
安装配置zk集群,并启动zk集群
停止spark所有服务,修改配置文件spark-env.sh,在该配置文件中删掉SPARK_MASTER_IP并添加如下配置
export
SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=zk1,zk2,zk3
-Dspark.deploy.zookeeper.dir=/spark"在
hadoop02节点上修改slaves配置文件内容指定worker节点
在hadoop02上执行sbin/start-all.sh脚本,然后在hadoop02上执行sbin/start-master.sh启动第二个Master
执行Spark程序
执行第一个spark程序
/usr/local/spark-2.1.0-bin-hadoop2.6/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop02:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/usr/local/spark-2.1.0-bin-hadoop2.6/lib/spark-examples-2.1.0-hadoop2.6.0.jar
\
100该算法是
利用蒙特·卡罗算法求PI
启动Spark Shell
spark-shell是Spark自带的交互式Shell程序,方便用户进行交互式编程,用户可以在该命令行下用scala编写spark程序。
启动spark shell
/usr/local/spark-2.1.0-bin-hadoop2.6/bin/spark-shell \
--master hadoop02\
--executor-memory 2g \
--total-executor-cores 2参数说明:
–master hadoop02 指定Master的地址
–executor-memory 2g 指定每个worker可用内存为2G
–total-executor-cores 2 指定整个集群使用的cup核数为2个
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
kafka
Broker : 安装Kafka服务的那台集群就是一个broker(broker的id要全局唯一)
Producer :消息的生产者,负责将数据写入到broker中(push)
Consumer:消息的消费者,负责从kafka中读取数据(pull),老版本的消费者需要依赖zk,新版本的不需要
Topic: 主题,相当于是数据的一个分类,不同topic存放不同的数据
Consumer Group: 消费者组,一个topic可以有多个消费者同时消费,多个消费者如果在一个消费者组中,那么他们不能重复消费数据
Spark Streaming 2.2.0兼容kafka 0.8.2.1以上的版本,主要支持0.8和0.10这两个版本
kafka集群安装
1.下载Kafka安装包
2.上传安装包
3.解压
4.修改配置文件 config/server.properties
broker.id=0
host.name=
log.dirs=/data/kafka
zookeeper.connect=hadoop05:2181,hadoop06:2181,hadoop07:21815.将配
置好的kafka拷贝到其他机器上
6.修改broker.id和host.name
7.启动kafka
/bigdata/kafka_2.11-0.8.2.2/bin/kafka-server-start.sh
-daemon /bigdata/kafka_2.11-0.8.2.2/config/server.properties#查看topic信息
/bigdata/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --list
--zookeeper hadoop02:2181,hadoop05:2181#创建topic
/bigdata/kafka_2.11-0.8.2.2/bin/kafka-topics.sh --create
--zookeeper hadoop02:2181,hadoop05:2181 --replication-factor 3 --partitions 3
--topic jike#往Kafka的topic中写入数据(命令行的生成者)
/bigdata/kafka_2.11-0.8.2.2/bin/kafka-console-producer.sh
--broker-list node-4:9092,hadoop06:9092,hadoop06:9092 --topic jike#启动消费者
/bigdata/kafka_2.11-0.8.2.2/bin/kafka-console-consumer.sh
--zookeeper hadoop02:2181,hadoop05:2181 --topic xiaoniu --from-beginningredis
1.xiazai
2.上传redis-3.2.10.tar.gz到服务器
3.解压redis源码包
tar -zxvf redis-3.2.10.tar.gz -C /usr/local/src/4.进入到源码包中,编译并安装redis
cd /usr/local/src/redis-3.2.10/
make && make install5.报错,缺少依赖的包
6.配置本地YUM源并安装redis依赖的rpm包
yum -y install gcc7.编译并安装
make && make install8.报错,原因是没有安装jemalloc内存分配器,可以安装jemalloc或直接输入
9.重新编译安装
make MALLOC=libc && make install10.用同样的方式在其他的机器上编译安装redis
11.在所有机器的/usr/local/下创建一个redis目录,然后拷贝redis自带的配置文件redis.conf到/usr/local/redis
mkdir /usr/local/redis
cp /usr/local/src/redis-3.2.10/redis.conf
/usr/local/redis
12.修改所有机器的配置文件redis.conf
daemonize yes #redis后台运行
cluster-enabled yes #开启集群把注释去掉
appendonly yes #开启aof日志,它会每次写操作都记录一条日志
sed -i 's/daemonize no/daemonize yes/'
/usr/local/redis/redis.conf
sed -i "s/bind 127.0.0.1/ bind $HOST/"
/usr/local/redis/redis.conf
sed -i 's/# cluster-enabled yes/cluster-enabled yes/'
/usr/local/redis/redis.conf
sed -i 's/appendonly no/appendonly yes/'
/usr/local/redis/redis.conf
sed -i 's/# cluster-node-timeout
15000/cluster-node-timeout 5000/' /usr/local/redis/redis.conf13.启动所有的redis节点
cd /usr/local/redis
redis-server redis.conf14.查看redis进程状态
ps -ef | grep redis15.(只要在一台机器上安装即可)配置集群:安装ruby和ruby gem工具(redis3集群配置需要ruby的gem工具,类似yum)
yum -y install ruby rubygems16.使用gem下载redis集群的配置脚本
gem install redis
ruby --version17.安装RVM
curl -sSL https://rvm.io/mpapis.asc | gpg2 --import -
curl -L get.rvm.io | bash -s stable
source /usr/local/rvm/scripts/rvm
rvm list known
rvm install 2.3.4#用ruby的工具安装reids
gem install redis18.使用脚本配置redis集群
cd /usr/local/src/redis-3.2.10/src/#service iptables stop#在第一机器上执行下面的命令
./redis-trib.rb create --replicas 1 xxx xxx xxx xxx19.测试(别忘加-c参数)
redis-cli -c -h 192.168.1.13