2023一区优化套用:KOA-CNN-BiGRU-Attention融合注意力机制预测程序代码!直接运行!
适用平台:Matlab 2023版及以上
KOA开普勒优化算法,于2023年5月发表在SCI、中科院1区Top顶级期刊《Knowledge-Based Systems》上。


同样的,我们利用该新鲜出炉的算法对我们的CNN-BiGRU-Attention时序和空间特征结合-融合注意力机制的回归预测程序代码中的超参数进行优化,构成KOA-CNN-BiGRU-Attention多变量回归预测模型。
这篇论文介绍了一种名为开普勒优化算法(Kepler optimization algorithm,KOA)的新型元启发式算法,并对其进行了评估。KOA算法受开普勒行星运动定律的启发,旨在解决连续优化问题。在KOA中,每个行星及其位置代表一个候选解,通过根据迄今为止的最佳解(太阳)进行随机更新来实现优化过程,从而更有效地探索和利用搜索空间。通过使用各种基准问题对KOA算法的性能进行评估,并与其他随机优化算法进行比较。结果表明,KOA在收敛性和统计数据方面优于其他优化器。
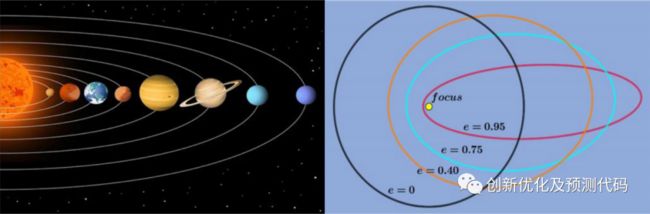
KOA的开普勒优化步骤主要包括初始化行星位置和速度、根据适应度函数评估每个行星的适应度、更新每个行星的位置和速度、更新最佳解(太阳)位置、重复执行更新步骤直到达到停止条件等。这些步骤使得KOA能够在优化过程中更好地探索和利用搜索空间。
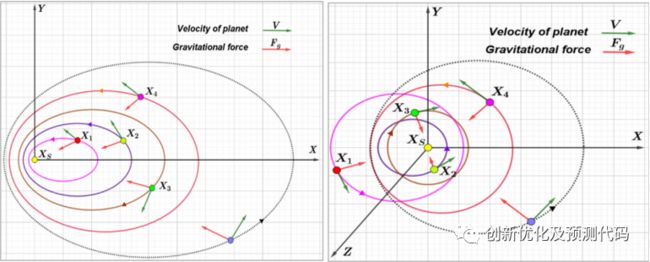
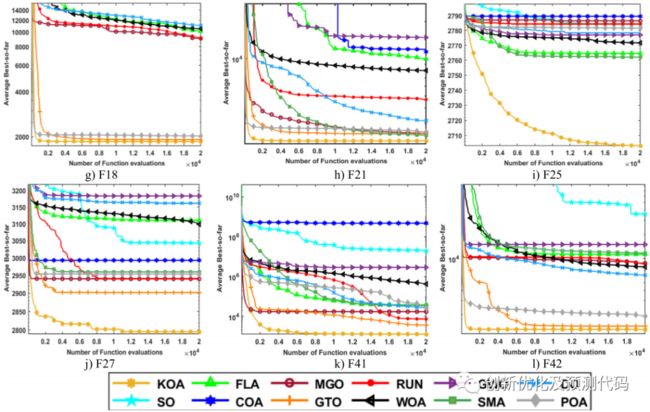
KOA算法与多种优化算法进行了比较,包括Swarm Optimization (SO)、Fick’s Law Algorithm (FLA)、Coati Optimization Algorithm (COA)、Pelican Optimization Algorithm (POA)、Dandelion Optimizer (DO)、Mountain Gazelle Optimizer (MGO)、Artificial Gorilla Troops Optimizer (GTO)、Slime Mold Algorithm (SMA)、Whale Optimization Algorithm (WOA)、Grey Wolf Optimizer (GWO)等。结果表明,KOA在收敛性和统计数据方面优于这些比较算法。
构成的KOA-CNN-BiGRU-Attention多变量回归预测模型的创新性在于以下几点:
KOA算法区别于传统智能算法的创新性:
①受到开普勒行星运动定律的启发:KOA算法受到开普勒行星运动定律的启发,将每个行星的位置作为候选解,并通过随机更新这些候选解来进行优化过程。这种设计使得KOA算法能够更有效地探索和利用搜索空间。
②基于物理学的元启发算法:KOA算法属于物理学的元启发算法,通过模拟行星围绕太阳的运动规律来进行优化。它利用行星的位置、质量、引力和轨道速度等参数来控制候选解的更新过程。这种基于物理学的方法使得KOA算法在全局优化问题上具有更好的可解释性。
③对比其他优化算法的优越性:通过与其他随机优化算法进行对比实验,KOA算法在收敛性和统计数据方面表现出色。实验结果表明,KOA算法在多个基准问题上优于其他比较算法。这表明KOA算法在解决优化问题时具有更高的效果和性能。
优化套用—基于开普勒优化算法(KOA)、卷积神经网络(CNN)和双向门控循环单元 (BiGRU)融合注意力机制(SelfAttention)的超前24步多变量时间序列回归预测算法KOA-CNN-BiGRU-Attention:
功能:
1、多变量特征输入,单序列变量输出,输入前一天的特征,实现后一天的预测,超前24步预测。
2、通过KOA优化算法优化学习率、卷积核大小、神经元个数,这3个关键参数,以最小MAPE为目标函数。
3、提供损失、RMSE迭代变化极坐标图;网络的特征可视化图;测试对比图;适应度曲线(若首轮精度最高,则适应度曲线为水平直线)。
4、提供MAPE、RMSE、MAE等计算结果展示。
适用领域:风速预测、光伏功率预测、发电功率预测、碳价预测等多种应用。
预测值与实际值对比;训练特征可视化:

训练误差曲线的极坐标形式(误差由内到外越来越接近0);适应度曲线(误差逐渐下降)

KOA部分核心代码:
% 计算太阳和第i个行星的引力,根据普遍的引力定律:
for i = 1:SearchAgents_no
Rnorm(i) = (R(i) - min(R)) / (max(R) - min(R)); %% 归一化的R(Eq.(24))
MSnorm(i) = (MS(i) - min(MS)) / (max(MS) - min(MS)); %% 归一化的MS
Mnorm(i) = (m(i) - min(m)) / (max(m) - min(m)); %% 归一化的m
Fg(i) = orbital(i) * M * ((MSnorm(i) * Mnorm(i)) / (Rnorm(i) * Rnorm(i) + eps)) + (rand); %% Eq.(6)
end
% a1表示第i个解在时间t的椭圆轨道的半长轴,
for i = 1:SearchAgents_no
a1(i) = rand * (T(i)^2 * (M * (MS(i) + m(i)) / (4 * pi * pi)))^(1/3); %% Eq.(23)
end
for i = 1:SearchAgents_no
% a2是逐渐从-1到-2的循环控制参数
a2 = -1 - 1 * (rem(t, Tmax / Tc) / (Tmax / Tc)); %% Eq.(29)
% ξ是从1到-2的线性减少因子
n = (a2 - 1) * rand + 1; %% Eq.(28)
a = randi(SearchAgents_no); %% 随机选择的解的索引
b = randi(SearchAgents_no); %% 随机选择的解的索引
rd = rand(1, dim); %% 按照正态分布生成的向量
r = rand; %% r1是[0,1]范围内的随机数
%% 随机分配的二进制向量
U1 = rd < r; %% Eq.(21)
O_P = Positions(i, :); %% 存储第i个解的当前位置
%% 第6步:更新与太阳的距离(第3、4、5在后面)
if rand < rand
% h是一个自适应因子,用于控制时间t时太阳与当前行星之间的距离
h = (1 / (exp(n * randn))); %% Eq.(27)
% 基于三个解的平均向量:当前解、迄今为止的最优解和随机选择的解
Xm = (Positions(b, :) + Sun_Pos + Positions(i, :)) / 3.0;
Positions(i, :) = Positions(i, :) .* U1 + (Xm + h .* (Xm - Positions(a, :))) .* (1 - U1); %% Eq.(26)
else
%% 第3步:计算对象的速度
% 一个标志,用于相反或离开当前行星的搜索方向
if rand < 0.5 %% Eq.(18)
f = 1;
else
f = -1;
end
L = (M * (MS(i) + m(i)) * abs((2 / (R(i) + eps)) - (1 / (a1(i) + eps))))^(0.5); %% Eq.(15)
U = rd > rand(1, dim); %% 一个二进制向量
if Rnorm(i) < 0.5 %% Eq.(13)
M = (rand .* (1 - r) + r); %% Eq.(16)
l = L * M * U; %% Eq.(14)
Mv = (rand * (1 - rd) + rd); %% Eq.(20)
l1 = L .* Mv .* (1 - U);%% Eq.(19)
V(i, :) = l .* (2 * rand * Positions(i, :) - Positions(a, :)) + l1 .* (Positions(b, :) - Positions(a, :)) + (1 - Rnorm(i)) * f * U1 .* rand(1, dim) .* (ub - lb); %% Eq.(13a)
else
U2 = rand > rand; %% Eq. (22)
V(i, :) = rand .* L .* (Positions(a, :) - Positions(i, :)) + (1 - Rnorm(i)) * f * U2 * rand(1, dim) .* (rand * ub - lb); %% Eq.(13b)
end %% 结束IF
%% 第4步:逃离局部最优
% 更新标志f以相反或离开当前行星的搜索方向
if rand < 0.5 %% Eq.(18)
f = 1;
else
f = -1;
end
%% 第5步
Positions(i, :) = ((Positions(i, :) + V(i, :) .* f) + (Fg(i) + abs(randn)) * U .* (Sun_Pos - Positions(i, :))); %% Eq.(25)
end %% 结束IF
完整代码:https://mbd.pub/o/bread/ZZeTm5Zy部分图片来源于网络,侵权联系删除!
欢迎感兴趣的小伙伴关注我们的公众号,或点击上方链接获得完整版代码哦~,关注小编会继续推送更有质量的学习资料、文章程序代码~
