单向链表详解

文章目录
- 前言
- 链表的概念
-
- 定义一个节点
- 打印链表
- 头插数据
- 尾插数据
- 尾删数据
- 头删数据
- pos位置前面插入数据
- pos位置后面插入数据
- pos位置删除节点
- pos位置后面删除节点
前言
链表是一种常见而重要的基础数据结构,它弥补了顺序表遇到的一些问题。
我们知道顺序表是一块连续的物理空间,它会导致一下三个问题。
- 中间/头部的插入或删除数据,时间复杂度为o(N)
- 增容的时候如果后面的那块空间被占用了或者后面的空间不够,需要重新申请一块新空间,需要拷贝数据,释放旧空间,会有不小的消耗。
- 增容很不灵活。如果增容的空间大,需要重复申请会造成浪费。或者如果需要的空间小,又会造成一定空间的浪费。
于是根据上面的问题,我们在此之上想出一些改善的方法:
一小块一小块申请空间,通过这样来独立存储每个数据,然后不够了就申请,达到按需申请释放,空间不够也不需要扩容。特点就是不连续。头部插入和删除数据也不需要挪动数据。
这一小块的空间我们也叫做节点。

节点之间怎么管理呢?
首先想到的就是有一个指针指向第一个节点,但是节点之间不连续怎么办呢?可以这样,每个节点可以存储指向下一个节点的地址,这样就可以通过上一个节点指向下一个节点。

上面我们只是讲了一下链表大概是怎么来的,链表大概长什么样。下面我们进入正文。
链表的概念
链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的 。
简单来说链表是在逻辑上连续的,但是在真实的内存当中存储是非连续的,它通过每个节点内存储下一个节点的指针然后可以依次访问来实现逻辑上的连续。
定义一个节点
typedef int SLDataType;
typedef struct SLNode
{
int data;
struct SLNode* next;
}SLN
上面已经知道链表的大概结构,每一小块空间不仅仅包括存储数据,还应该存储下一个节点的地址,所以我们可以通过定义一个结构体创建节点。

打印链表
void SLPrint(SLN* phead)
{
SLN* cur=phead;
while(cur!=NULL)
{
printf("%d->", cur->data);
cur=cur->next;
}
printf("NULL\n");
}
因为每个节点都保存着指向下一个节点的地址,我们知道第一个节点的地址,可以通过第一个节点找到下一个节点的地址,然后依次循环可以找到链表的所有节点。
创建了一个cur指针变量是用来拷贝下一个节点的地址。
phead要不要断言:
具体场景具体分析,这里其实不用断言,如果plist为NULL,直接就不进入循环。
注意:因为打印链表不需要改变链表头节点的指针,所以函数在传参的时候只需要传头节点的指针。
头插数据
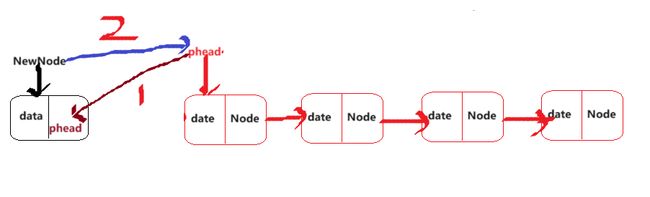
void SLPushFront(SLN** pphead, SLDataType x)
{
assert(pphead!=NULL);
//先开辟一个节点
SLN* NewNode=(SLN*)malloc(sizeof(SLN));
if (NewNode == NULL)
{
perror("malloc fail");
return;
}
NewNode->data = x;
NewNode->next = NULL;
//链接
NewNode->next = *pphead;
*pphead = NewNode;
}
注意:不能直接定义一个节点,因为这是局部变量,出了作用域就自动销毁了。
而mallloc()不一样,只有free掉才会销毁。
还有一个特别指的注意的点,看下面的一段有错误的代码:

因为是传值调用,形参是实参的一份临时拷贝,所以phead的改变不会改变plist,所以会对空指针进行解引用操作。
总结:如果要改变结构体的指针,所以要传结构体指针的地址。
相反,如果知识要改变结构体,那就传结构体指针。
要不要断言:
pphead:因为就算plist为NULL,pphead也不为NULL,所以一定要断言。
phead:空链表也可以头插数据,所以不用断言。
尾插数据
非空链表
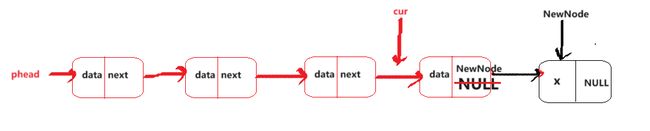
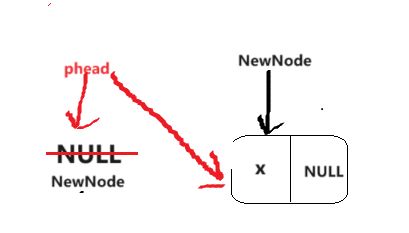
空链表
void SLPushBack(SLN** pphead, SLDataType x)
{
//首先开辟一个节点
SLN* NewNode=(SLN*)malloc(sizeof(SLN));
if (NewNode == NULL)
{
perror("malloc fail");
return;
}
NewNode->data = x;
NewNode->next = NULL;
//链接
//第一种情况,非空链表,改变结构体
//第二种情况,空链表,改变结构体指针
SLN* tail = *pphead;
if ((*pphead)->next == NULL)
{
*pphead = NewNode;
}
else
{
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = NewNode;
}
这里在链接的时候分为两种情况:
如果是空链表的话,改变的是结构体指针,所以在函数传参的时候要用传址调用。
如果是非空链表 的话,链接的时候更改的是上一个节点的Next,要改变的是结构体。
尾删数据
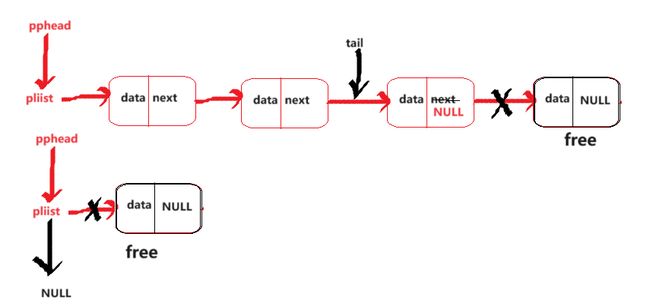
void SLPopBack(SLN** pphead)
{
assert(*pphead != NULL);
//只有一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
else
{
//有多个节点
SLN* tail = *pphead;
SLN* prev = NULL;
//把最后一个节点释放
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
tail = NULL;
//链接
prev->next = NULL;
}
}
SLN* SLFind(SLN* phead, SLDataType x)
{
SLN* cur = phead;
SLN* pos = NULL;
while (cur != NULL)
{
if (cur->data==x)
{
pos = cur;
return pos;
}
cur = cur->next;
}
return NULL;
}
首先它分两种情况,思路如图所示
一种就是有多个节点,在尾删要改的是结构体里的成员
另一种只有一个节点
这个时候需要改变的是结构体指针
头删数据
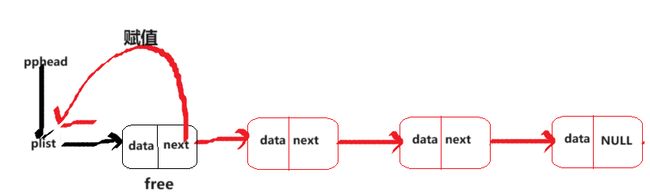
void SLPopFront(SLN** pphead)
{
assert(*pphead != NULL);
SLN* tmp = *pphead;
*pphead = (*pphead)->next;
free(tmp);
tmp = NULL;
}
因为头删数据只涉及到改变结构的指针,所以一种情况就可以了。
pos位置前面插入数据
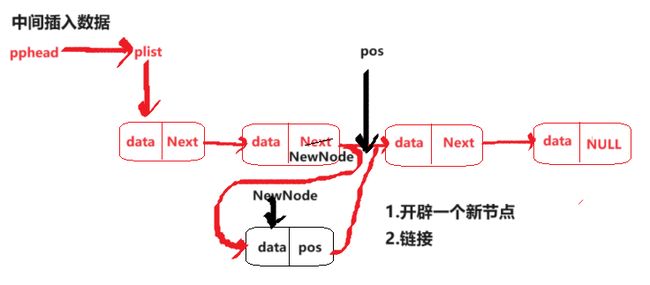
{
assert(*pphead);
//开辟一个新的节点
SLN* NewNode = (SLN*)malloc(sizeof(SLN));
if (NewNode == NULL)
{
perror("malloc fail");
return;
}
NewNode->data = x;
//链接
if (pos->next == NULL)
{
*pphead = NewNode;
(*pphead)->next = pos;
}
else
{
NewNode->next = pos;
SLN* tail = *pphead;
while (tail->next != pos)
{
tail = tail->next;
}
tail->next = NewNode;
}
}
还是从要不要改变 结构体的指针分为两种情况
1.pos指向的不是第一个节点
2.pos指向的是第一个节点,这里有个坑,如果还是用第一种情况的做法,那tail->next永远也找不到pos;
可以思考一个问题,如果没有plist那怎么插入?
pos位置后面插入数据
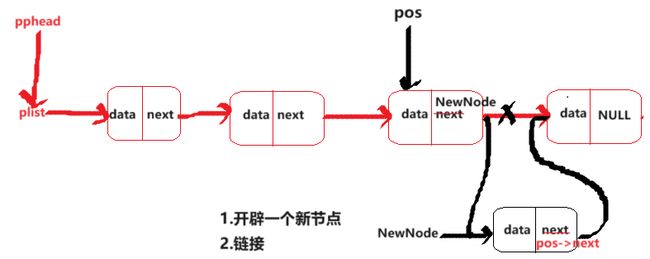
void SLBehindInsert(SLN* phead, SLN* pos, SLDataType x)
{
assert(pos != NULL);
SLN* NewNode=(SLN*)malloc(sizeof(SLN));
if (NewNode == NULL)
{
perror("malloc fail");
return;
}
NewNode->data = x;
NewNode->next = NULL;
//链接
SLN* tmp = pos->next;
pos->next = NewNode;
NewNode->next = tmp;
}
pos位置删除节点
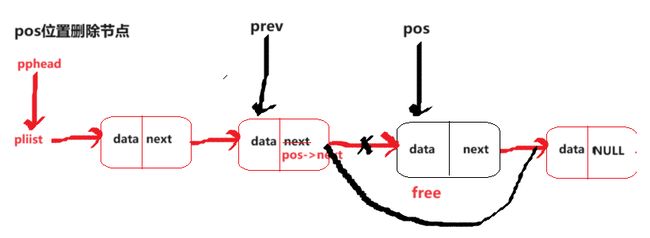
void SLErase(SLN** pphead, SLN* pos)
{
assert(pos != NULL);
assert(*pphead != NULL);
if (pos==*pphead)
{
SLPopFront(pphead);
}
else
{
SLN* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
这里还是根据要不要 改变头节点的指针分为两种情况,如果要改的是头节点的指针的话,那就要传头节点指针的地址。
如果是另一种情况的话,那就要找到pos前面的节点的指针。
pos位置后面删除节点
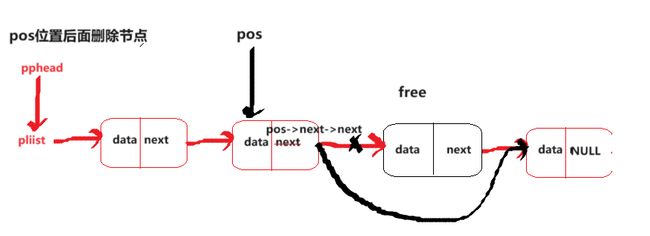
void SLAfterErase(SLN* phead, SLN* pos)
{
assert(pos->next != NULL);
SLN* tmp = pos->next;
pos->next = pos->next->next;
free(tmp);
tmp = NULL;
}
结合着图都很容易写出来。
最后总结一下单链表比较适合头插和头删,不太适合尾插尾删。