Chatbot开发三剑客:LLAMA、LangChain和Python

聊天机器人(Chatbot)开发是一项充满挑战的复杂任务,需要综合运用多种技术和工具。在这一领域中,LLAMA、LangChain和Python的联合形成了一个强大的组合,为Chatbot的设计和实现提供了卓越支持。
首先,LLAMA是一款强大的自然语言处理工具,具备先进的语义理解和对话管理功能。它有助于Chatbot更好地理解用户意图,并根据上下文进行智能响应。LLAMA的高度可定制性使得开发者可以根据实际需求灵活调整Chatbot的语言处理能力。
LangChain作为一个全栈语言技术平台,为Chatbot提供了丰富的开发资源。它整合了多种语言技术,包括语音识别、文本处理和机器翻译,为Chatbot的多模态交互提供全面支持。LangChain的强大功能使得开发者能够轻松构建复杂而灵活的Chatbot系统。
Python作为一种通用编程语言,是Chatbot开发的理想选择。其简洁而强大的语法使得开发过程更加高效,而丰富的第三方库和生态系统为Chatbot开发提供了广泛的工具和资源。Python的跨平台性也使得Chatbot能够在不同环境中运行,实现更广泛的应用。
Chatbot开发离不开大型语言模型(LLM),LLM是一种以其实现通用语言理解和生成能力而备受关注的语言模型。LLM通过使用大量数据在训练期间学习数十亿个参数,并在训练和运行过程中消耗大量计算资源来获得这些能力。

让我们使用Langchain、llama和Python构建一个简单的聊天机器人!
在这个简单的项目中,我想创建一个关于HIV/AIDS特定主题的聊天机器人。这意味着我们发送给聊天机器人的消息,聊天机器人将尝试根据主题和消息之间的关联进行回答。但在此之前,我们必须安装和下载一些必要的组件:
1、大型语言模型
我使用的是从Hugging Face下载的META AI的LLAMA 2。
2、Langchain
用于开发由语言模型驱动的应用程序的框架
pip install langchain3、安装Llama-cpp-python
llama.cpp库的Python实现(我尝试使用最新的llama.cpp版本,但它不起作用,所以我建议使用0.1.78稳定版本,并确保安装了C++编译器)。
pip install llama-cpp-python==0.1.784、导入库
from langchain.prompts importPromptTemplate
from langchain.llms importLlamaCpp
from langchain.callbacks.manager importCallbackManager
from langchain.callbacks.streaming_stdout import(
StreamingStdOutCallbackHandler
)PromptTemplate:负责创建PromptValue,这是一种根据用户输入组合动态值的对象。
llamacpp:Facebook的LLAMA模型的C/C++端口。
CallbackManager:处理来自LangChain的回调。
StreamingStdOutCallbackHandler:用于流式处理的回调处理程序。
代码
首先,我将为我的模型路径创建一个名为 “your_model_path”的变量,然后因为我只想限制主题为HIV/AIDS,所以我创建了一个名为 “chat_topic”的主题变量,并将其填充为 “HIV/AIDS”,显然你可以修改这个主题,如果你不想限制主题,可以删除 “chat_topic”并更改模板。之后,我将创建一个名为 “user_question”的变量,以接收用户输入,还有一个稍后将使用的模板。
your_model_path = "写入你的模型路径"
chat_topic = "hiv/aids"
user_question = str(input("输入你的问题:"))
template= """
请解释这个问题:“{question}”,主题是关于{topic}
"""我将创建一个 PromptTemplate变量,该变量将使用我们之前创建的模板,并将其分配给 “prompt”变量,然后更改提示的格式并将其分配给 “final_prompt”变量。我们使用 “chat_topic”中的主题和我们之前初始化的 “user_question”中的问题。然后创建一个名为 “Callbackmanager”的变量,并将流处理程序分配给它。
prompt = PromptTemplate.from_template(template)
final_prompt = prompt.format(
topic=chat_topic,
question=user_question
)
CallbackManager= CallbackManager([StreamingStdOutCallbackHandler()])之后,让我们创建模型。
llm = LlamaCpp(
model_path=your_model_path,
n_ctx=6000,
n_gpu_layers=512,
n_batch=30,
callback_manager=CallbackManager,
temperature=0.9,
max_tokens=4095,
n_parts=1,
verbose=0
)model_path:LLAMA模型的路径。
n_ctx:令牌上下文窗口,模型在生成响应时可以接受的令牌数量。
n_gpu_layers:要加载到gpu内存中的层数。
n_batch:并行处理的令牌数。
callback_manager:处理回调。
temperature:用于抽样的温度,较高的温度将导致更具创意和想象力的文本,而较低的温度将导致更准确和实际的文本。
max_tokens:生成的最大令牌数。
n_parts:要将模型分割成的部分数。
verbose:打印详细输出。
最后,调用模型并传递提示。
python "你的文件名.py"要运行它,只需在cmd中键入上述命令。
演示

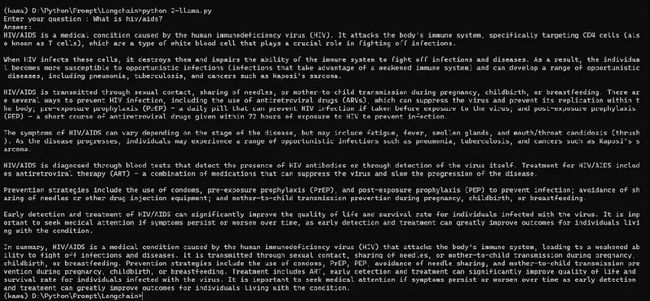
完整代码
from langchain.prompts importPromptTemplate
from langchain.llms importLlamaCpp
from langchain.callbacks.manager importCallbackManager
from langchain.callbacks.streaming_stdout import(
StreamingStdOutCallbackHandler
)
your_model_path = "write your model path"
chat_topic = "hiv/aids"
user_question = str(input("Enter your question : "))
template= """
Please explain this question : "{question}" the topic is about {topic}
"""
prompt = PromptTemplate.from_template(template)
final_prompt = prompt.format(
topic=chat_topic,
question=user_question
)
CallbackManager= CallbackManager([StreamingStdOutCallbackHandler()])
llm = LlamaCpp(
model_path=your_model_path,
n_ctx=6000,
n_gpu_layers=512,
n_batch=30,
callback_manager=CallbackManager,
temperature=0.9,
max_tokens=4095,
n_parts=1,
verbose=0
)
llm(final_prompt)