Scrapy爬虫异步框架之持久化存储(一篇文章齐全)
1、Scrapy框架初识(点击前往查阅)
2、Scrapy框架持久化存储(点击前往查阅)
3、Scrapy框架内置管道(点击前往查阅)
4、Scrapy框架中间件(点击前往查阅)

Scrapy 是一个开源的、基于Python的爬虫框架,它提供了强大而灵活的工具,用于快速、高效地提取信息。Scrapy包含了自动处理请求、处理Cookies、自动跟踪链接、下载中间件等功能
Scrapy框架的架构图(先学会再来看,就能看懂了!)

一、持久化存储(文本)
1:基于终端指令的存储
基于终端指令:简单,但是局限性较大。
scrapy crawl myspider -o project_name.后缀名
命令讲解: (例:scrapy crawl baidu -o baidudata.json)
- myspider:执行的爬虫文件名
- project_name.后缀名:想要保存的文件名和格式(具体格式参考下面)
终端指令的方法只可以将parse方法的返回值存储到指定后缀的文本文件中。且格式只能是如下展示的。

1.1:执行代码
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫文件的唯一标识(就是你创建的爬虫文件夹名字)
name = "baidu"
# 允许的域名,这个代表你只能访问这个网址的子域名,其他的都会禁止(这个我们会注释掉,不会打开)
# allowed_domains = ["www.xxx.com"]
# 起始的url列表,网址可以随便放,可以放多个,列表中的url都会被框架进行异步请求发送。
start_urls = ["https://www.xiachufang.com/category/40076/"]
# 数据解析:parse调用的次数取决于start_urls列表元素的个数
def parse(self, response): # response参数就表示响应对象
# 创建一个空列表用于存储
all_data = []
# 利用xpath解析:(scrapy内置xpath,无需另外导入)
li_list = response.xpath('//div[@class="pure-u-3-4 category-recipe-list"]//ul/li')
for li in li_list:
# 1、scrapy中的xpath会返回Selector对象,我们需要的数据在该对象data属性中(extract可以实现该功能,)
# 2、extract_first()就是取第一个,因为文本两边有空格,所以.strip() 可以去除两侧的空格
title = li.xpath('.//p[1]/a/text()').extract_first().strip()
author = li.xpath('.//p[4]/a/text()').extract_first().strip()
# 将每次获取到的标题和作者添加到字典中
dic = {
'title': title,
'author': author
}
# 将字典添加到列表中
all_data.append(dic)
# 爬取到的数据被作为parse方法的返回值
return all_data1.1:执行结果分析
此代码在这个Scrapy框架初识(点击前往查阅)代码上就加了前4步(如下图)。
- 第5步:执行代码
- 第6步:最后生成的文件Scrapy框架初识(点击前往查阅)

基于终端指令存储就是这样的,虽然简单,但是局限性很大。
2:基于管道的存储(存入本地文件)
基于管道的形式:相比较终端复杂,但是灵活性很大。
管道存储so easy 只需5步
2.1:在爬虫文件中进行数据解析操作。
解析代码如下⬇️
import scrapy
class BaiduSpider(scrapy.Spider):
# 爬虫文件的唯一标识(就是你创建的爬虫文件夹名字)
name = "baidu"
# 允许的域名,这个代表你只能访问这个网址的子域名,其他的都会禁止(这个我们会注释掉,不会打开)
# allowed_domains = ["www.xxx.com"]
# 起始的url列表,网址可以随便放,可以放多个,列表中的url都会被框架进行异步请求发送。
start_urls = ["https://www.xiachufang.com/category/40076/"]
# 数据解析:parse调用的次数取决于start_urls列表元素的个数
def parse(self, response): # response参数就表示响应对象
# 创建一个空列表用于存储
all_data = []
# 利用xpath解析:(scrapy内置xpath,无需另外导入)
li_list = response.xpath('//div[@class="pure-u-3-4 category-recipe-list"]//ul/li')
for li in li_list:
# 1、scrapy中的xpath会返回Selector对象,我们需要的数据在该对象data属性中(extract可以实现该功能,)
# 2、extract_first()就是取第一个,因为文本两边有空格,所以.strip() 可以去除两侧的空格
title = li.xpath('.//p[1]/a/text()').extract_first().strip()
author = li.xpath('.//p[4]/a/text()').extract_first().strip()
2.2:创建一个item类型的对象。
创建的item对象,需要封装自己需要的变量。例如:我需要title、author两个变量(框架中有封装好item类型文件)

2.2.1:将解析到的数据存储到该对象中。
如何将解析好的数据存储到item对象中呢?各位看官接着往下看~
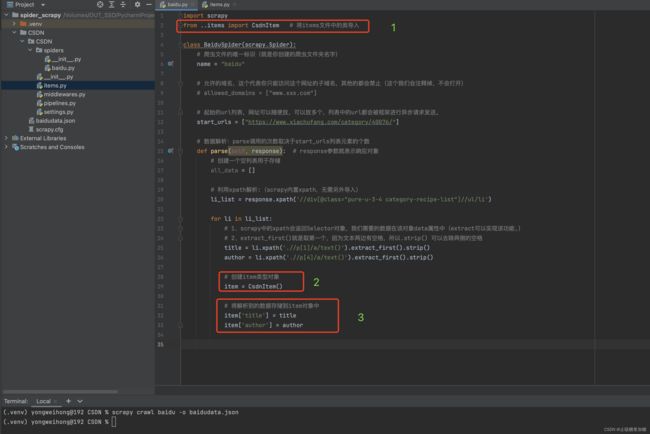
2.3:将item对象提交给管道。
什么是管道呢?管道在框架中在哪呢?就在这~

如何将item对象提交给管道呢?只需要 yield 关键字就可以了!

2.4:在管道中实现process_item的函数,实现对item对象的接收,对其进行指定的持久化存储。

代码讲解:(return是有多个管道把数据传递给下一个,后面会讲解)
- open_spider函数:这个函数只会在process_item函数之前之前执行一次,所以这就操作的空间了,我们可以先定义一个全局变量,然后在这个函数中创建一个文件句柄。
- process_item函数:self调用写入数据就行了。
- close_spider函数:该函数会在process_item函数完全执行结束之后调用一次,这个里边就关闭文件就行了。
错误演示:❌❌❌

可能会有同学会想到用这个方法来储存,这就要想到一个问题了,process_item函数会被执行很多次(执行的次数取决于爬虫文件提交的次数)所以这个方法肯定是不行的。
2.5:在配置文件中开启管道功能。
注释去掉就是开启了,后面的300是优先级的,如果有多个管道会用到,数字越小优先级越高,下面会讲~(另外UA或者Cookie一些反爬根据网站需求决定是否开启)

2.6:执行结果
执行指令:my_spider就是你的爬虫文件名字
scrapy crawl my_spider执行代码:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class CsdnPipeline:
fp = None # 全局变量。
# 该函数只会被在process_item函数调用前被调用一次。
def open_spider(self, item):
# 创建文件
self.fp = open('baidu.txt', 'w')
# 该函数只会被在process_item函数完全执行结束后被调用一次。
def close_spider(self, item):
# 关闭文件
self.fp.close()
# 该函数是用来接收爬虫文件提交过来的item对象(此函数执行次数取决于爬虫文件提交的次数)
def process_item(self, item, spider): # item参数就表示接收到的item对象。
# 将item中的数据取出来
title = item['title']
author = item['author']
# 数据写入
self.fp.write(title + ":" + author + '\n')
return item
以我们设置的文件格式,文件名字储存好了。 
二、基于管道的存储(存入数据库)
首先肯定要先安装MySQL数据库的,没有安装可以参考最新版MySQL安装 & 配置 & 启动
还需要安装模块用于操作MySQL数据库
pip install pymsql存到数据库步骤:(数据库要提前开启哦)
和存入本地文件唯一不同的地方就在第四步管道函数的编写,下面我们就把这方面重点分析一下~
1:settings中配置

前面还提到了 yield 的关键字,是提交给管道的,他优先提交给数字小的,也就是优先级高的。
2:管道原理剖析

还记得前面的 return吗?现在来填坑了!!!
如果 你需要一个管道就OK了下面不需要了,那OK不需要return也是可以的,但是,你下面还有管道,那必须要return的,不然你数据无法传递下去,并且还会报错。
3:代码编写
首先要学会Python操作MySQL方法,不会的可以参考这Python操作中MySQL数据方法
此代码指针对MySQL数据库的,完整的需要包含上面 class CsdnPipeline 中的代码
import pymysql # 导入操作数据库模块
class MysqlPipeline:
# 1、创建一个链接对象
conn = pymysql.connect(
host='127.0.0.1', # mysql服务器的ip地址
port=3306, # mysql默认端口号
user='root', # mysql用户名
password='root1234', # mysql密码
db='spider', # mysql指定的数据库
)
# 2、创建一个游标对象:用来执行sql语句
cursor = conn.cursor()
def process_item(self, item, spider):
# 利用上面传入的item,我们先获取到数据
title = item['title']
author = item['author']
# 将2个字段存储到mysql数据表中
sql = 'insert into bili(title,author) values ("{}","{}")'.format(title, author)
# 使用游标对象执行sql语句
self.cursor.execute(sql)
# 提交事物,最后才会将数据存入数据库中
self.conn.commit()
return item
def close_spider(self, spider):
# 关闭游标和链接对象
self.cursor.close()
self.conn.close()代码分析:

其中主要就是数据库的链接,要提前创建好表和对应的字段,然后会简单的SQL语句。
4:执行结果
三、基于管道的存储(存入Redis缓存中)
首先肯定要先安装Redis的,没有安装可以参考手把手安装部署Redis
还需要安装模块用于操作Redis,这个安装个低版本的,高的有些数据格式不支持,例如字典就不行的。
pip install redis==2.10.6存到Redis步骤:(Redis要提前开启哦)
和上面一样的唯一不同的地方就在第四步管道函数的编写,下面我们就把这方面重点分析一下~
1:settings中配置

2:代码编写
此代码指针对Redis缓存的,完整的需要包含上面 class CsdnPipeline 和 class MysqlPipeline 中的代码。
from redis import Redis # 导入模块
class RedisPipeline:
# 创建链接对象
conn = Redis(host='127.0.0.1', port=6379)
def process_item(self, item, spider):
# 将item这个字典存储到redis中
self.conn.lpush('bili', item) # lpush(参数1,参数2):参数1新建列表的名称,参数2是向列表中存储的数据
return item代码分析:

Redis的比较简单,主要就是连接,按照这个写就行了,没有啥理解的,固定语法。
3:执行结果

自此Scrapy框架持久化存储的2种方法就这些了,另外还有就是图片和视频的持久存储,在内置管道中讲解。