《十堂课学习 Flink SQL》第三章:Flink SQL 环境搭建
本章内容包括安装和配置 Flink 环境;Flink 官方示例代码解读;使用 Flink SQL CLI 进行基本查询 以及 Flink SQL 连接外部数据源。所有内容均会以公开源码,希望能够帮助到大家 ~ 有任何疑问欢迎留言 ~ 感谢阅读 ~
3.1 安装与配置 Flink 环境
3.1.1 java 环境
启动命令行输入如下代码,验证 java 环境没有问题。如图所示:
java -version
javac -version
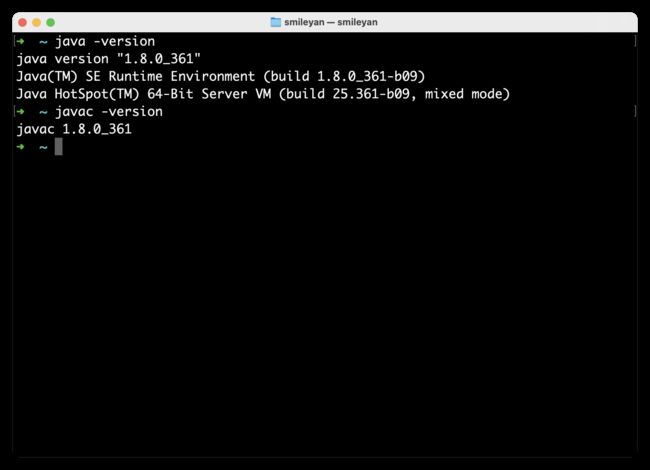
请确保 java 环境无误,以便于接下来的开发以及部署。此外特别补充一下,尽管本人写博客时用到的是 mac 系统,但 windows 系统的运行过程也是如此,无任何差异。
3.1.2 下载并解压 Flink
前往 Flink 官网下载压缩包,建议下载 1.12 及其以上的版本,并且应该下载稳定版本。避免出现 “熟悉的版本” 与以后工作用到的版本差别太大。如下图所示,记得下载的时 二进制 类型的。
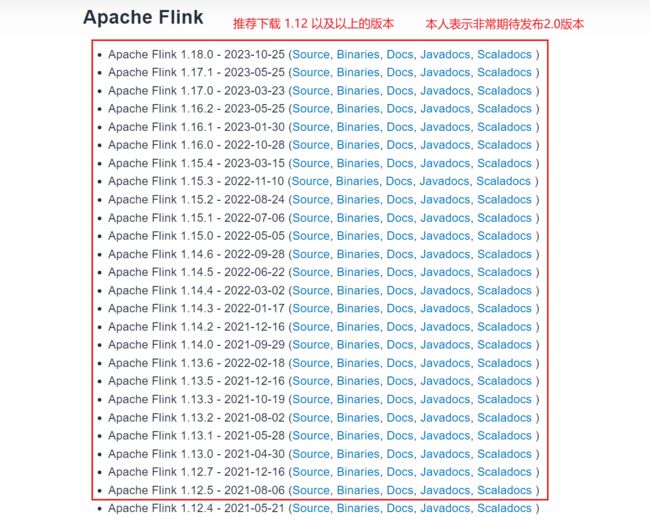
这里我本人下载了 1.12.7 版本,下载链接为 https://archive.apache.org/dist/flink/flink-1.12.7/flink-1.12.7-bin-scala_2.11.tgz。
事实上其他版本差异不大,尤其对于本系列课程。
下载得到 flink-1.12.7-bin-scala_2.11.tgz 压缩包,解压到本地环境,为了确保方便找到,请解压到自己分类好的路径。本人习惯将此类文件解压在 opt 文件夹中。
3.1.3 单节点启动 Flink
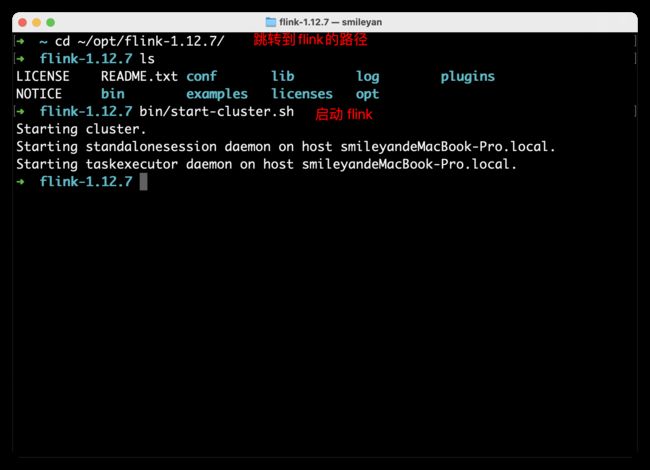
首先总览一下解压后目录结构:

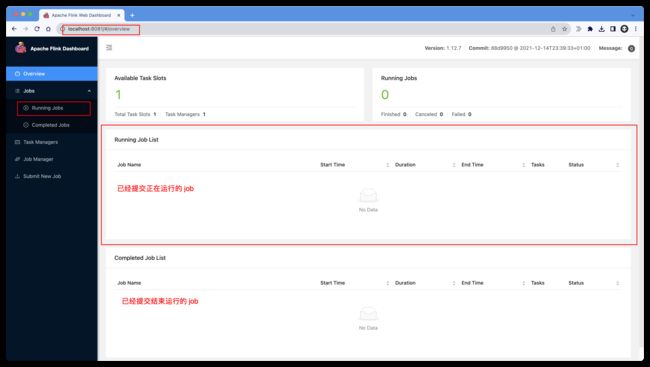
接着我们本地执行 Flink,然后访问 localhost:8081。启动命令如下截图:
$ bin/start-cluster.sh
启动后,访问 8081 端口,如图所示:
结束执行命令:
$ bin/stop-cluster.sh
3.1.4 执行官方提供的例子
如图所示,官方提供了不少 jar 例子,我们选取其中的几个执行。
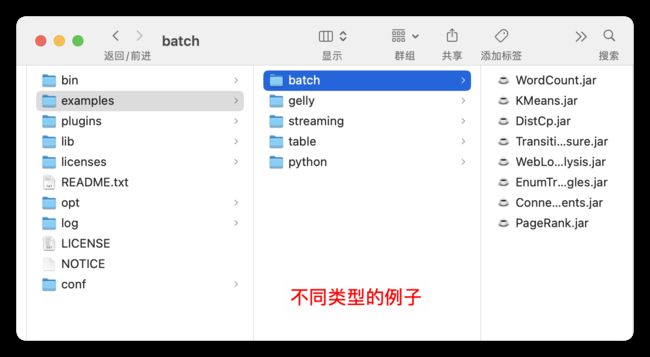
执行如下命令,提交任务并执行任务。
$ bin/flink run examples/streaming/WordCount.jar
如图所示:
接着访问 8081 端口。


直接输入以下命令,查看执行结果的输出。
$ tail log/flink-*-taskexecutor-*.out

3.2 Flink 官方示例代码解读
官方提供的源码可在 https://github.com/apache/flink/tree/master/flink-examples 下载。
这里我们结合上面的 WordCount 的例子,分析官方的源码,源码如下所示,主要目的是统计某一段话中含有多少个单词,以及每个单词出现的次数。
public class WordCountData {
public static final String[] WORDS =
new String[] {
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,",
"And by opposing end them?--To die,--to sleep,--",
"No more; and by a sleep to say we end",
"The heartache, and the thousand natural shocks",
"That flesh is heir to,--'tis a consummation",
"Devoutly to be wish'd. To die,--to sleep;--",
"To sleep! perchance to dream:--ay, there's the rub;",
"For in that sleep of death what dreams may come,",
"When we have shuffled off this mortal coil,",
"Must give us pause: there's the respect",
"That makes calamity of so long life;",
"For who would bear the whips and scorns of time,",
"The oppressor's wrong, the proud man's contumely,",
"The pangs of despis'd love, the law's delay,",
"The insolence of office, and the spurns",
"That patient merit of the unworthy takes,",
"When he himself might his quietus make",
"With a bare bodkin? who would these fardels bear,",
"To grunt and sweat under a weary life,",
"But that the dread of something after death,--",
"The undiscover'd country, from whose bourn",
"No traveller returns,--puzzles the will,",
"And makes us rather bear those ills we have",
"Than fly to others that we know not of?",
"Thus conscience does make cowards of us all;",
"And thus the native hue of resolution",
"Is sicklied o'er with the pale cast of thought;",
"And enterprises of great pith and moment,",
"With this regard, their currents turn awry,",
"And lose the name of action.--Soft you now!",
"The fair Ophelia!--Nymph, in thy orisons",
"Be all my sins remember'd."
};
}
计算方法如下:
public class WordCount {
// *************************************************************************
// PROGRAM
// *************************************************************************
public static void main(String[] args) throws Exception {
// Checking input parameters
final MultipleParameterTool params = MultipleParameterTool.fromArgs(args);
// set up the execution environment
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// make parameters available in the web interface
env.getConfig().setGlobalJobParameters(params);
// get input data
DataStream<String> text = null;
if (params.has("input")) {
// union all the inputs from text files
for (String input : params.getMultiParameterRequired("input")) {
if (text == null) {
text = env.readTextFile(input);
} else {
text = text.union(env.readTextFile(input));
}
}
Preconditions.checkNotNull(text, "Input DataStream should not be null.");
} else {
System.out.println("Executing WordCount example with default input data set.");
System.out.println("Use --input to specify file input.");
// get default test text data
text = env.fromElements(WordCountData.WORDS);
}
DataStream<Tuple2<String, Integer>> counts =
// split up the lines in pairs (2-tuples) containing: (word,1)
text.flatMap(new Tokenizer())
// group by the tuple field "0" and sum up tuple field "1"
.keyBy(value -> value.f0)
.sum(1);
// emit result
if (params.has("output")) {
counts.writeAsText(params.get("output"));
} else {
System.out.println("Printing result to stdout. Use --output to specify output path.");
counts.print();
}
// execute program
env.execute("Streaming WordCount");
}
// *************************************************************************
// USER FUNCTIONS
// *************************************************************************
/**
* Implements the string tokenizer that splits sentences into words as a user-defined
* FlatMapFunction. The function takes a line (String) and splits it into multiple pairs in the
* form of "(word,1)" ({@code Tuple2}).
*/
public static final class Tokenizer
implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) {
// normalize and split the line
String[] tokens = value.toLowerCase().split("\\W+");
// emit the pairs
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<>(token, 1));
}
}
}
}
}
https://nightlies.apache.org/flink/flink-docs-stable/docs/try-flink/local_installation/
3.3 使用 Flink SQL CLI
这里我们同样还是以 WordCount 为例子,但是本次使用 Flink SQL CLI 。首先新建一个 txt 文本文件,如下所示:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
Apache Flink features two relational APIs - the Table API and SQL - for unified stream and batch processing. The Table API is a language-integrated query API for Java, Scala, and Python that allows the composition of queries from relational operators such as selection, filter, and join in a very intuitive way. Flink’s SQL support is based on Apache Calcite which implements the SQL standard. Queries specified in either interface have the same semantics and specify the same result regardless of whether the input is continuous (streaming) or bounded (batch).
The Table API and SQL interfaces integrate seamlessly with each other and Flink’s DataStream API. You can easily switch between all APIs and libraries which build upon them. For instance, you can detect patterns from a table using MATCH_RECOGNIZE clause and later use the DataStream API to build alerting based on the matched patterns.
假设这个 txt 文本文件的路径为 /usr/local/word-count.txt,接着我们执行如下命令:
成功启动后可以看到一只可爱的松鼠,最下面的一行是 SQL 命令行。
接着我们通过 Flink SQL 的语句执行官方提供的一个简单的例子。
首先输入 SELECT 'Hello World' 查看效果。 输出结果如图所示。
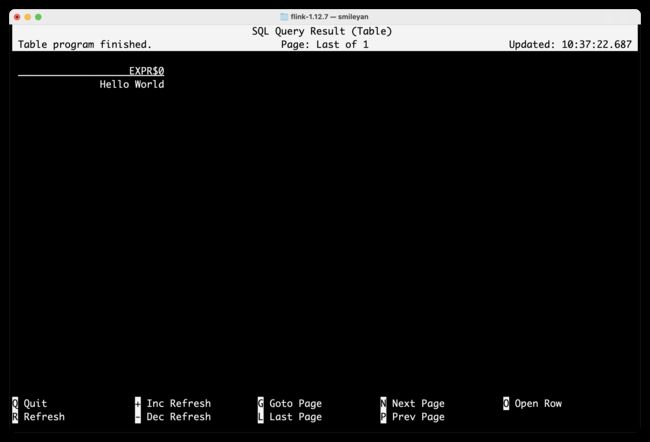
此查询不需要表源,只生成一行结果。CLI将从集群中检索结果并将其可视化。按Q键可以关闭结果视图。
CLI支持三种模式来维护和可视化结果。表模式在内存中具体化结果,并以常规的分页表表示形式将其可视化。可以通过在CLI中执行以下命令来启用它:
SET execution.result-mode=table;
# 逐行复制命令执行
SET execution.result-mode=changelog;
# 逐行复制命令执行
SET execution.result-mode=tableau;
准备工作已经完成,请注意,当您将此模式用于流式查询时,结果将连续打印在控制台上。如果此查询的输入数据有界,则在Flink处理完所有输入数据后,作业将终止,打印也将自动停止。否则,如果您想终止正在运行的查询,在这种情况下只需键入 CTRL + C,作业和打印将停止。
接着输入以下命令
SELECT name, COUNT(*) AS cnt FROM (VALUES ('Bob'), ('Alice'), ('Greg'), ('Bob')) AS NameTable(name) GROUP BY name;
效果如图所示:
最后我们还可以访问 8081 端口,查看任务提交情况。

3.4 Flink SQL 连接外部数据源
Flink 提供了各种连接器,用于从不同的数据源读取和写入数据。以下是一些常见的外部连接器以及如何使用它们,这里只是介绍大体用法,不做详细例子介绍说明。
-
Kafka 连接器:
CREATE TABLE MyKafkaTable ( -- 定义字段 ) WITH ( 'connector' = 'kafka', 'topic' = 'your_kafka_topic', 'properties.bootstrap.servers' = 'your_bootstrap_servers', 'format' = 'json' );使用时,替换
'your_kafka_topic'和'your_bootstrap_servers'为你实际的 Kafka 主题和引导服务器地址。 -
FileSystem 连接器:
CREATE TABLE MyFileSystemTable ( -- 定义字段 ) WITH ( 'connector' = 'filesystem', 'path' = 'file:///path/to/your/data', 'format' = 'csv' );使用时,替换
'file:///path/to/your/data'为你实际的文件系统路径。 -
JDBC 连接器:
CREATE TABLE MyJDBCTable ( -- 定义字段 ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://your_mysql_host:your_mysql_port/your_database', 'table-name' = 'your_table', 'username' = 'your_username', 'password' = 'your_password' );使用时,替换连接信息为你实际的数据库连接信息。
-
Elasticsearch 连接器:
CREATE TABLE MyElasticsearchTable ( -- 定义字段 ) WITH ( 'connector' = 'elasticsearch', 'hosts' = 'http://your_elasticsearch_host:your_elasticsearch_port', 'index' = 'your_index', 'document-type' = 'your_document_type' );使用时,替换 Elasticsearch 连接信息为你实际的 Elasticsearch 主机和端口。
为了避免篇幅过长,具体使用方法我们在后面的例子中逐个介绍说明。
3.5 Flink SQL 优点概述
Flink SQL 是 Apache Flink 提供的一种声明性查询语言,用于在 Flink 流处理和批处理引擎上执行 SQL 查询。以下是 Flink SQL 的一些优点:
-
声明性语法: Flink SQL 提供了类似 SQL 的声明性语法,使得开发者可以通过简洁的语句描述数据处理逻辑,而不需要深入了解底层的编程模型。
-
易学易用: 对于熟悉 SQL 的用户,使用 Flink SQL 更容易上手,减少了对编程语言和API的学习成本。这降低了入门门槛,使更多人能够利用 Flink 进行大数据处理。
-
统一的编程模型: Flink SQL 提供了统一的编程模型,将批处理和流处理结合在一起。这意味着你可以使用相同的 SQL 语法处理静态和动态的数据,从而简化了对不同类型处理的切换。
-
优化器: Flink SQL 配备了强大的查询优化器,能够自动优化查询计划,提高查询性能。这种优化器能够选择最佳的执行计划以满足查询的需求。
-
易于集成: Flink SQL 支持各种外部连接器,包括 Kafka、HDFS、JDBC、Elasticsearch 等,使得连接和处理多种数据源变得更加容易。
-
动态表: Flink SQL 引入了动态表的概念,允许开发者在运行时动态修改和操作表结构,使得处理动态数据变得更加方便。
-
开放的 API: Flink SQL 可以与 Flink 的 DataStream 和 DataSet API 无缝集成,使得在 SQL 查询中使用自定义的用户定义函数(UDF)和用户定义聚合函数(UDAF)成为可能。
-
适用于实时和批处理: Flink SQL 不仅支持实时流处理,还能够处理批处理。这种灵活性使得 Flink SQL 成为处理多种场景下数据的理想选择。
总体而言,Flink SQL 提供了一种方便、高效且灵活的数据处理方式,对于那些希望使用 SQL 查询语言进行大数据处理的开发者来说,是一种强大的工具。
3.6 本章小结
本章内容主要介绍 Flink 以及 Flink SQL 环境搭建过程,并不涉及编程开发相关。环境搭建总体而言也比较简单,从官网下载后解压即用的模式非常方便。接着借用官方例子初步体会了一下 Flink SQL ,连 “小试牛刀” 都算不上。
从本章开始将会更多地介绍编程开发相关内容,同样也是以例子为主,加上我个人的理解进行介绍,希望能够再巩固自己学习成果的同时,帮助到大家,感谢支持 ~
如果认为本章节写得还行,一定记得点击下方免费的赞 ~ 感谢 !
