Elasticsearch简易入门讲解
PDF版下载链接:https://download.csdn.net/download/taoruicheng1/85047119
1. Elasticsearch初识
1.1. Elasticsearch是什么?
- Elasticsearch 是一个分布式的、开源的搜索分析引擎,支持各种数据类型,包括文本、数字、地理、结构化、非结构化。它可以让你快速和近乎实时地存储、搜索和分析海量的数据,可弹性扩展到上百台服务器规模,处理PB级结构化或非结构化数据。
- Elasticsearch 是基于 Apache Lucene 的。
- Elasticsearch 因其简单的 REST API、分布式特性、快速、可扩展而闻名。
1.2. Elasticsearch的使用场景
- 存储
ElasticSearch天然支持分布式,具备存储海量数据的能力,其搜索和数据分析的功能都建立在ElasticSearch存储海量的数据之上。例如:收集爬虫数据。
- 搜索
ElasticSearch使用倒排索引,每个字段都被索引且可用于搜索,更是提供了丰富的搜索api,在海量数据下近实时实现近秒级的响应。具体场景:
- Stack Overflow,可根据关键字搜索相关问题。
- GitHub(开源代码管理),搜索上千亿行代码。
- 电商网站,检索商品。
- 日志数据分析(ELK技术,elasticsearch+logstash+kibana)
- 数据分析
使用ElasticSearch的聚合功能,进行数据分析。
2. Elasticsearch的数据类型
2.1. 数据类型列表

2.2. text与keyword有什么区别?
这两个字段都可以存储字符串使用,但建立索引和搜索的时候是不太一样的:
- keyword: keyword 类型适用于索引结构化的字段,比如 email 地址、主机名、状态码和标签,通常用于过滤(比如,查找已发布博客中 status 属性为 published 的文章)、排序、聚合。类型为
keyword 的字段只能通过精确值搜索到,区别于 text 类型。- text: 如果一个字段是要被全文搜索的,比如邮件内容、产品描述、新闻内容,应该使用 text 类型。设置 text 类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分词器分成一个一个词项(term)。text
类型的字段不用于排序,且很少用于聚合(Terms Aggregation 除外)。
2.3. 日期类型详解
JSON 中没有日期类型,所以在 Elasticsearch 中的日期可以是以下几种形式:
- 格式化日期的字符串,如 “2015-01-01” 或 “2015/01/01 12:10:30”。
- 代表 milliseconds-since-the-epoch 的长整型数(epoch 指的是一个特定的时间:1970-01-01 00:00:00 UTC)。
- 代表 seconds-since-the-epoch 的整型数。
Elasticsearch 内部会把日期转换为 UTC(世界标准时间),并将其存储为表示 milliseconds-since-the-epoch 的长整型数,这样做的原因是和字符串相比,数值在存储和处理时更快。
*设置了字段为date类型后,插入"dt": “2019-11-14”、“dt”: “2019-11-14T13:16:302”、 “dt”: 1673664468000 3 文档的日期格式都可以被解析,内部存储的是毫秒计时的长整型数。
2.4. 数组类型
Elasticsearch 没有专用的数组类型,默认情况下任何字段都可以包含一个或者多个值,但是一个数组中的值必须是同一种类型。例如:
- 字符数组:[“one”,“two”]
- 整型数组:[1,3]
- 嵌套数组:[1,[2,3]],等价于 [1,2,3]
- 对象数组:[{“city”:“SH”,“country”:“cn”},{“city”:“BJ”,“country”:“cn”}]
* 动态添加数据时,数组的第一个值的类型决定整个数组的类型。
2.5. nested 类型
nested 类型是 object 类型中的一个特例,可以让对象数组独立索引和查询。(详细介绍见下一章)。
2.6. geo_point 地理坐标
geo point 类型用于存储地理位置信息的经纬度,可用于以下几种场景:
- 查找一定范围内的地理位置。
- 通过地理位置或者相对中心点的距离来聚合文档。
- 把距离因素整合到文档的评分中。
- 通过距离对文档排序。
****geo_point 字段接收以下 4 种类型的地理位置数据
- 经纬度坐标键值对: “lat”: 41.12,“lon”: -71.34
- 字符串格式的地理坐标参数:“41.12,-71.34”
- 地理坐标的哈希值:“u1269qu5dcgp”
- 数组形式的地理坐标:[-71.34, 41.12]
2.7. ES实际是如何索引复杂对象的?
2.7.1. 向ES添加一个复杂对象
Put /user/_doc/1
{
"role": {
"name":"admin",
"describe":"系统管理员"
},
"user": [{
"first": "Bai",
"last": "Li"
}, {
"first": "Fu",
"last": "Du"
}]
}
2.7.2. ES把复杂对象映射成key-value 对
上面的文档中,整体是一个 JSON 对象,JSON 中包含一个 role对象和user数组;写入到 Elasticsearch 之后,文档会被索引成简单的扁平 key-value 对,格式如下:
{
"role.name":"admin",
"role.describe":"系统管理员",
"user.first":["Bai","Fu"],
"user.last":["Li","Du"]
}
2.7.3. 数组对象相关性丢失
通过上面的映射可以发现,user数组中的{first: Bai} 和 {last: Li} 之间的相关性已经丢失了,所以在查询操作的时候,无法查询到一个叫李白的人。
{
"query": {
"bool": {
"must": [{
"match": {
"user.first": "Bai"
}
},
{
"match": {
"user.last": "Li"
}
}]
}
}
}
*只要数组中有李XX和XX白的记录都会被查出来,要解决这个问题,就用到了Nested对象。
**2.7.4. **Nested嵌套对象
nested 对象类型可以保持数组中每个对象的独立性。下面先来设置Nested类型的映射关系。
{
"mappings": {
"properties": {
"user": {
"type": "nested",
"properties": {
"first": {"type": "keyword"},
"last": {"type": "keyword"}
}
}
}
}
}
使用如下查询,即可查询出姓名为李白的人。
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "user",
"query": {
"bool": {
"must": [
{
"match": {
"user.first": "Bai"
}
},
{
"match": {
"user.last": "Li"
}
}
]
}
}
}
}
]
}
}
}
3. 理解ES基本概念
3.1. 理解index、type
index为ES中的索引,type为ES中的类型,不过从ES7.X版本开始已经弃用了type的概念。在使用中,index(或index别名)和type出现在url路径中,用来定位要处理的数据,具体理解如下:
- 站在使用者的角度考虑的话,index和type仅仅是url路径中的一个值。
- 站在开发者的角度讲,index就相当于表,type就相当于表的一个字段,定义了这些数据的类型。
__补充说明:__ES 7.X版本为什么已经移除了Type的概念?
- ES中同一个index中不同type是存储在同一个索引中的(lucene的索引文件),因此不同type中相同名字的字段的定义(mapping)必须一致;
- 另外在同一个index中存储含有不同字段的文档会导致稀疏数据并干扰Lucene高效压缩文档的能力,降低es效率。
3.2. 常用ESURL介绍
为了加深理解index、type概念,下面列出了常用的ES URL:

3.3.向ES中存储数据
简单向大家介绍下如何往ES中存储数据:
PUT my-index-000001/_doc/1
{
"age": 79,
"name": {
"full": "John Smith",
"first": "John",
"last": "Smith"
},
"address": "35 Chauncey Street, Grazierville, Missouri",
"createdAt": "2021-03-16",
"updatedAt": "22021-03-16 01:16:30"
}
* 如未显示设置索引字段的映射(mapping),Elasticsearch 自动识别推测出字段的类型,并固定到配置文件中。
3.4.ES数据类型映射
概念:在 Elasticsearch 中,映射指的是 mapping,用来定义一个文档以及其所包含的字段如何被存储和索引,可以在映射中事先定义字段的数据类型、字段的权重、分词器等属性,就如同在关系型数据库中创建数据表时会设置字段的类型。
把JSON格式数据存放入ES后,若未显示设置字段的mapping关系的话,ES会自动推断数据的存储类型,且建立mapping关系之后数据类型就固定下来了。
上一节JSON存储到ES后,会自动映射为如下格式:
{
"account": {
"mappings": {
"_doc": {
"properties": {
"address": {"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},
"age": {"type":"long"},
"createdAt": {"type":"date"},
"name": {"properties":{"first":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"full":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}},"last":{"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}}}},
"updatedAt": {"type":"text","fields":{"keyword":{"type":"keyword","ignore_above":256}}}
}
}
}
}
}
解读下生成映射的含义:
- 如果不指定类型,ElasticSearch字符串将默认被同时映射成text和keyword类型,例如上面的"address"、"name.first"等。本质上生成了两个字段"address"的 text 类型字段和 address.keyword 的 keyword 类型字段。
- ignore_above:忽略长度超过256字符串。
3.4.1.静态映射
概念:静态映射是在创建索引时手工指定索引映射,和 SQL 中在建表语句中指定字段属性类似。相比动态映射,通过静态映射可以添加更详细、更精准的配置信息。
3.4.2.动态映射
概念:动态映射是一种偷懒的方式,可直接创建索引并写入文档,文档中字段的类型是 Elasticsearch 自动识别的,不需要在创建索引的时候设置字段的类型。在实际项目中,如果遇到的业务在导入数据之前不确定有哪些字段,也不清楚字段的类型是什么,使用动态映射非常合适。当 Elasticsearch 在文档中碰到一个以前没见过的字段时,它会利用动态映射来决定该字段的类型,并自动把该字段添加到映射中。
根据字段的取值自动推测字段类型的规则见下表:
| JSON 格式的数据 | 自动推测的字段类型 |
|---|---|
| null | 没有字段被添加 |
| — | — |
| true or false | boolean 类型 |
| 浮点类型数字 | float 类型 |
| 数字 | long 类型 |
| JSON 对象 | object 类型 |
| 数组 | 由数组中第一个非空值决定 |
| string | 有可能是 date 类型(若开启日期检测)、double 或 long 类型、text 类型、keyword 类型 |
4.ES基础查询介绍
Elasticsearch 查询语句采用基于 RESTful 风格的接口封装成 JSON 格式的对象,称之为 Query DSL。Elasticsearch 查询分类 大致分为全文查询、词项查询、复合查询、嵌套查询、位置查询、特殊查询。
Elasticsearch 从查询 机制** 来讲 , 分为两种: 一种是根据用户输入的查询词,通过排序模型计算文档与查询词之间的相关度,并根据评分高低排序返回;另一种是 过滤机制**,只根据过滤条件对文档进行过滤,不计算评分,速度相对较快。即分为:query和filter(boolfilter)两类。
下面先看一个查询的例子。
4.1.ES简单查询demo
post /account/_doc/_search?pretty
{
"query": {
"match": {
"address":"Gallatin Place"
}
},
"from": 0,
"size": 10
}
上面仅仅是一个最简单的查询,实际上ES可支持很多类型的查询操作,下面先介绍下ES的查询分类。
4.2.query和bool查询区别
ES查询分为query、filter(bool查询)两类。这两种查询有什么区别呢?下面先看下两者个概念解释。
4.2.1.概念解释
Query** :**在查询上下文中,查询子句回答"此文档与此查询子句匹配程度如何?"的问题。除了决定文档是否匹配外,查询子句还会在 _score 元字段中计算相关性分数。
Filter** :**在过滤器上下文中,查询子句回答"此文档是否与此查询子句匹配?"的问题。答案是简单的 Yes 或 No —— 不计算分数。Filter主要对文档进行过滤,例如 这个时间戳是否在 2015 年到 2016 年的范围内? 状态字段是否设置为"已发布"?
4.2.2.Query和Filter(bool查询)的区别
1** )使用方面:**
filter仅仅只是按照搜索条件过滤出需要的数据而已,不计算任何相关度分数,对相关度没有任何影响;
query会去计算每个document相对于搜索条件的相关度,并按照相关度进行排序。
一般来说,如果你是在进行搜索,需要将最匹配搜索条件的数据先返回,那么用query;如果你只是要根据一些条件筛选出一部分数据,不关注其排序,那么用filter。
2** )性能方面:**
filter不计算相关度分数,不按照相关度分数进行排序,同时还有内置的自动cache最常使用filter的数据;
query相反,要计算相关度分数,按照分数进行排序,而且无法cache结果。
4.3.ES Query查询语法
ES的查询根据是否分词(对查询时输入的字符串是否分词),分为"Full text query"和"Term-level query"。
-
Full text query** :**对文字进行分词之后,再进行查询。例如查询"hello world"的时候,会通过空格分为"hello"和"world"两个词之后,再进行查询。
-
Term-level query** :**查询不会再对query内容进行analysis分词处理,直接将query当做一个单词处理。例如:例如查询"hello world"的时候,仅匹配"hello world"。
| 大类 | 小类 | 解释 | 例子 |
|---|---|---|---|
| 分词匹配检索 | match_all | 查询全部记录 | {"query": {"match_all": {}}} |
| match | 对内容分词之后,查询ES进行匹配 | {"query": {"match": {"address":"Gallatin Place"}}} | |
| query_string | 分词后进行匹配,支持AND、OR等DSL语言。不指定fields,默认会在当前index所有可以查询的字段中进行查询。 | {"query": {"query_string": {"query":"Gallatin AND Place","fields":["address"]}}} | |
| match_phrase | 查询短语 | {"query": {"match_phrase": {"address":{"query":"33 Street","slop": 1}}}} | |
| combined_fields | 查询多个字段 | {"query": {"combined_fields" : {"query":"database systems","fields":["title", "abstract", "body"],"operator": "and"}}} | |
| multi_match | 查询多个字段 | ||
| 精确匹配查询 | exists | ||
| {"query": {"exists": {"field": "user"}} | |||
| Fuzzy | 模糊匹配 | {"query": {"fuzzy": {"address": {"value": "roa"}}}} | |
| Ids | 查询id | {"query": {"ids" : {"values" : ["1", "4", "100"]}}} | |
| prefix前缀查询 | 前缀查询 | {"query": {"prefix": {"name": {"value": "sc"}}}} | |
| range | range范围查询 | {"query": {"range": {"age": {"gte": 10, "lte": 20, "boost": 2.0}}}} | |
| term查询(不进行分词) | 适合对价格、商品ID、用户名查询 | {"query": {"term": {"address": {"value": "street", "boost": 1.0} }}} | |
| wildcard通配符查询 | 通配符查询 | {"query": {"wildcard": {"company": "inv*re"}}} |
通过上面的例子可以看出,ES查询的基本语法为如下格式的JSON:
{
"query": {
"查询操作类型(match、query_string等)": {
}
}
}
4.4.Bool(filter)查询语法
_bool查询映射到Lucene的BooleanQuery查询,用来查询与boolean条件匹配的文档;它由一个或者多个boolean子句组成。下面看下_BooleanQuery查询例子。
4.4.1.BooleanQuery查询例子
POST _search
{
"query": {
"bool" : {
"must" : {
"term" : { "user.id" : "kimchy" }
},
"filter": {
"term" : { "tags" : "production" }
},
"must_not" : {
"range" : {
"age" : { "gte" : 10, "lte" : 20 }
}
},
"should" : [
{ "term" : { "tags" : "env1" } },
{ "term" : { "tags" : "deployed" } }
],
"minimum_should_match" : 1,
"boost" : 1.0
}
}
}
4.4.2.BooleanQuery查询语法
| Boolean** 查询条件操作符 ** | ** 解释 ** | ** 上述例子解析** |
|---|---|---|
| must | 文档必须匹配must中的条件,并计算分值。must里的条件必须全部为true才能返回。 | 查询user.id匹配kimchy的记录。 |
| filter | 必须匹配,但对返回的score无影响,只是根据过滤标准来排除或包含文档。(不计分) | 返回所有文档的tags字段包含production内容的记录。 |
| should | should则是包含的条件里有一个条件为true就返回,如果满足这些语句中的任意语句,将增加 _score的分值。可以通过设置minimum_should_match的值(数值或者百分比),来设置需要满足should中的几个条件。*当bool查询包含should,不包含must或者filter的时候,minimum_should_match的默认值为1,否则为0。 | 文档的tags字段为env1或者deployed |
| must_not | 文档 必须不 匹配这些条件才能被包含进来。 | 年龄不在10-20岁之间 |
_通过上面的例子可以看出,_bool元素包含must、must_not、filter、should四个操作符,操作符中又可以包含查询条件(可以包含match、term、range等等查询语法,又可包含bool查询子句)。
4.4.3.BooleanQuery例子解析
1)下面的查询用于查找 title 字段匹配 how to make millions 并且不被标识为 spam 的文档。那些被标识为 starred 或在2014之后的文档,将比另外那些文档拥有更高的排名,如果 两者 都满足,那么它排名将更高。
{
"query": {
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }},
{ "range": { "date": { "gte": "2014-01-01" }}}
]
}
}
}
- 带filter的查询
{
"query": {
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"range": { "date": { "gte": "2014-01-01" }}
}
}
}
}
range 查询移到 filter 语句中, date 的内容将不再影响文档的 score 分值。
3)bool嵌套
{
"query": {
"bool": {
"must": { "match": { "title": "how to make millions" }},
"must_not": { "match": { "tag": "spam" }},
"should": [
{ "match": { "tag": "starred" }}
],
"filter": {
"bool": {
"must": [
{ "range": { "date": { "gte": "2014-01-01" }}},
{ "range": { "price": { "lte": 29.99 }}}
],
"must_not": [
{ "term": { "category": "ebooks" }}
]
}
}
}}}
4.5.对查询排序
在 Elasticsearch 中,默认排序是按照相关性的评分(_score)进行降序排序,也可以按照字段的值排序、多级排序、多值字段排序、基于 geo(地理位置)排序以及自定义脚本排序。
*计算 _score 的花销巨大
4.5.1.根据字段的值排序
在 Elasticsearch 中按照字段的值排序,可以利用 sort 参数实现。
GET books/_search
{
"sort": {
"price": {
"order": "desc"
}
}
}
4.5.2.多字段排序
如果我们想要结合使用 price、date 和 _score 进行查询,并且匹配的结果首先按照价格排序,然后按照日期排序,最后按照相关性排序,具体示例如下:
GET books/_search
{
"query": {
"bool": {
"must": {
"match": { "content": "java" }
},
"filter": {
"term": { "user_id": 4868438 }
}
}
},
"sort": [{
"price": {
"order": "desc"
}
}, {
"date": {
"order": "desc"
}
}, {
"_score": {
"order": "desc"
}
}
]
}
排序条件的顺序是很重要的。结果首先按第一个条件排序,仅当结果集的第一个 sort 值完全相同时才会按照第二个条件进行排序,以此类推。
5.其他高级查询
5.1.复合查询
复合查询就是把一些简单查询组合在一起实现更复杂的查询需求,除此之外,复合查询还可以控制另外一个查询的行为。主要包括:
| 复合查询 | 解释 |
|---|---|
| bool query | bool 查询可以把任意多个简单查询组合在一起,使用 must、should、must_not、filter 选项来表示简单查询之间的逻辑,每个选项都可以出现 0 次到多次 |
| boosting query | boosting 查询用于需要对两个查询的评分进行调整的场景,boosting 查询会把两个查询封装在一起并降低其中一个查询的评分。boosting 查询包括 positive、negative 和 negative_boost 三个部分,positive 中的查询评分保持不变,negative 中的查询会降低文档评分,negative_boost 指明 negative 中降低的权值。 |
| constant_score query | constant_score query 包装一个 filter query,并返回匹配过滤器查询条件的文档,且它们的相关性评分都等于 boost 参数值(可以理解为原有的基于 tf-idf 或 bm25 的相关分固定为 1.0,所以最终评分为 1.0 * boost,即等于 boost 参数值)。 |
| dis_max query | dis_max query 与 bool query 有一定联系也有一定区别,dis_max query 支持多并发查询,可返回与任意查询条件子句匹配的任何文档类型。与 bool 查询可以将所有匹配查询的分数相结合使用的方式不同,dis_max 查询只使用最佳匹配查询条件的分数 |
| function_score query | function_score query 可以修改查询的文档得分,这个查询在有些情况下非常有用,比如通过评分函数计算文档得分代价较高,可以改用过滤器加自定义评分函数的方式来取代传统的评分方式。 |
| indices query | indices query 适用于需要在多个索引之间进行查询的场景,它允许指定一个索引名字列表和内部查询。indices query 中有 query 和 no_match_query 两部分,query 中用于搜索指定索引列表中的文档,no_match_query 中的查询条件用于搜索指定索引列表之外的文档。 |
5.1.1.boosting调整评分查询
如果我们想对 2015 年之前出版的书降低评分,可以构造一个 boosting 查询,查询语句如下:
GET books/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": "python"
}
},
"negative": {
"range": {
"publish_time": {
"lte": "2015-01-01"
}
}
},
"negative_boost": 0.2
}
}
}
boosting 查询中指定了抑制因子为 0.2,publish_time 的值在 2015-01-01 之后的文档得分不变,publish_time 的值在 2015-01-01 之前的文档得分为原得分的 0.2 倍。
5.1.2.indices多索引查询
下面的查询语句实现了搜索索引 books、books2 中 title 字段包含关键字 javascript,其他索引中 title 字段包含 basketball 的文档,查询语句如下:
GET books/_search
{
"query": {
"indices": {
"indices": ["books", "books2"],
"query": {
"match": {
"title": "javascript"
}
},
"no_match_query": {
"term": {
"title": "basketball"
}
}
}
}
}
5.2.位置查询
Elasticsearch 可以对地理位置点 geo_point 类型和地理位置形状 geo_shape 类型的数据进行搜索,搜索类型包括:
| 搜索类型 | 解释 |
|---|---|
| geo_distance query | 可以查找在一个中心点指定范围内的地理点文档。例如,查找距离天津 200km 以内的城市;按各城市离北京的距离排序: |
| geo_bounding_box query | 用于查找落入指定的矩形内的地理坐标。查询中由两个点确定一个矩形,然后在矩形区域内查询匹配的文档。 |
| geo_polygon query | 用于查找在指定多边形内的地理点。例如,呼和浩特、重庆、上海三地组成一个三角形,查询位置在该三角形区域内的城市。 |
| geo_shape query | geo_shape query 用于查询 geo_shape 类型的地理数据,地理形状之间的关系有相交、包含、不相交三种。创建一个新的索引用于测试,其中 location 字段的类型设为 geo_shape 类型。 |
5.2.1.初始化数据
为了学习方便,这里准备一些城市的地理坐标作为测试数据,每一条文档都包含城市名称和地理坐标这两个字段,这里的坐标点取的是各个城市中心的一个位置。首先把下面的内容保存到 geo.json 文件中:
{{"index":{ "_index":"geo","_id":"1" }}
{"name":"北京","location":"39.9088145109,116.3973999023"}
{"index":{ "_index":"geo","_id": "2" }}
{"name":"乌鲁木齐","location":"43.8266300000,87.6168800000"}
{"index":{ "_index":"geo","_id": "3" }}
{"name":"西安","location":"34.3412700000,108.9398400000"}
{"index":{ "_index":"geo","_id": "4" }}
{"name":"郑州","location":"34.7447157466,113.6587142944"}
{"index":{ "_index":"geo","_id": "5" }}
{"name":"杭州","location":"30.2294080260,120.1492309570"}
{"index":{ "_index":"geo","_id": "6" }}
{"name":"济南","location":"36.6518400000,117.1200900000"}
*** 最后要有个换行 , 不然报错 : The bulk request must be terminated by a newline [\n]**
5.2.2.创建一个索引并设置映射:
PUT geo
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"location": {
"type": "geo_point"
}
}
}
}
5.2.3.然后执行批量导入命令:
curl -XPOST "http://localhost:9200/_bulk?pretty" --data-binary @geo.json
5.2.4.geo_distance query例子
可以查找在一个中心点指定范围内的地理点文档。
- 查找距离天津 200km 以内的城市
geo_distance query 可以查找在一个中心点指定范围内的地理点文档。例如,查找距离天津 200km 以内的城市,搜索结果中会返回北京,命令如下:
GET geo/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_distance": {
"distance": "200km",
"location": {
"lat": 39.0851000000,
"lon": 117.1993700000
}
}
}
}
}
}
- 按各城市离北京的距离排序:
GET geo/_search
{
"query": {
"match_all": {}
},
"sort": [{
"_geo_distance": {
"location": "39.9088145109,116.3973999023",
"unit": "km",
"order": "asc",
"distance_type": "plane"
}
}]
}
其中 location 对应的经纬度字段;unit 为 km 表示将距离以 km 为单位写入到每个返回结果的 sort 键中;distance_type 为 plane 表示使用快速但精度略差的 plane 计算方式。
5.2.5.geo_bounding_box query例子
用于查找落入指定的矩形内的地理坐标。查询中由两个点确定一个矩形,然后在矩形区域内查询匹配的文档。
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 38.4864400000,
"lon": 106.2324800000
},
"bottom_right": {
"lat": 28.6820200000,
"lon": 115.8579400000
}
}
}
}
}
}
}
5.2.6.geo_polygon query例子
geo_polygon query 用于查找在指定多边形内的地理点。例如,呼和浩特、重庆、上海三地组成一个三角形,查询位置在该三角形区域内的城市,命令如下:
{
"query": {
"bool": {
"must": {
"match_all": {}
}
},
"filter": {
"geo_polygon": {
"location": {
"points": [{
"lat": 40.8414900000,
"lon": 111.7519900000
}, {
"lat": 29.5647100000,
"lon": 106.5507300000
}, {
"lat": 31.2303700000,
"lon": 121.4737000000
}]
}
}
}
}
}
6.聚合查询
Elasticsearch 的聚合功能十分强大,可在数据上做复杂的分析统计。它提供的聚合分析功能有 指标聚合(** metrics aggregations ) 、 桶聚合( bucket aggregations ) 、 管道聚合( pipeline aggregations ) 三**大类。(官网:https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html)
6.1.聚合的具体结构
所有的聚合,无论它们是什么类型,都遵从以下的规则:
- 使用同样的 JSON 请求来定义它们,而且你是使用键 aggregations 或者是 aggs 来进行标记。需要给每个聚合起一个名字,指定它的类型以及和该类型相关的选项。
- 它们运行在查询的结果之上。和查询不匹配的文档不会计算在内,除非你使用 global 聚集将不匹配的文档囊括其中。
6.1.1.聚合的基本格式
{
"size": 0, <!–size为0的话,不会返回符合条件的记录,仅返回统计结果–>
"query": {},<!–查询条件,仅对符合条件的数据进行聚合计算–>
"aggregations" : { <!-- 最外层的聚合键,也可以缩写为 aggs -->
"<aggregation_name>" : { <!-- 聚合的自定义名字 -->
"<aggregation_type>" : { <!-- 聚合的类型,指标相关的,如 max、min、avg、sum,桶相关的 terms、filter 等 -->
<aggregation_body> <!-- 聚合体:对哪些字段进行聚合,可以取字段的值,也可以是脚本计算的结果 -->
}
[,"meta" : { [<meta_data_body>] } ]? <!-- 元 -->
[,"aggregations" : { [<sub_aggregation>]+ } ]? <!-- 在聚合里面在定义子聚合 -->
}
[,"<aggregation_name_2>" : { … }]* <!-- 聚合的自定义名字 2 -->
}
}
6.1.2.查询示例
查询所有球员的平均年龄是多少,统计为每名球员加 188 后的平均薪水。
POST /player/_search?size=0
{
"aggs": {
"avg_age": {
"avg": {
"field": "age"
}
},
"avg_salary_188": {
"avg": {
"script": {
"source": "doc.salary.value + 188"
}
}
}
}
}
6.2.指标聚合(Metrics aggregations)
解释:指标聚合(又称度量聚合)主要从不同文档的分组中提取统计数据,其中的min、max、sum等操作与数据库的相关概念一致。
对于聚合查询包含很多类型,新的ES版本支持的聚合查询方式更丰富,具体支持的可查看官网(https://www.elastic.co/guide/en/elasticsearch/reference/8.1/index.html),下面只统计常用的指标聚合查询。
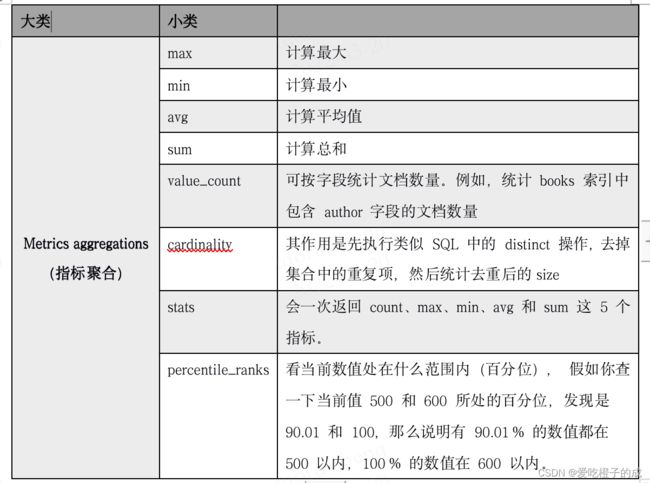
下面列举一个查询最小价格的例子:
GET /sales/_search?size=0
{
"aggs" : {
"min_price" : {
"min" : {
"field" : "price"
}
}
}
}
6.3.桶聚合(bucket aggregations)
解释:bucket 可以理解为一个桶,它会遍历文档中的内容,凡是符合某一要求的就放入一个桶中,分桶相当于 SQL 中的 group by。从另外一个角度,可以将指标聚合看成单桶聚合,即把所有文档放到一个桶中,而桶聚合是多桶型聚合,它根据相应的条件进行分组。
| 种类 | 描述** / **场景 |
|---|---|
| 词项聚合(Terms Aggregation) | 用于分组聚合,让用户得知文档中每个词项的频率,它返回每个词项出现的次数。 使用场景** :**返回出现最频繁的词。 |
| — | — |
| 差异词项聚合(Significant Terms Aggregation) | 它会返回某个词项在整个索引中和在查询结果中的词频差异,这有助于我们发现搜索场景中有意义的词。 |
| 过滤器聚合(Filter Aggregation) | 指定过滤器匹配的所有文档到单个桶(bucket)。 使用场景** :**找到性别为男的人的数量;找到性别为男的人的数量,并计算这些人的平均年龄(filter与avg配合使用)。 |
| 多过滤器聚合(Filters Aggregation) | 指定多个过滤器匹配所有文档到多个桶(bucket)。 使用场景** :**分别统计男女有多少人,和他们的平均年龄。 |
| 范围聚合(Range Aggregation) | 范围聚合,用于反映数据的分布情况。 使用场景** :**返回年龄段人数分布情况。 |
| 日期范围聚合(Date Range Aggregation) | 专门用于日期类型的范围聚合。 使用场景** : 与 rage aggregation 类似 , 只不过这里的 ranges 条件为日期 **。 |
| IP 范围聚合(IP Range Aggregation) | 用于对 IP 类型数据范围聚合。 |
| 直方图聚合(Histogram Aggregation) | 可能是数值,或者日期型,和范围聚集类似。 |
| 时间直方图聚合(Date Histogram Aggregation) | 时间直方图聚合,常用于按照日期对文档进行统计并绘制条形图。 使用场景** :**按照天、月、年统计数据。 |
| 空值聚合(Missing Aggregation) | 空值聚合,可以把文档集中所有缺失字段的文档分到一个桶中。 |
| 地理点范围聚合(Geo Distance Aggregation) | 用于对地理点(geo point)做范围统计。 |
下面举个根据账户新建的日期,统计每月新增人数的例子:
post/account/_search?size=0
{
"aggs": {
"sales_over_time": {
"date_histogram": {
"field": "createdAt",
"calendar_interval": "month"
}
}
}
}
7.结束语
上面为面向入门者写的简单的ES入门手册,掌握了上述内容之后,应付正常工作和使用已经绰绰有余了。
需要了解更多ES内容的同学可以移步官网(https://www.elastic.co/guide/en/elasticsearch/reference/current/getting-started.html),对于英文阅读困难的同学可访问中文网站(https://www.elastic.co/guide/cn/elasticsearch/guide/current/getting-started.html),但中文网站的内容比较老旧,是基于 Elasticsearch 2.x 版本编写。