一文读懂MySQL基础与进阶
Mysql基础与进阶
Part1 基础操作
数据库操作
在MySQL中,您可以使用一些基本的命令来创建和删除数据库。以下是这些操作的示例:
-
创建数据库:
要创建一个新的数据库,您可以使用
CREATE DATABASE命令。以下是示例:CREATE DATABASE mydatabase;这将创建一个名为"mydatabase"的新数据库。您可以将数据库名称替换为您想要创建的数据库名称。
-
删除数据库:
要删除一个数据库,您可以使用
DROP DATABASE命令。请小心使用此命令,因为它会永久删除数据库和其中的所有数据。以下是示例:DROP DATABASE mydatabase;这将删除名为"mydatabase"的数据库。确保在删除之前备份重要数据。
-
查看数据库列表:
要查看已创建的数据库列表,您可以使用
SHOW DATABASES命令。以下是示例:SHOW DATABASES;这将列出所有可用的数据库,包括系统数据库和您自己创建的数据库。
表操作
在MySQL中,您可以使用一些基本的命令来创建、删除和修改表。以下是这些操作的示例:
-
创建表:
要创建一个新表,您可以使用
CREATE TABLE命令。以下是一个示例:CREATE TABLE employees ( employee_id INT AUTO_INCREMENT PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50), hire_date DATE );这将创建一个名为"employees"的表,其中包含员工的基本信息。上面的示例定义了表的结构,包括列名、数据类型和约束。
-
删除表:
要删除一个表,您可以使用
DROP TABLE命令。请小心使用此命令,因为它会永久删除表和其中的所有数据。以下是示例:DROP TABLE employees;这将删除名为"employees"的表。确保在删除之前备份重要数据。
-
修改表:
您可以使用
ALTER TABLE命令来修改表结构,例如添加、删除或更改列。以下是一些示例:-
添加列:
ALTER TABLE employees ADD email VARCHAR(100);这将向"employees"表中添加一个名为"email"的新列。
-
删除列:
ALTER TABLE employees DROP COLUMN email;这将从"employees"表中删除名为"email"的列。
-
修改列的数据类型:
ALTER TABLE employees MODIFY COLUMN hire_date DATETIME;这将修改"employees"表中的"hire_date"列的数据类型为DATETIME。
-
增删改查操作
DML(Data Manipulation Language)语句是用于执行数据库中数据的增、删、改、查操作的SQL语句。以下是一些常见的DML语句示例:
-
插入数据(INSERT):
使用
INSERT INTO语句将新数据插入到表中。示例:
INSERT INTO employees (first_name, last_name, hire_date) VALUES ('John', 'Doe', '2023-01-15');这将在"employees"表中插入一行新的员工数据。
-
更新数据(UPDATE):
使用
UPDATE语句来修改现有数据。示例:
UPDATE employees SET last_name = 'Smith' WHERE employee_id = 1;这将将ID为1的员工的姓氏更新为"Smith"。
-
删除数据(DELETE):
使用
DELETE FROM语句来删除数据。示例:
DELETE FROM employees WHERE employee_id = 2;这将删除ID为2的员工的记录。
-
查询数据(SELECT):
使用
SELECT语句从数据库中检索数据。示例:
SELECT first_name, last_name FROM employees WHERE hire_date >= '2022-01-01';这将检索在指定日期之后入职的员工的名字和姓氏。
select中常见概念
在MySQL中,SELECT语句用于从数据库中检索数据。以下是SELECT语句中的一些常用子句和操作:
-
DISTINCT:DISTINCT关键字用于消除查询结果集中的重复行,只返回唯一的行。
示例:
SELECT DISTINCT column1, column2 FROM table_name; -
GROUP BY:GROUP BY子句用于对结果集进行分组,并通常与聚合函数一起使用。它将具有相同值的行组合成一个结果行。
示例:
SELECT department, COUNT(*) AS employee_count FROM employees GROUP BY department; -
HAVING:HAVING子句用于筛选由GROUP BY子句生成的分组。它允许您对分组后的结果进行筛选,通常基于聚合函数的计算结果。
示例:
SELECT department, AVG(salary) AS avg_salary FROM employees GROUP BY department HAVING avg_salary > 50000; -
UNION:UNION操作用于合并多个查询的结果集,并返回一个包含所有结果的结果集,消除重复行。
示例:
SELECT column1 FROM table1 UNION SELECT column1 FROM table2; -
UNION ALL:UNION ALL操作与UNION类似,但不会消除重复行,返回包含所有结果的结果集,包括重复行。
示例:
SELECT column1 FROM table1 UNION ALL SELECT column1 FROM table2; -
子查询:子查询是将一个查询嵌套在另一个查询中的查询。它通常用于在查询中使用另一个查询的结果。
示例:
SELECT product_name FROM products WHERE product_id IN (SELECT product_id FROM order_details WHERE order_id = 1001);
这些子句和操作允许您执行各种复杂的查询,从数据中检索所需的信息。您可以根据具体的查询需求组合和使用这些子句,以获得所需的结果。
DCL 权限相关
DCL(Data Control Language)语句是用于控制数据库对象(如表、视图、存储过程等)的访问权限和权限管理的SQL语句。DCL语句用于确保数据库的安全性和完整性,以及管理用户对数据库对象的权限。以下是一些常见的DCL语句和详细解释:
-
GRANT语句:GRANT语句用于授予用户或角色对数据库对象的特定权限。这可以包括SELECT、INSERT、UPDATE、DELETE等权限。您可以指定权限的级别(例如,全局、表级、列级等)以及被授予权限的对象。示例:
GRANT SELECT, INSERT ON employees TO user1;上面的示例授予"user1"用户对"employees"表的SELECT和INSERT权限。
-
REVOKE语句:REVOKE语句用于撤销用户或角色对数据库对象的权限。您可以指定要撤销的权限和对象。示例:
REVOKE INSERT ON employees FROM user1;上面的示例从"user1"用户中撤销对"employees"表的INSERT权限。
-
DENY语句:DENY语句通常用于某些数据库管理系统中(如Microsoft SQL Server),用于显式拒绝用户或角色对数据库对象的权限。与REVOKE不同,DENY是一个更强制的拒绝,它覆盖了GRANT授权。示例(适用于SQL Server):
DENY SELECT ON employees TO user1;这将显式拒绝"user1"用户对"employees"表的SELECT权限。
-
WITH GRANT OPTION:在
GRANT语句中,可以使用WITH GRANT OPTION选项来授权用户或角色将所授予的权限再授予其他用户或角色。这允许用户充当权限传播者。示例:
GRANT SELECT ON employees TO user1 WITH GRANT OPTION;这允许"user1"用户将SELECT权限授予其他用户。
-
COMMIT和ROLLBACK:虽然
COMMIT和ROLLBACK通常与DML语句相关,但它们也可以用于DCL语句。COMMIT用于永久保存先前的事务更改,而ROLLBACK用于撤消事务更改。示例:
COMMIT;这将提交之前的DCL事务更改,使其永久生效。
DCL语句是用于管理数据库对象访问权限的关键工具,以确保数据的安全性和完整性。权限管理是数据库管理中的关键任务,因为它确保只有经过授权的用户能够访问和修改数据,从而保护数据的保密性和完整性。
Part2 数据类型
整数类型
MySQL支持多种数值数据类型,每种数据类型用于存储不同范围和精度的数值数据。以下是MySQL中常见的数值数据类型的介绍:
-
TINYINT:用于存储1字节(8位)的整数。范围从-128到127(有符号)或0到255(无符号)。
-
SMALLINT:用于存储2字节(16位)的整数。范围从-32,768到32,767(有符号)或0到65,535(无符号)。
-
MEDIUMINT:用于存储3字节(24位)的整数。范围从-8,388,608到8,388,607(有符号)或0到16,777,215(无符号)。
-
INT(或INTEGER):用于存储4字节(32位)的整数。范围从-2,147,483,648到2,147,483,647(有符号)或0到4,294,967,295(无符号)。
-
BIGINT:用于存储8字节(64位)的整数。范围从-9,223,372,036,854,775,808到9,223,372,036,854,775,807(有符号)或0到18,446,744,073,709,551,615(无符号)。
-
FLOAT:用于存储单精度浮点数,具有约6位小数的精度。
-
DOUBLE(或 DOUBLE PRECISION):用于存储双精度浮点数,具有约15位小数的精度。
-
DECIMAL(或 DEC):用于精确的小数值,可以指定总位数和小数位数。例如,
DECIMAL(10, 2)可以存储总共10位,其中2位为小数。 -
NUMERIC:类似于DECIMAL,用于精确的小数值。
日期和时间类型
MySQL提供了多种日期和时间类型,以便存储日期、时间和日期时间数据。以下是MySQL中常见的日期和时间类型:
-
DATE:用于存储日期,包括年、月、日,格式为’YYYY-MM-DD’。例如,'2023-11-01’表示2023年11月1日。
-
TIME:用于存储时间,包括小时、分钟、秒,格式为’HH:MM:SS’。例如,'14:30:00’表示下午2点30分。
-
DATETIME:用于存储日期和时间,包括年、月、日、小时、分钟和秒,格式为’YYYY-MM-DD HH:MM:SS’。例如,'2023-11-01 14:30:00’表示2023年11月1日下午2点30分。
-
TIMESTAMP:与DATETIME相似,用于存储日期和时间,但在插入或更新记录时,会自动更新为当前时间戳。这对于记录创建和修改时间非常有用。
-
YEAR:用于存储年份,通常以2位或4位形式表示。例如,'23’表示2023年,'2023’也表示2023年。
-
YEAR(4):与YEAR相似,但强制存储4位的年份。
-
TIMESTAMP(N):与TIMESTAMP相似,允许您指定小数秒的精度。例如,TIMESTAMP(6)允许存储毫秒级的时间戳。
-
TIME(N):与TIME相似,允许指定小数秒的精度。例如,TIME(3)允许存储毫秒级的时间。
-
DATETIME(N):与DATETIME相似,允许指定小数秒的精度。
这些日期和时间类型允许您根据需要存储不同精度和格式的日期和时间数据。根据具体的应用场景,选择合适的日期和时间类型非常重要。如果需要更高精度或需要记录时间戳,TIMESTAMP和具有小数秒精度的类型可能更适合。如果仅需要日期或时间,可以使用相应的DATE或TIME类型。
字符串类型
MySQL支持多种字符串类型,用于存储文本和字符数据。以下是MySQL中常见的字符串类型:
-
CHAR(n):用于存储固定长度的字符数据,其中n表示字符数。例如,CHAR(10)可以存储最多10个字符。
-
VARCHAR(n):用于存储可变长度的字符数据,其中n表示最大字符数。VARCHAR只占用实际存储的字符数加上一些额外的开销。例如,VARCHAR(255)可以存储最多255个字符。
-
TINYTEXT:用于存储非常短的文本数据,最大长度为255个字符。
-
TEXT:用于存储较长的文本数据,最大长度为65,535个字符。
-
MEDIUMTEXT:用于存储中等长度的文本数据,最大长度为16,777,215个字符。
-
LONGTEXT:用于存储非常长的文本数据,最大长度为4,294,967,295个字符。
-
ENUM(‘value1’, ‘value2’, …):用于存储一个字符串值集合中的一个,每个ENUM列定义了一个允许的值列表。例如,ENUM(‘Male’, ‘Female’)。
-
SET(‘value1’, ‘value2’, …):类似于ENUM,但允许存储多个值,每个SET列定义了一个允许的值列表。例如,SET(‘Red’, ‘Green’, ‘Blue’)。
-
BINARY(n):与CHAR(n)类似,但存储二进制数据而不是文本数据。
-
VARBINARY(n):与VARCHAR(n)类似,但存储可变长度的二进制数据。
-
TINYBLOB:用于存储非常短的二进制数据,最大长度为255字节。
-
BLOB:用于存储较长的二进制数据,最大长度为65,535字节。
-
MEDIUMBLOB:用于存储中等长度的二进制数据,最大长度为16,777,215字节。
-
LONGBLOB:用于存储非常长的二进制数据,最大长度为4,294,967,295字节。
这些字符串类型允许您根据需要存储不同长度和类型的文本和二进制数据。选择适当的字符串类型取决于您的数据的性质和大小。例如,对于短文本数据,可以使用CHAR、VARCHAR或TINYTEXT,而对于较长文本数据,可以使用TEXT、MEDIUMTEXT或LONGTEXT。对于二进制数据,可以使用BINARY、VARBINARY或BLOB类型。
Part3 运算符


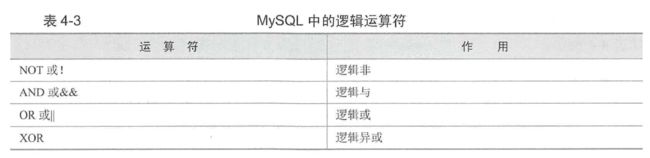
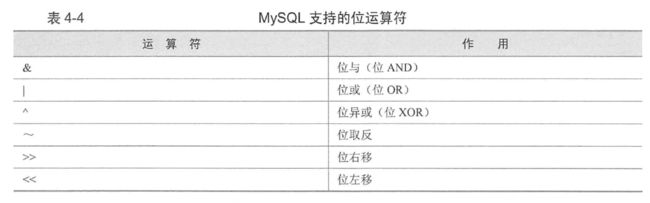
Part4 函数
字符串函数
MySQL提供了许多内置的字符串函数,这些函数允许您在查询中操作和处理字符串数据。以下是一些常见的MySQL字符串函数:
-
CONCAT(str1, str2, …):将多个字符串连接在一起。
示例:
SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM employees; -
LENGTH(str)(或CHAR_LENGTH(str)):返回字符串的字符数(字符长度)。
示例:
SELECT LENGTH(description) AS description_length FROM products; -
UPPER(str):将字符串中的字符转换为大写。
示例:
SELECT UPPER(title) AS uppercase_title FROM articles; -
LOWER(str):将字符串中的字符转换为小写。
示例:
SELECT LOWER(email) AS lowercase_email FROM users; -
SUBSTRING(str, start, length):从字符串中提取子字符串,从指定位置开始,指定长度的字符。
示例:
SELECT SUBSTRING(description, 1, 20) AS short_description FROM products; -
LEFT(str, length):从字符串的左侧截取指定长度的字符。
示例:
SELECT LEFT(title, 10) AS short_title FROM articles; -
RIGHT(str, length):从字符串的右侧截取指定长度的字符。
示例:
SELECT RIGHT(zip_code, 5) AS last_five_digits FROM addresses; -
TRIM([characters FROM] str):删除字符串中指定的字符(或空格)。
示例:
SELECT TRIM(' ' FROM product_name) AS trimmed_name FROM products; -
REPLACE(str, from_str, to_str):将字符串中的指定子字符串替换为另一个字符串。
示例:
SELECT REPLACE(notes, 'TODO', 'DONE') AS updated_notes FROM tasks; -
CONCAT_WS(separator, str1, str2, …):将多个字符串用指定的分隔符连接在一起。
示例:
SELECT CONCAT_WS(', ', first_name, last_name) AS full_name FROM employees; -
FORMAT(number, decimal_places):将数字格式化为带有指定小数位数的字符串。
示例:
SELECT FORMAT(price, 2) AS formatted_price FROM products; -
LOCATE(substr, str, [start]):在字符串中查找子字符串,并返回其位置。
示例:
SELECT LOCATE('apple', description) AS apple_position FROM products;
数值函数
MySQL提供了许多内置的数值函数,这些函数允许您在查询中对数值数据执行各种操作和计算。以下是一些常用的MySQL数值函数:
-
ABS(x):返回一个数的绝对值。
示例:
SELECT ABS(-10) AS absolute_value; -
ROUND(x, d):将数四舍五入为指定的小数位数(d)。
示例:
SELECT ROUND(3.14159, 2) AS rounded_value; -
CEIL(x):返回不小于给定数的最小整数。
示例:
SELECT CEIL(4.2) AS ceiling_value; -
FLOOR(x):返回不大于给定数的最大整数。
示例:
SELECT FLOOR(4.8) AS floor_value; -
MOD(x, y):返回x除以y的余数。
示例:
SELECT MOD(10, 3) AS remainder; -
SQRT(x):返回一个数的平方根。
示例:
SELECT SQRT(25) AS square_root; -
POW(x, y):返回x的y次幂。
示例:
SELECT POW(2, 3) AS power; -
LOG(x):返回一个数的自然对数(以e为底)。
示例:
SELECT LOG(2) AS natural_log; -
LOG10(x):返回一个数的以10为底的对数。
示例:
SELECT LOG10(100) AS base_10_log; -
EXP(x):返回e的x次幂。
示例:
SELECT EXP(1) AS e_to_the_power; -
SIGN(x):返回一个数的符号,-1表示负数,0表示零,1表示正数。
示例:
SELECT SIGN(-7) AS sign_value; -
RAND():返回一个介于0和1之间的随机数。
示例:
SELECT RAND() AS random_number;
日期和时间函数
MySQL提供了许多内置的日期和时间函数,这些函数允许您在查询中操作和处理日期和时间数据。以下是一些常见的MySQL日期和时间函数:
-
NOW():返回当前日期和时间。
示例:
SELECT NOW() AS current_datetime; -
CURDATE():返回当前日期。
示例:
SELECT CURDATE() AS current_date; -
CURTIME():返回当前时间。
示例:
SELECT CURTIME() AS current_time; -
DATE_FORMAT(date, format):将日期格式化为指定的格式。
示例:
SELECT DATE_FORMAT(sale_date, '%Y-%m-%d') AS formatted_date FROM sales; -
DATE_ADD(date, INTERVAL value unit):在日期上执行加法操作,添加指定的值和单位。
示例:
SELECT DATE_ADD(order_date, INTERVAL 7 DAY) AS new_date FROM orders; -
DATE_SUB(date, INTERVAL value unit):在日期上执行减法操作,减去指定的值和单位。
示例:
SELECT DATE_SUB(payment_date, INTERVAL 1 MONTH) AS previous_month FROM payments; -
TIMESTAMPDIFF(unit, start_datetime, end_datetime):返回两个日期时间之间的时间差。
示例:
SELECT TIMESTAMPDIFF(DAY, start_date, end_date) AS days_between FROM events; -
TIMESTAMPADD(unit, count, datetime):在日期时间上执行加法操作,添加指定的计数和单位。
示例:
SELECT TIMESTAMPADD(HOUR, 2, event_time) AS two_hours_later FROM events; -
DATEDIFF(end_date, start_date):返回两个日期之间的天数差。
示例:
SELECT DATEDIFF(end_date, start_date) AS days_between FROM events; -
DAYNAME(date):返回日期的星期几。
示例:
SELECT DAYNAME(order_date) AS day_of_week FROM orders; -
MONTHNAME(date):返回日期的月份名称。
示例:
SELECT MONTHNAME(sale_date) AS month FROM sales; -
YEAR(date):返回日期的年份。
示例:
SELECT YEAR(event_date) AS event_year FROM events;
控制流程
MySQL提供了多种控制流程函数和语句,以支持条件判断和流程控制。以下是一些常见的MySQL控制流程函数和语句:
-
IF(expr, true_value, false_value):根据条件表达式的值返回两个可能的值。
示例:
SELECT IF(salary > 50000, 'High', 'Low') AS salary_category FROM employees; -
CASE:用于在查询中执行条件逻辑,类似于编程语言中的
switch语句。示例:
SELECT CASE WHEN age < 18 THEN 'Minor' WHEN age >= 18 AND age < 65 THEN 'Adult' ELSE 'Senior' END AS age_category FROM people; -
COALESCE(val1, val2, …):返回参数列表中的第一个非NULL值。
示例:
SELECT COALESCE(preferred_name, first_name, 'Guest') AS display_name FROM users; -
NULLIF(expr1, expr2):如果两个表达式相等,则返回NULL;否则返回第一个表达式的值。
示例:
SELECT NULLIF(score, 0) AS non_zero_score FROM scores; -
IFNULL(expr1, expr2):如果第一个表达式不为NULL,则返回第一个表达式的值;否则返回第二个表达式的值。
示例:
SELECT IFNULL(middle_name, 'N/A') AS middle_name FROM employees; -
CASE WHEN…THEN…ELSE…END:结合
CASE和WHEN来执行条件逻辑,允许多个条件和分支。示例:
SELECT CASE WHEN gender = 'Male' THEN 'M' WHEN gender = 'Female' THEN 'F' ELSE 'Unknown' END AS gender_code FROM persons;
聚合函数
MySQL提供了多种聚合函数,这些函数用于对数据进行汇总、计数、求和、平均值等操作。以下是一些常见的MySQL聚合函数:
-
COUNT():计算指定列或行的行数。可以用来计数表中的记录或特定条件的记录数。
示例:
SELECT COUNT(*) AS total_employees FROM employees; -
SUM():计算指定列的总和。通常用于计算数值列的总和。
示例:
SELECT SUM(sales_amount) AS total_sales FROM sales; -
AVG():计算指定列的平均值。通常用于计算数值列的平均值。
示例:
SELECT AVG(salary) AS average_salary FROM employees; -
MIN():查找指定列中的最小值。通常用于查找最小的数值或日期。
示例:
SELECT MIN(product_price) AS lowest_price FROM products; -
MAX():查找指定列中的最大值。通常用于查找最大的数值或日期。
示例:
SELECT MAX(order_date) AS latest_order_date FROM orders; -
GROUP_CONCAT():将指定列的值连接为一个字符串,通常用于将多个值组合为一个字符串。
示例:
SELECT GROUP_CONCAT(product_name) AS product_list FROM order_details WHERE order_id = 1001; -
STD()(标准差):计算指定列的标准差,用于衡量数据的分散程度。
示例:
SELECT STD(score) AS score_std_deviation FROM exam_results; -
VAR_POP()(总体方差):计算总体方差,用于衡量数据的变异程度。
示例:
SELECT VAR_POP(height) AS population_height_variance FROM population_data; -
VAR_SAMP()(样本方差):计算样本方差,用于衡量数据的样本变异程度。
示例:
SELECT VAR_SAMP(temperature) AS sample_temperature_variance FROM weather_data;
其他常用函数
MySQL提供了一些其他常用函数,用于执行不同类型的操作,包括加密、字符串处理、日期和时间计算等。以下是一些其他常用的MySQL函数:
-
PASSWORD():用于对密码进行加密,通常用于用户认证。
示例:
SELECT PASSWORD('my_password') AS encrypted_password; -
MD5():计算字符串的MD5哈希值。
示例:
SELECT MD5('Hello, World!') AS md5_hash; -
SHA1():计算字符串的SHA-1哈希值。
示例:
SELECT SHA1('Hello, World!') AS sha1_hash; -
UUID():生成一个全局唯一标识符(UUID)。
示例:
SELECT UUID() AS unique_id; -
CONV():将一个数字从一种进制转换为另一种进制。
示例:
SELECT CONV('42', 10, 16) AS hex_value; -
INET_ATON():将IPv4地址表示的字符串转换为整数。
示例:
SELECT INET_ATON('192.168.1.1') AS ip_integer; -
INET_NTOA():将整数表示的IPv4地址转换为字符串。
示例:
SELECT INET_NTOA(3232235777) AS ip_string; -
UNIX_TIMESTAMP():将日期时间转换为Unix时间戳。
示例:
SELECT UNIX_TIMESTAMP('2023-11-01 12:00:00') AS unix_timestamp; -
FROM_UNIXTIME():将Unix时间戳转换为日期时间格式。
示例:
SELECT FROM_UNIXTIME(1646304000) AS formatted_datetime;
这些函数执行不同类型的操作,包括密码加密、哈希计算、UUID生成、进制转换、IPv4地址处理和日期时间转换等。您可以根据需要在SQL查询中使用这些函数来执行各种操作。
part5 进阶
存储引擎 MyISAM和INNODB对比

MySQL支持多种存储引擎,其中两个最常见的是MyISAM和InnoDB。它们在性能、特性和适用场景上有一些显著的差异。以下是MyISAM和InnoDB的详细对比:
1. 事务支持:
- InnoDB支持事务,具有ACID(原子性、一致性、隔离性、持久性)属性,允许您进行复杂的数据操作,并在出现故障时保持数据的完整性。
- MyISAM不支持事务,它不具备ACID属性,因此不适用于要求事务支持的应用程序。
2. 锁机制:
- InnoDB使用行级锁(row-level locking),这意味着不同事务可以同时访问表的不同部分,从而提高并发性。
- MyISAM使用表级锁(table-level locking),这导致了在高并发环境中性能下降,因为只能有一个事务访问整个表。
3. 外键约束:
- InnoDB支持外键约束,这使得在表之间建立关系以确保数据完整性成为可能。
- MyISAM不支持外键约束,因此它不能维护表之间的关系。
4. 数据一致性:
- InnoDB在发生故障或崩溃时更可靠,因为它支持事务日志和回滚段,可以更好地保持数据的一致性。
- MyISAM在某些故障情况下可能会导致数据损坏,因为它不具备事务支持。
5. 性能:
- MyISAM在某些情况下可以比InnoDB更快,尤其是在读密集型工作负载下,因为它使用表级锁,避免了额外的行级锁开销。
- InnoDB通常在写入密集型工作负载下性能更好,因为它支持并发写入操作,并且具有更好的数据一致性。
6. 全文搜索:
- MyISAM支持全文搜索功能,可以用于全文搜索引擎,如全文索引。
- InnoDB在原生状态下不支持全文搜索,但可以通过插件或外部工具实现此功能。
7. 空间占用:
- MyISAM通常在磁盘上占用更少的空间,因为它不支持事务日志和回滚段。
- InnoDB通常需要更多的磁盘空间,因为它记录事务和提供了更多的数据完整性。
8. 数据缓存:
- InnoDB使用自己的缓冲池来管理数据和索引的缓存,具有更高的性能,因为它可以在内存中缓存更多数据。
- MyISAM依赖于操作系统的缓存,性能较低,特别是在大型数据集上。
综上所述,选择MyISAM还是InnoDB取决于应用程序的需求。如果需要事务支持、数据完整性和较好的并发性能,InnoDB是更好的选择。如果应用程序主要是读取操作,且需要较小的存储空间,那么MyISAM可能更合适。不过,需要注意的是,MySQL的默认存储引擎从MySQL 5.5开始是InnoDB,这也表明InnoDB在许多应用场景中更受推荐。
字符集 以及utf8mb4介绍
CREATE TABLE your_table_name (
column1 INT,
column2 VARCHAR(255),
column3 TEXT
) ENGINE = InnoDB CHARSET = utf8mb4;
MySQL的字符集(Character Set)是用于存储文本数据的编码方式,它定义了如何将字符映射到二进制数据。字符集在数据库中非常重要,因为它影响了文本数据的存储、排序、比较和检索。MySQL支持多种字符集,每种字符集都有其特定的用途。以下是一些常见的MySQL字符集以及UTF8MB4的介绍:
-
UTF-8:UTF-8是一种可变长度的Unicode编码,广泛用于存储多种语言的文本数据。它支持1到4字节的字符编码,允许存储几乎所有已知的字符。UTF-8是MySQL的默认字符集,特别是在MySQL 5.5版本之后。
-
UTF8MB4:UTF8MB4是UTF-8的一种扩展,它支持存储更广泛的Unicode字符,包括一些不常用的表情符号和特殊符号。UTF8MB4适用于需要存储Emoji表情和其他非常用字符的应用,如社交媒体平台和国际化应用。
-
Latin1:Latin1字符集也称为ISO 8859-1,用于存储西欧语言中的文本数据。它支持许多西欧语言,但不支持非拉丁字符集的语言。
-
ASCII:ASCII字符集用于存储7位ASCII字符,只包含标准英文字母、数字和一些特殊符号。这是一种非常简单的字符集。
-
GBK:GBK字符集是用于存储中文文本数据的字符集,支持简体中文和繁体中文。
-
BIG5:BIG5字符集用于存储繁体中文文本数据,通常在台湾地区使用。
-
UTF16:UTF-16是Unicode编码的一种,使用2或4字节来表示字符。它支持几乎所有已知的字符,但通常占用更多的存储空间。
在MySQL中,您可以在创建表时或更改表的字符列时选择适当的字符集。UTF8MB4特别适合国际化应用,因为它可以存储几乎所有语言的字符。注意,使用UTF8MB4字符集可能会占用更多的存储空间,因此需要在性能和存储空间之间做权衡。
在MySQL 5.5之前的版本中,UTF8MB4可能不被默认支持,因此需要确保数据库服务器和客户端都支持该字符集。此外,确保应用程序正确配置以使用所需的字符集是非常重要的,以避免乱码和字符集不匹配的问题。
索引
在MySQL中,索引是一种用于提高查询性能的数据结构。索引可以加速数据检索,但也会占用额外的存储空间。以下是有关索引的创建、使用和删除的信息,以及一些常见的索引类型:
1 创建索引:
您可以在创建表时或在已存在的表上使用CREATE INDEX语句来创建索引。通常,索引可以在一个或多个列上创建。
(1).创建一个基本的单列索引:
CREATE INDEX index_name ON table_name (column_name);
(2).创建一个复合索引(多列索引):
CREATE INDEX index_name ON table_name (column1, column2, ...);
2.删除索引:
您可以使用DROP INDEX或ALTER TABLE语句来删除索引。
(1) 删除表上的索引:
DROP INDEX index_name ON table_name;
(2) 删除表中的所有索引:
ALTER TABLE table_name DROP INDEX ALL;
3.常见的索引类型:
-
B-Tree 索引:B-Tree(平衡树)索引是最常见的索引类型。它适用于等值查找、范围查找和排序操作。默认情况下,MySQL的普通索引就是B-Tree索引。
-
哈希索引:哈希索引适用于等值查找,但不支持范围查找和排序。MySQL的MEMORY存储引擎支持哈希索引。
-
全文索引:全文索引用于全文搜索,通常在文本列上使用。它允许您执行全文搜索和相关性排序操作。仅适用于支持全文搜索的存储引擎,如InnoDB。
-
空间索引:空间索引用于地理数据,支持空间数据的范围查询。MySQL的InnoDB存储引擎支持空间索引。
-
前缀索引:前缀索引是对列值的前缀创建的索引。它用于减小索引的大小,但可能降低查询性能。
-
唯一索引:唯一索引要求索引列的值是唯一的,用于确保数据完整性。如果插入或更新操作违反唯一性,将会引发错误。
请根据您的应用程序需求和查询模式选择适当的索引类型,以实现最佳性能。同时,谨慎创建索引,不要过度索引,因为过多的索引可能会增加数据的维护成本和降低写入性能。
4.复合索引的最左前缀原则
MySQL中使用复合索引时,遵循了最左前缀原则(Most-Left-Prefix Rule)。这个原则规定,在一个多列索引中,只有从索引的最左列开始的一系列连续列才会被用于索引查找和过滤。这也意味着这个索引可以用于支持由最左列开始的查询条件,但不一定适用于不包含前面列的查询条件。
举个例子,假设您有一个复合索引 (column1, column2, column3)。根据最左前缀原则,以下的情况是成立的:
- 这个索引可以用于支持包含
column1的查询条件,例如WHERE column1 = 'value'。 - 这个索引也可以用于支持包含
column1和column2的查询条件,例如WHERE column1 = 'value' AND column2 = 'value2'。 - 但这个索引不会被用于支持只包含
column2或column3的查询条件。
最左前缀原则的应用非常重要,因为它影响了索引的选择和性能。如果您有一个复合索引,要确保查询条件中的列按照索引列的顺序从左到右连续出现,以获得最佳的索引性能。如果查询条件不符合最左前缀原则,MySQL可能会选择不使用索引,而是执行全表扫描,这可能会导致性能下降。
此外,最左前缀原则还适用于排序和分组操作。如果查询中包含 ORDER BY 子句或 GROUP BY 子句,MySQL也会优先选择按照索引的最左前缀列进行排序或分组。
视图
在MySQL中,视图(View)是一个虚拟的表,它是基于一个或多个实际表的查询结果集的可查询对象。视图允许您以类似表的方式查询和操作数据,但实际上并不存储数据,而是根据视图的定义在查询时动态生成结果。下面是关于MySQL视图的介绍,包括创建、修改、删除和查看定义等操作:
1. 创建视图:
要创建一个视图,您可以使用CREATE VIEW语句。视图的定义是一个SELECT查询,该查询可以从一个或多个表中选择数据并进行任何必要的处理。以下是创建视图的示例:
CREATE VIEW view_name AS
SELECT column1, column2
FROM table_name
WHERE condition;
在上面的语句中,view_name 是视图的名称,table_name 是要查询的表,condition 是可选的筛选条件。
2. 修改视图:
要修改视图的定义,您可以使用ALTER VIEW语句。这允许您更改视图的查询定义,以适应新的查询需求。
ALTER VIEW view_name AS
SELECT new_columns
FROM new_table
WHERE new_condition;
3. 删除视图:
要删除视图,您可以使用DROP VIEW语句。
DROP VIEW view_name;
4. 查看视图定义:
您可以使用以下命令查看视图的定义:
SHOW CREATE VIEW view_name;
5. 使用视图:
一旦创建视图,您可以像查询表一样使用它。您可以执行SELECT、INSERT、UPDATE、DELETE等操作,就像操作实际表一样。
6. 更新视图:
视图是虚拟的,因此无法直接对视图进行INSERT、UPDATE或DELETE操作。但如果视图的定义中包括一个或多个可更新的表,您可以执行更新操作。
7. 视图的用途:
视图通常用于以下情况:
- 简化复杂查询:将复杂的查询逻辑封装到视图中,使查询更容易理解。
- 数据安全性:通过视图限制用户对表的访问,只允许他们访问特定的数据子集。
- 重用查询逻辑:在多个查询中重用相同的查询逻辑,而不必重复编写。
- 数据格式转换:将原始数据以某种方式格式化或转换为更适合报表或应用程序的形式。
视图是强大的数据库工具,可以提高查询的可读性和可维护性,并提供更好的数据安全性和重用性。
8.视图不可更新的条件
MySQL中的视图(View)不是所有情况下都可以更新的,有一些条件和限制,限制了视图的可更新性。以下是一些常见的视图不可更新的条件:
-
聚合函数和GROUP BY子句:如果视图的查询包括聚合函数(如SUM、AVG、COUNT等)或GROUP BY子句,通常视图是不可更新的。因为视图中的聚合函数和分组信息使得无法明确知道如何更新数据。
-
DISTINCT关键字:如果查询中包含DISTINCT关键字,视图通常也不可更新,因为DISTINCT操作导致结果集中的行不可预测。
-
计算列:如果视图包括计算列,这些列通常不可更新。计算列是指在视图中通过表达式计算的列,如
SELECT column1 + column2 AS calculated_column。 -
子查询:包含子查询的视图通常不可更新,因为子查询结果的变化可能导致不可预测的更新行为。
-
连接多个表:如果视图查询涉及多个表的连接,特别是使用了JOIN操作,通常情况下也不可更新。这是因为视图中的多表连接会使更新操作复杂化。
-
HAVING子句:如果查询中使用了HAVING子句,通常也不可更新。HAVING子句用于筛选GROUP BY的结果,因此更新操作可能导致不一致性。
-
不包含主键或唯一键的视图:视图通常需要基于具有唯一标识的列,如主键或唯一键,来支持更新。如果视图没有这些列,更新操作通常会受到限制。
-
使用了聚合函数的子查询:如果视图中的查询包含聚合函数的子查询,通常也不可更新。
需要注意的是,有一些特殊情况下,MySQL允许更新视图,例如通过使用WITH CHECK OPTION子句来限制更新的范围。但大多数情况下,视图用于查询而不是更新,而更新操作通常直接应用于基础表。
在使用视图时,要特别小心可更新性的限制,以确保不会出现意外的结果或数据不一致性。视图的设计应考虑到查询的需求和数据的安全性。
存储过程和函数
以下是MySQL中存储过程和函数的语法定义,以及一些示例,包括创建复杂的存储过程和函数,以实现修改和删除操作。
存储过程的语法定义:
DELIMITER //
CREATE PROCEDURE procedure_name([parameter1 datatype1, ...])
BEGIN
-- SQL statements
END //
DELIMITER ;
函数的语法定义:
DELIMITER //
CREATE FUNCTION function_name([parameter1 datatype1, ...])
RETURNS return_datatype
BEGIN
-- SQL statements
RETURN return_value;
END //
DELIMITER ;
以下是一个示例,创建一个存储过程和一个函数,用于修改和删除员工信息的数据库。这个示例使用了存储过程和函数,以演示它们如何被定义和使用。
创建存储过程:
DELIMITER //
CREATE PROCEDURE UpdateEmployeeSalary(employee_id INT, new_salary DECIMAL(10, 2))
BEGIN
UPDATE employees SET salary = new_salary WHERE id = employee_id;
END //
DELIMITER ;
在上面的示例中,UpdateEmployeeSalary 存储过程接受两个参数:employee_id 和 new_salary,并根据提供的 employee_id 更新员工的工资。
创建函数:
DELIMITER //
CREATE FUNCTION GetEmployeeCount(department_id INT)
RETURNS INT
BEGIN
DECLARE employee_count INT;
SELECT COUNT(*) INTO employee_count FROM employees WHERE department = department_id;
RETURN employee_count;
END //
DELIMITER ;
在上面的示例中,GetEmployeeCount 函数接受一个参数 department_id,并返回指定部门的员工数量。
修改存储过程和函数:
要修改存储过程和函数,您可以使用ALTER PROCEDURE和ALTER FUNCTION语句。例如:
DELIMITER //
ALTER PROCEDURE UpdateEmployeeSalary(employee_id INT, new_salary DECIMAL(10, 2))
BEGIN
-- Updated SQL statements
END //
DELIMITER ;
DELIMITER //
ALTER FUNCTION GetEmployeeCount(department_id INT)
RETURNS INT
BEGIN
-- Updated SQL statements
END //
DELIMITER ;
删除存储过程和函数:
要删除存储过程和函数,可以使用DROP PROCEDURE和DROP FUNCTION语句。例如:
DROP PROCEDURE UpdateEmployeeSalary;
DROP FUNCTION GetEmployeeCount;
这些示例展示了如何创建、修改和删除存储过程和函数,以实现对数据库的修改和删除操作。存储过程和函数可以包含更复杂的逻辑和多个SQL语句,以满足不同的需求。
触发器
在MySQL中,触发器(Trigger)是与表关联的数据库对象,用于在表上执行自动化的操作,以响应特定的事件,如INSERT、UPDATE或DELETE。以下是触发器的创建、使用、删除和查看操作,以及一些复杂的示例。
创建触发器的语法定义:
CREATE TRIGGER trigger_name
{BEFORE | AFTER} {INSERT | UPDATE | DELETE}
ON table_name FOR EACH ROW
BEGIN
-- Trigger logic
END;
trigger_name是触发器的名称。{BEFORE | AFTER}指定触发器在事件发生前还是之后执行。{INSERT | UPDATE | DELETE}指定触发器响应的事件类型。table_name是触发器关联的表。FOR EACH ROW表示触发器是针对每行记录执行的。
示例:创建一个AFTER INSERT触发器
下面是一个示例,创建一个触发器,当在 orders 表中插入新记录后,自动更新 order_count 列的值:
DELIMITER //
CREATE TRIGGER update_order_count
AFTER INSERT
ON orders FOR EACH ROW
BEGIN
UPDATE order_summary SET order_count = order_count + 1;
END;
//
DELIMITER ;
删除触发器的语法定义:
DROP TRIGGER [IF EXISTS] [schema_name.] trigger_name;
schema_name是可选的,表示触发器所属的模式。trigger_name是要删除的触发器的名称。
示例:删除触发器
以下是删除前面创建的触发器的示例:
DROP TRIGGER update_order_count;
查看触发器的定义:
要查看触发器的定义,您可以使用SHOW CREATE TRIGGER语句。
SHOW CREATE TRIGGER trigger_name;
示例:查看触发器的定义
SHOW CREATE TRIGGER update_order_count;
触发器可以执行复杂的操作,例如更新其他表、生成日志、或在满足特定条件时触发警报。它们是数据库的强大工具,但也需要谨慎使用,以避免不必要的复杂性。触发器通常用于实现数据完整性、审计、日志记录和自动化任务。