01-AI大模型智能客服 V0.1「上」
你好,我是悦创。
首发:https://mp.weixin.qq.com/s/6MTkpWZCEbFWOcUn0Vexvw
V0.1 版本我将分为上中下三篇进行书写和发布,欢迎分享和我微信进讨论群:Jiabcdefh。
计划:
- 会迭代好几个版本,看阅读量和点赞、分享、赞赏啥的。有人看和学还有支持我的,我就会加速更新。
- 每个版本预估3篇,三篇结束看情况是否录成视频,大家可以选择众筹让我录成视频,众筹达到200元,我就开始录视频。;
- 众筹方法:公众号尾部赞赏我~
迷时师渡,悟了自渡。「是度还是渡」。
- 纯实战,纯代码,讲落地。
- 一个项目,递进式地为你深入浅出。
1. V0.1 大纲
- 对话机器人的产品设计
- 大语言模型的使用
- 提示词工程
- 开发环境讲解
- 工程化代码讲解
- 答疑和总结
2. 安装库
安装 openai、pandas、tiktoken。
# 这里是依赖库,运行代码前需要先安装
!pip install openai pandas tiktoken
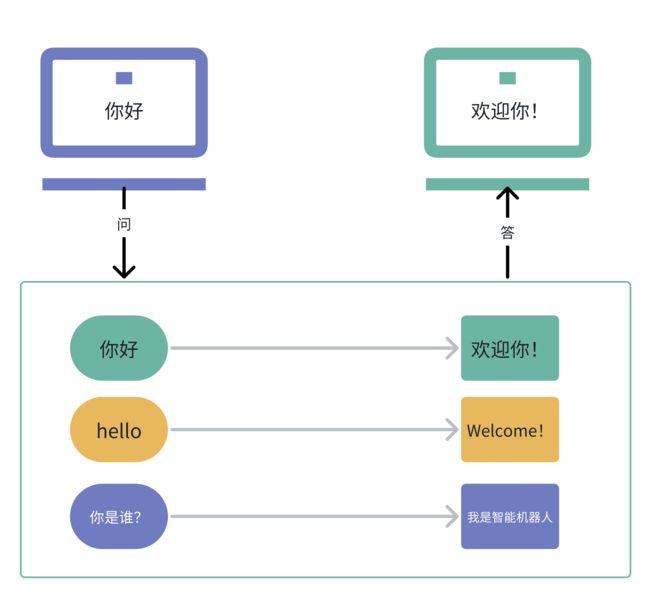
3. 早期的对话系统
早期,没有大语言模型的时候,我们对话系统是如何实现的?
def AssistantResponse(user_message):
if user_message in ["你好", "Hello", "Bonjour"]:
return "欢迎您!"
elif user_message in ["你是谁", "你叫什么名字"]:
return "我是机器人小悦"
else:
return "不好意思,我没能理解您的问题"
简单的调用进行体验一下:
user_message = "你好"
print(f'User: {user_message}\nAssistant: {AssistantResponse(user_message)}')
输出:
User: 你好
Assistant: 欢迎您!
我们可以再进行测试:
user_message = "你是"
print(f'User: {user_message}\nAssistant: {AssistantResponse(user_message)}')
输出:
User: 你是
Assistant: 不好意思,我没能理解您的问题
继续测试:
user_message = "你是谁"
print(f'User: {user_message}\nAssistant: {AssistantResponse(user_message)}')
输出:
User: 你是谁
Assistant: 我是机器人小悦
所以,你应该到这里能发现。我们现在的机器人能不能正常回答,取决于:我们有没有提前预判用户可能会问的问题。这种情况下,按目前的代码,只能使用穷举法。——但是,实际上是不可能的,一种语言都做不完。何况,有各类语言。用户换一种提问方式,机器人也会失效,所以早期这种实现是有很大局限性的。
中间还经历过各种不同技术驱动的系统,例如最经典的 RASA …意图识别,技能,填槽,动作
现在,有了大模型的加持,一切都不同了…
4. 大模型初体验
import openai
# openai.api_key = 'Raplace to your API Key'
openai.api_key = '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'
prompt = ["问题:介绍一下 AI悦创·编程一对一是什么类型的公司\n回答:"]
response = openai.Completion.create(engine="text-davinci-002", prompt=prompt, temperature=0, max_tokens=1024)
print(response['choices'][0]['text'])
输出:
AI悦创·编程一对一是一家专注于为学生提供个性化编程教育的公司。我们提供针对性的课程设置和专业的师资队伍,帮助学生学习编程,培养创新能力和解决问题的能力。
可以看见,上面大语言模型的回答并不是那么合适。会给你一个虚假的回答,也就是不懂装懂。所以,我们也需要自己拥有辨别能力。
我们,可以通过提示工程或者向量数据库等,都可以进行解决。
5. 小悦技术全景图
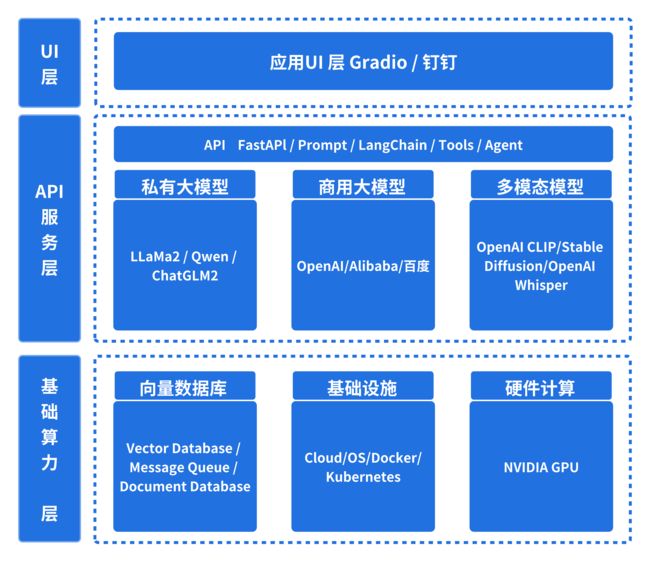
首先来看就是我们小悦技术架构图怎么来设计。
首先的话就是我们无论做怎样的软件系统,它都是需要有一个硬件把这个东西跑起来。我们实际上会用到 OpenAI 的 GPT 的模型,也会用到我们私有化部署的 LLaMa2 的模型,还有各种各样的 AI 模型。
那这些模型,有些是需要通过本地私有化的方式来部署,那就需要用到 GPU 了。那上层的话可能就是我们要做服务交付的时候,会用到容器相关的技术。那就会用到云计算相关的算力资源,然后还有像 docker 这种容器管理的工具和平台。
在最上层,我们利用各种中间件来解决特定的问题,例如前面提到的三种数据库。中间层则涵盖了各种大型模型,如 LAMA Two、Checker M2、OpenAI 的 GPT 模型,以及我们先前使用的 Tax Da Vinci 02 等。而在最底层,我们将进行大量的工程封装,将这些模型转化为 API,并通过UI进行简洁的展示。简而言之,这就是我们课程的核心内容,并且可以被概括为一张图。
6. 小悦关键流程图
其实,提到如 OpenAI GPT或者拉玛这样的技术,我相信大家都不陌生。但具体的实现流程是怎样的呢?其实非常直接:只要用户提出问题,系统便会给出答复,就这么简单。
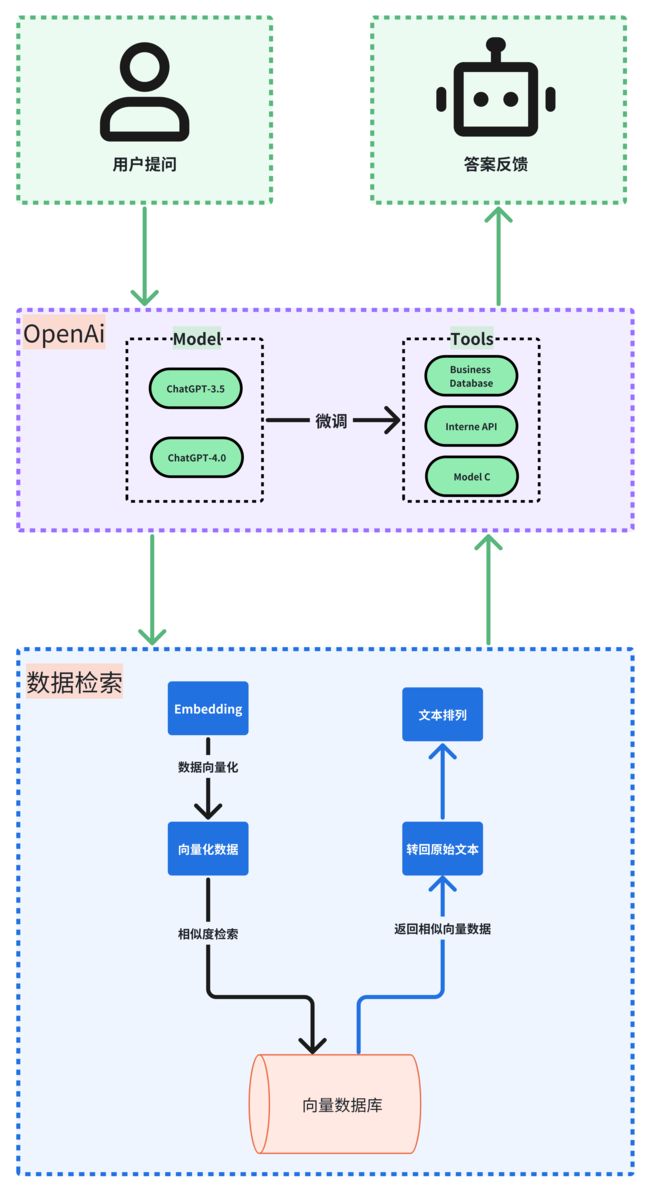
当然,这是一个基本的流程。
但在实际应用中,我们会增加很多复杂性。为什么要这样做?因为简单的流程容易导致我们最初展示的那种幻觉「答非所问」问题。针对这个幻觉问题,之前我们提到过有多种解决方法。而在这门课程中,我们会采用这些方法来逐一解决这个问题。
首先,我们可以采用向量数据库的方法或者微调模型来减少幻觉的发生。这涉及到许多核心技术,例如,如何最大化地利用 OpenAI 的模型以获得最佳效果。此外,如何微调一个模型或使用向量数据库来解决特定问题都是充满挑战的话题。
这门课程涵盖的内容,只要大家能够掌握,无疑可以助你们实现个人目标,包括升职加薪等。
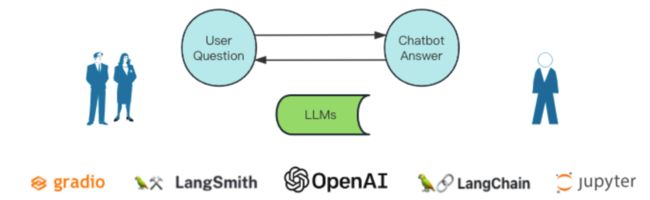
我们已经详细介绍了不少内容。那么,如何实现“小悦 V0.1”呢?
我们的目标是找到一个最简单的方法,使“小悦V0.1”这个版本得以实现。实际上,我们刚刚深入讨论了一个最基础的系统,用户只需提交一个问题,系统便会为其提供答复。整个过程是由一个大型模型驱动的。在实现过程中,我们还会在 UI 上使用 gradio,同时借助 LangChain 来搭建服务,利用某个开发框架进行中间过程的开发,再用 Jupyter 来调试我们的代码。
7. 小悦 V0.1 介绍
幻觉的存在导致回复的不是我们想要的,小悦对话机器人应运而生,开始打造 V0.1 版本
要造一个小悦机器人需要些什么
- 得封装下服务来调用下大语言模型;
- 需要了解下大语言模型如何调用;
- 需要有一个前端来给用户操作;
- 需要知道用户使用的好不好;
- …
总而言之,先做一个 POC 来验证下是可行性
“POC”是“Proof Of Concept”的缩写,中文常译为“概念验证”。这是一个实验或原型,其目的是验证某个想法、概念或理论在实际应用中是否可行。通过POC,开发者或研究者可以验证某个解决方案在特定场景中是否有效,从而避免在完整开发之前浪费时间和资源。
在我上面写出:“总而言之,先做一个 POC 来验证下是可行性”就是说,在全面开发或实施之前,先制作一个原型或实验来确认这个想法或方法是否真的可行。