亚马逊云科技Amazon Bedrock大语言模型加速OCR场景精准提取
背景介绍
光学字符识别(OCR)技术在识别印刷体或手写体文字方面已经取得了显著的进展,但仍然存在一些常见问题和挑战。以下是一些常见的OCR技术问题:
(一)文字质量:OCR系统对文字质量要求较高,如果文本模糊、扭曲、模糊不清或遭受损坏,识别准确率可能会降低。
(二)手写体识别:手写体文字识别是一个更具挑战性的任务,因为手写文字的风格和形状变化较大,而且可能存在连接、断开、变形等问题。
(三)文档类型多样性:处理不同类型的文档(如表格、报告、手写笔记等)需要OCR系统具备适应性,这可能需要更复杂的模型和处理流程。
(四)上下文理解:对于某些应用,理解文本的上下文是必要的,但传统的OCR技术可能缺乏这种上下文感知能力。

OCR技术是人们日常使用最多的AI场景,但处理以上问题仍遇到了很大的挑战。本文的目的是帮助大家通过亚马逊云科技OCR以及生成式AI(Gen-AI)产品加速关键内容提取与整理。
亚马逊云科技OCR相关产品/解决方案
(1)Amazon Textract是一种机器学习(ML)服务,可自动从任意文档或图像中提取文本、手写和数据。使用Amazon Textract的AnalyzeDocument API可提供表格功能,提供从任何文档中自动提取表格结构的功能。
(2)Amazon Rekognition是一项功能强大的图像和视频分析服务,可提取图像中的信息并提供深入洞察。其中的图像文本识别功能专门用于处理真实世界的图像,而不仅仅是文档图像。它支持大多数拉丁语书写体文本以及数字,并且可以识别嵌入在各种布局中、采用不同字体和样式、在不同方向上作为横幅和海报覆盖在背景对象上的文本。
(3)AWS AI Solution Kit提供一系列开箱即用的云上AI功能,例如:多语种高阶文字识别(OCR)、通用自然语言理解(NLU)、通用物体识别、图像超分、图片相似度、人像分割等。特别是AWS AI Solution Kit增强了对于简体中文语言识别能力。
通过使用亚马逊云科技提供的这三款OCR产品/解决方案,可以有效解决文字质量低、手写体识别等问题。尤其是Amazon Textract能够处理多种文件格式,包括JPG、PNG、PDF等,并且能够处理扫描文档和手机拍摄的图片。除了提取文档中的内容(包括表格和表单字段等结构化数据),Amazon Textract还可以在满足个人隐私信息(PII)保护的前提下,分析发票、收据或身份证中的相关数据。
在进行OCR内容提取时,文件内容格式不固定且需要上下文语义理解,仅使用OCR无法完全解决这个问题。在这种情况下,引入大语言模型可以很好地帮助我们克服这些局限性,并加速文本内容的精确提取。
基于Bedrock进行OCR关键信息提取方案
Amazon Bedrock介绍
Amazon Bedrock服务于2023年9月28日正式可用,这是使用基础模型构建和扩展生成性人工智能应用程序的最简单方法。Amazon Bedrock是一项完全托管的服务,提供来自AI21 Labs、Anthropic、Cohere、Meta、Stability AI和Amazon等领先提供商的高性能基础模型,以及客户构建生成式AI应用程序所需的一套广泛功能,简化开发,同时维护隐私和安全。
在Amazon Bedrock上,用户可以享受可扩展、可靠且安全的亚马逊云科技托管服务,无需管理基础设施。
用户可以访问从文本到图像的一系列强大的基础模型,包括新发布的Amazon Titan基础模型。用户可以轻松找到适合自身业务的模型,快速上手。
用户可以在确保数据安全和隐私保护的前提下,使用自有数据基于基础模型进行定制。Bedrock最重要的能力之一是极其容易定制模型。客户只需向Bedrock展示Amazon S3中的几个标注好的数据示例,Bedrock就可以针对特定任务微调模型,最少仅需20个示例即可,而无需标注大量数据。
没有任何用户数据被用于训练底层模型。所有数据都进行了加密,且不会离开用户的虚拟私有网络(VPC),因此用户完全可以确信获得数据安全和隐私保护。

Claude模型介绍与使用申请
通过Bedrock您可以快速访问Claude API。Claude V2具有更好的性能和更长的回复时间。用户可以在每个提示中输入多达100K,这意味着Claude可以处理数百页的技术文档甚至一本书。更重要的是,Claude在交流中表现出色,能够清晰地解释其思路,几乎不会产生有害的输出,并且具有超强的记忆力。
在编码、数学和推理方面,最新的模型在法学考试的多项选择部分得分为76.5%,而Claude1.3的得分为73.0%。与申请研究生院的大学生相比,Claude2在GRE阅读和写作考试中超过了90%的排名,并且在定量推理方面与中位数申请者成绩相当。

当您首次登陆Bedrock时,需要通过左下角模型列表(Model Access)中选择,请求访问在Bedrock中使用的模型。比如Anthropic Claude模型能首先需要提交一些使用详细信息,然后才能获得访问权限。请注意,只有具有所需IAM权限的用户才能管理此帐户的模型访问权限。

实现方案架构

操作配置
Amazon Lambda配置说明
进入到Lambda控制台,按照以下配置创建一个新的函数。
-
函数名称:填写你的函数名称,如bedrock_demo
-
运行时:选择Python 3.10
-
架构:选择x86_64
-
权限:创建具有基本Lambda权限的新角色
-
点击创建函数
创建完Lambda函数之后,修改Lambda函数配置,方便后续进行测试。
-
首先修改Lambda函数的超时时间,设置为1分钟
创建名为bedrock的策略

-
Lambda函数的角色权限,点击该角色,并将以下2个策略(AmazonS3FullAccess,AmazonTextractFullAccess),以及刚创建的bedrock策略附加到该角色上

由于Amazon Bedrock需要特定版本的Boto3 SDK,因此需要进行下载安装,并通过Layer的方式上传到Lambda中。
-
以下脚本会下载boto3最新版本,re-zip并将其上传到S3存储桶当中,上传完之后进行删除
-
需要将BUCKET_NAME替换为你的S3存储桶,该存储桶与你的Lambda函数在同个区域
-
另外需要修改.sh文件的权限
在Lambda创建Layer层,并将存储在S3存储桶的zip文件上传
-
BUCKET_NAME替换为存储zip文件的存储桶
-
点击创建

-
为你的Lambda函数添加刚才创建的Layer层

Amazon API Gateway配置说明
进入到API Gateway控制台,按照以下配置创建一个新的函数。
-
创建REST API
-
API详细信息:选择新建API
-
API名称:填写你的API名称,如my_api
-
点击创建API
创建完API之后,点击创建方法,方便我们后续进行测试。

在以下创建方法的界面中进行配置。
-
方法类型:选择POST类型
-
集成类型:选择Lambda函数
-
Lambda函数:选择在1部分创建的Lambda函数
-
点击创建方法

在该POST方法中,在集成请求将Lambda代理集成开启

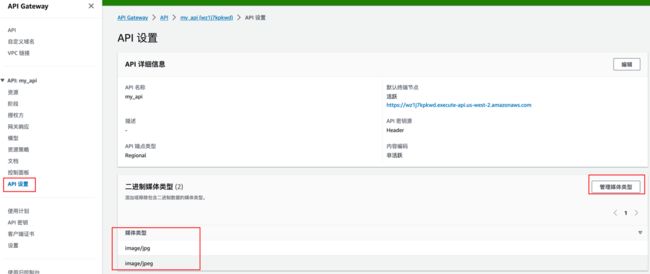
在API设置将二进制媒体类型添加image/jpg以及image/jpeg
在创建的API界面,点击部署API,选择一个新阶段,并添加阶段名称

在阶段选择你创建的阶段,并复制调用URL,后续使用该URL进行测试

Amazon Lambda代码实现
将代码复制到Lambda函数中,并点击Deploy进行部署。
结果验证
如下图验光处方单由于格式不统一或医生笔记难以识读,提取关键参数具有一定难度。为快速获取处方参数,采用大模型Claude对包含内容注释的问题文本进行语义理解,提取出球面度数(SPH)、柱面度数(CYL)、散光轴位(AXIS)和近视加力(ADD),并将缺失参数填充为“N/A”,最后转换为结构化的JSON格式数据,以便后续应用。此方案既可处理非结构化文本,又可实现参数提取和结构化,可有效提升处方信息的采集效率。

总结
本文介绍了一套完整的解决方案,旨在有效解决文字质量低、手写体识别、文档类型多样性以及上下文理解等问题。利用Amazon API Gateway+Lambda+S3+Textract+ Bedrock构建了一个无服务器应用,无需进行运维管理。在无固定模板的样例中,相比传统的OCR正则匹配方法可以极大地提升准确率。优势在于它的灵活性和可扩展性,开发者无需依赖固定的模板,可以适应各种文档类型和样式。而且根据需要轻松地调整和改进模型,以进一步提高准确率和性能。