初识 Elasticsearch7.16.x(一)
初识 Elasticsearch7.16.x(一)
- 一、前序
-
- 简介
- 一图看懂 Elastic Stack?
- 二、基础
-
- 原理
- 类比
- 倒排索引
- cluster
- node
- document
- type(弃用)
- index
- shard
- replica
- Analysis
-
- 内置分词器
- 示例
- 三、安装
-
- Elasticsearch
- Kibana
-
- 设置中文
- elasticsearch-head
-
- 步骤
- 开启CROS
- IK 分词器
-
- 安装
一、前序
简介
Elasticsearch是一个基于**Apache Lucene™**的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elastic 官网:https://www.elastic.co/cn/
一图看懂 Elastic Stack?
参考:https://www.elastic.co/cn/what-is/elk-stack
Elastic 公司除了拥有 Elasticsearch 项目外,还拥有 Logstash 及 Kibana 等开源项目。将这三个项目组合在一起,就形成了 ELK Stack。他们三个共同形成了一个强大的生态圈。
简单地说,Logstash 负责数据的采集,处理(丰富数据,数据转换等),Kibana 负责数据展示,分析,管理,监督及应用。Elasticsearch 处于最核心的位置,它可以帮我们对数据进行快速地搜索及分析。
而 Elastic Stack 是 ELK Stack 的更新换代产品,在 ELK 中加入了 Beats。


二、基础
当我们开始使用 Elasticsearch 时,我们必须理解其中的一些重要的概念。这些概念的理解对于以后我们使用 Elastic 栈是非常重要的。
原理
终于有人把Elasticsearch原理讲透了!
类比
我们通过大家比较熟悉的 DBMS 与 ES 的基本概念进行类比,加深大家的理解。
| DBMS | Elasticsearch |
|---|---|
| Database | Index |
| Table | Type(7.0后type固定为_doc) |
| Row | Document |
| Column | Field |
| Schema | Mapping |
| SQL | DSL(Descriptor Structure Language) |
倒排索引
倒排索引,也是索引(一切设计都是为了提高搜索的性能)。
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的。
Elasticsearch 使用一种称为 倒排索引 的结构,它适用于快速的全文搜索。一个倒排索引由文档中所有不重复词的列表构成,对于其中每个词,有一个包含它的文档列表。
在没有搜索引擎时,我们是直接输入一个网址,然后获取网站内容,这时我们的行为是:
document -> to -> words
通过文章,获取里面的单词,此谓「正向索引」,forward index.
后来,我们希望能够输入一个单词,找到含有这个单词,或者和这个单词有关系的文章:
word -> to -> documents
于是我们把这种索引,成为 inverted index,直译过来,应该叫「反向索引」,国内翻译成「倒排索引」。
cluster
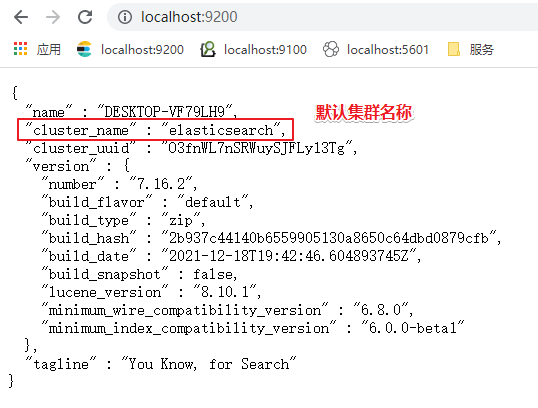
Cluster 也就是集群的意思。Elasticsearch 集群由一个或多个节点组成,可通过其集群名称进行标识。通常这个 Cluster 的名字是可以在 Elasticsearch 里的配置文件中设置的。在默认的情况下,如我们的 Elasticsearch 已经开始运行,那么它会自动生成一个叫做 “elasticsearch” 的集群。我们可以在 config/elasticsearch.yml 里定制我们的集群的名字:

node
单个 Elasticsearch 实例。 在大多数环境中,每个节点都在单独的盒子或虚拟机上运行。一个集群由一个或多个 node 组成。在测试的环境中,我可以把多个 node 运行在一个 server 上。在实际的部署中,大多数情况还是需要一个 server 上运行一个 node。
document
Elasticsearch 是面向文档的,这意味着你索引或搜索的最小数据单元是文档。文档在 Elasticsearch 中有一些重要的属性:
- 它是独立的。文档包含字段(名称)及其值。
- 它可以是分层的。可以将其视为文档中的文档。字段的值可以很简单,就像位置字段的值可以是字符串一样。它还可以包含其他字段和值。例如,位置字段可能包含城市和街道地址。
- 结构灵活。你的文档不依赖于预定义的架构。例如,并非所有事件都需要描述值,因此可以完全省略该字段。但它可能需要新的字段,例如位置的纬度和经度。
type(弃用)
类型是文档的逻辑容器,类似于表是行的容器。 你将具有不同结构(模式)的文档放在不同类型中。
由于一些 原因,在 Elasticsearch 6.0 以后,一个 Index 只能含有一个 type。这其中的原因是:相同 index 的不同映射 type 中具有相同名称的字段是相同; 在 Elasticsearch 索引中,不同映射 type 中具有相同名称的字段在 Lucene 中被同一个字段支持。在默认的情况下是 _doc。在未来8.0的版本中,type 将被彻底删除。
index
在 Elasticsearch 中,索引是文档的集合。
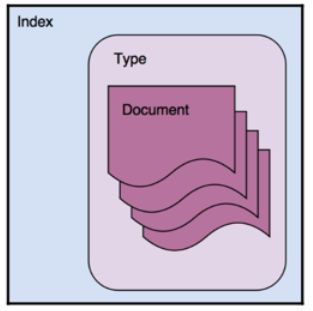
很多人认为 index 类似于关系数据库中的 database。这中说法是有些道理,但是并不完全相同。其中很重要的一个原因是,在Elasticsearch 中的文档可以有 object 及 nested 结构。一个 index 是一个逻辑命名空间,它映射到一个或多个主分片,并且可以具有零个或多个副本分片。
每当一个文档进来后,根据文档的 id 会自动进行 hash 计算,并存放于计算出来的 shard 实例中,这样的结果可以使得所有的 shard 都比较有均衡的存储,而不至于有的 shard 很忙。
shard_num = hash(_routing) % num_primary_shards
从上面的公式我们也可以看出来,我们的 shard 数目是不可以动态修改的,否则之后也找不到相应的 shard 号码了。必须指出的是,replica 的数目是可以动态修改的。
shard
由于 Elasticsearch 是一个分布式搜索引擎,因此索引通常会拆分为分布在多个节点上的称为分片的元素。 Elasticsearch 自动管理这些分片的排列。 它还根据需要重新平衡分片,因此用户无需担心细节。
一个索引可以存储超出单个结点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。
为了解决这个问题,Elasticsearch 提供了将索引划分成多份的能力,这些份就叫做分片(shard)。当你创建一个索引的时候,你可以指定你想要的分片(shard)的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。
分片之所以重要,主要有两方面的原因:
- 允许你水平分割/扩展你的内容容量
- 允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量
有两种类型的分片:primary shard 和 replica shard。
Primary shard: 每个文档都存储在一个Primary shard。 索引文档时,它首先在 Primary shard上编制索引,然后在此分片的所有副本上(replica)编制索引。索引可以包含一个或多个主分片。 此数字确定索引相对于索引数据大小的可伸缩性。 创建索引后,无法更改索引中的主分片数。
Replica shard: 每个主分片可以具有零个或多个副本。 副本是主分片的副本,有两个目的:
- 增加故障转移:如果主要故障,可以将副本分片提升为主分片。即使你失去了一个 node,那么副本分片还是拥有所有的数据
- 提高性能:get 和 search 请求可以由主 shard 或副本 shard 处理。
默认情况下,每个主分片都有一个副本,但可以在现有索引上动态更改副本数。我们可以通过如下的方法来动态修改副本数:
PUT my_index/_settings
{
"number_of_replicas": 2
}
replica
默认情况下,Elasticsearch 为每个索引创建一个主分片和一个副本。这意味着每个索引将包含一个主分片,每个分片将具有一个副本。
分配多个分片和副本是分布式搜索功能设计的本质,提供高可用性和快速访问索引中的文档。主副本和副本分片之间的主要区别在于只有主分片可以接受索引请求。副本和主分片都可以提供查询请求。
在上图中,我们有一个 Elasticsearch 集群,由默认分片配置中的两个节点组成。 Elasticsearch 自动排列分割在两个节点上的一个主分片。有一个副本分片对应于每个主分片,但这些副本分片的排列与主分片的排列完全不同。
请允许我们澄清一下:请记住,number_of_shards 值与索引有关,而不是与整个群集有关。此值指定每个索引的分片数(不是群集中的主分片总数)。
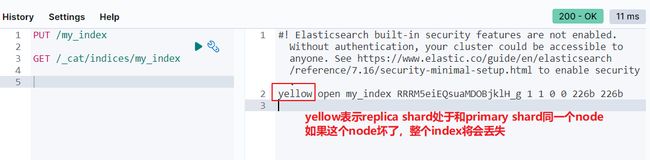
我们可以通过如下的接口来获得一个 index 的健康情况:
GET /_cat/indices/my_index
Analysis
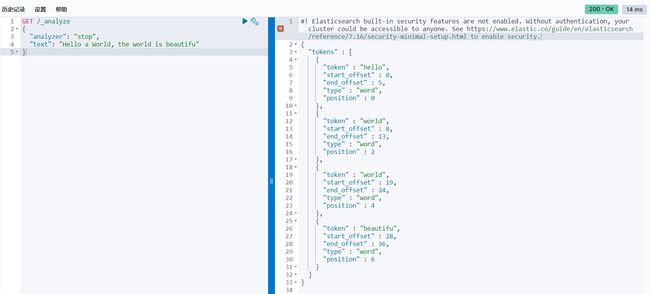
analysis(只是概念),文本分析是将全文本转换为一系列单词的过程,也叫分词。analysis是通 过analyzer(分词器)来实现的,可以使用Elasticsearch内置的分词器,也可以自己去定制一些分词 器。 除了在数据写入的时候进行分词处理,那么在查询的时候也可以使用分析器对查询语句进行分词。
anaylzer是由三部分组成,例如有
Hello a World, the world is beautifu
-
Character Filter: 将文本中html标签剔除掉。
-
Tokenizer: 按照规则进行分词,在英文中按照空格分词。
-
Token Filter: 去掉stop world(停顿词,a, an, the, is, are等),然后转换小写
内置分词器

示例
以 Stop Analyzer ,小写处理,停用词过滤为例
三、安装
Elasticsearch 和 Kibanna:https://www.elastic.co/cn/start
version: 7.16.2
阿里云盘:https://www.aliyundrive.com/s/Jt7t4NNZMrd
Elasticsearch
进入到 elasticsearch 解压目录下的 bin 目录下,双击 elasticsearch.bat 即可启动。
如果本地有JAVA环境,默认使用本地的,如果没有,则使用 elasticsearch 自带的
在浏览器地址栏输入: http://localhost:9200/ ,如果出现如下页面表示 elasticsearch 启动成功

Kibana
进入到 kibana 解压目录下的 bin 目录下,双击 kibana.bat 即可启动。
在浏览器地址栏输入:http://localhost:5601,出现如下页面代表 kibana 启动成功。
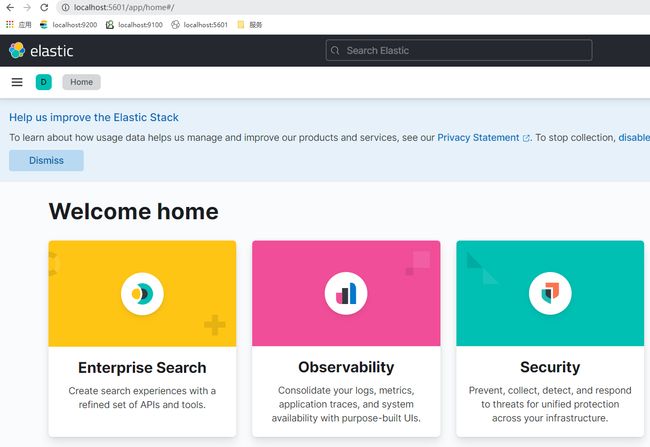
设置中文
进入到 kibana 解压目录下的 config 目录下,修改 kibana.yml 文件。

重启 Kibana 服务即可。
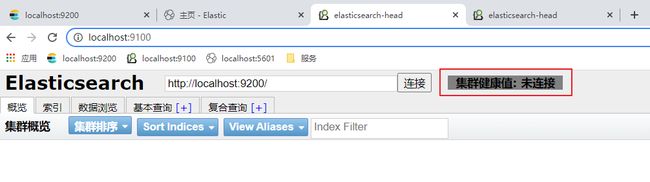
elasticsearch-head
elasticsearch-head将是一款专门针对于elasticsearch的客户端工具, elasticsearch-head配置包。
下载地址:https://github.com/mobz/elasticsearch-head
步骤
-
git clone git://github.com/mobz/elasticsearch-head.git -
cd elasticsearch-head -
npm install -
npm run start -
openhttp://localhost:9100/
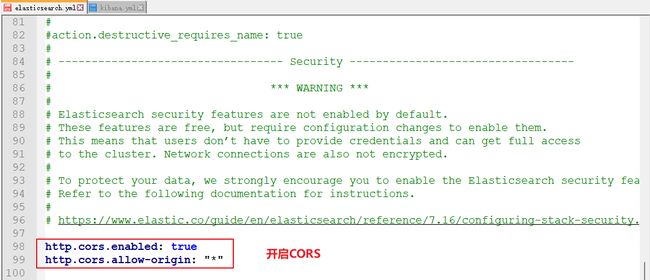
开启CROS
在 elasticsearch 配置文件中添加:
- add
http.cors.enabled: true - you must also set
http.cors.allow-originbecause no origin allowed by default.http.cors.allow-origin: "*"is valid value, however it’s considered as a security risk as your cluster is open to cross origin from anywhere.
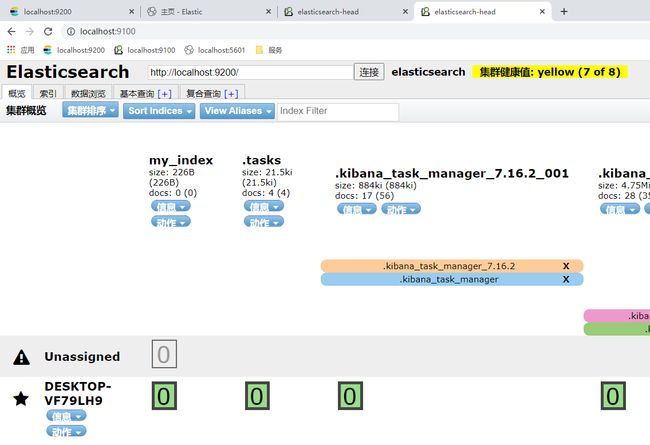
重启 elasticsearch 服务即可
IK 分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
使用了Elasticsearch中默认的标准分词器,这个分词器在处理中文的时候会把中文单词切分成一个一个的汉字,因此引入IK分词器就能解决这个问题。
The IK Analysis plugin integrates Lucene IK analyzer (http://code.google.com/p/ik-analyzer/) into elasticsearch, support customized dictionary.
Analyzer: ik_smart , ik_max_word , Tokenizer: ik_smart , ik_max_word

安装
1、在 elasticsearch/plugins 目录中新建 ik 文件夹
cd your-es-root/plugins/ && mkdir ik
2、将下载的压缩包解压到 ik 文件夹即可

3、重启 elasticsearch 服务
