情感分析技术在美团的探索与应用
2021年5月,美团NLP中心开源了迄今规模最大的基于真实场景的中文属性级情感分析数据集ASAP,该数据集相关论文被自然语言处理顶会NAACL2021录用,同时该数据集加入中文开源数据计划千言,将与其他开源数据集一起推动中文信息处理技术的进步。
本文回顾了美团情感分析技术的演进和在典型业务场景中的应用,包括篇章/句子级情感分析、属性级情感分析和观点三元组分析。在业务应用上,依托情感分析技术能力构建了在线实时预测服务和离线批量预测服务。截至目前,情感分析服务已经为美团内部十多个业务场景提供了服务。
背景
移动互联网的发展和普及已达到空前规模,亿万用户在互联网上可以获得信息、交流信息,发表自己的观点和分享自己的体验,表达各种情感和情绪,如批评、赞扬以及喜、怒、哀、乐等。作为国内领先的生活服务电子商务平台,美团连接起了百万商户和数亿用户,积累了数十亿真实用户评论。用户评论不仅为消费者选店决策提供了参考,也是商家获取消费者反馈的重要渠道。对用户评论进行情感分析可以帮助美团深入理解商家服务水平和用户偏好,为改进平台服务与获取优质内容提供了最直观的反馈,同时也在美团搜索、个性化推荐、商业智能、内容安全等十多个业务场景中有着广泛的应用。
以大众点评App为例,用户既可以发表对商家的星级打分(一星到五星),也可以对商家服务或产品发表详细评论。我们对大众点评商户近半年的评论进行了统计分析,用户情感倾向在不同星级商家中的分布如图1所示,商家整体星级打分反映出用户对该商家的整体情感倾向,但同时我们发现高星商户的评论中存在大量负向的情感内容,低星商户的评论中也存在不少正向情感内容。原因在于用户评论中存在大量星级评分与对应评论情感倾向不一致的情况,如图2中展示的两条用户评论,高星级评论中存在负向情感的内容,低星级评论中也存在正向情感的内容。
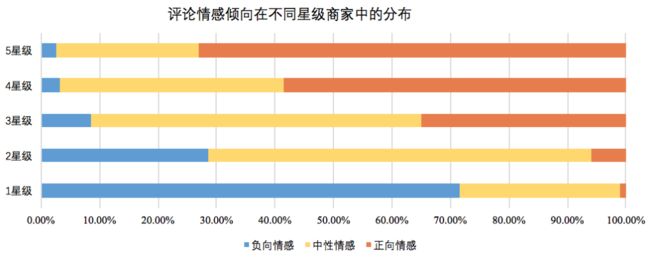
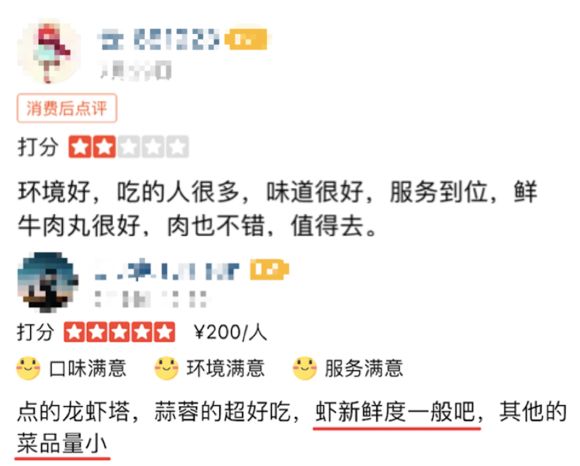
图3展示了大众点评App上一家「五星级」咖啡厅,用户对口味、环境、服务各项评分都很高。我们对其所有用户评论分析后发现好评主要集中在口味、服务、性价比等属性,但也有不少用户抱怨说咖啡厅的位置难找,不好停车,座位比较拥挤,空间小等。整体星级评分并不能全面体现用户对商家的真实评价。因此,除了对用户评论内容进行整体情感判断外,我们还需要对用户评论进行更细粒度的情感分析,这样才能精准地挖掘用户对商家的反馈,进而改善商家服务,提升用户体验。

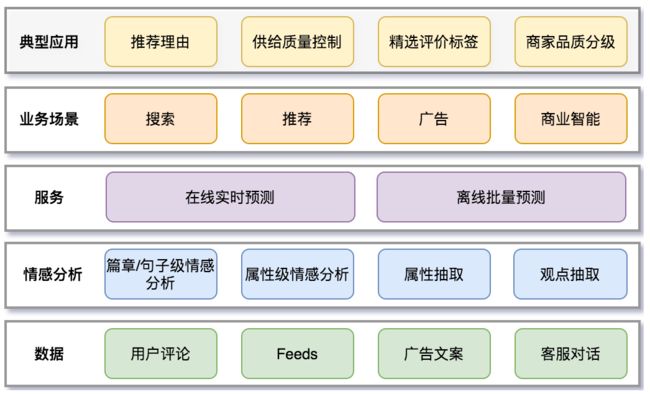
2021年5月,美团NLP中心开源了迄今规模最大的基于真实场景的中文属性级情感分析数据集ASAP[1],该数据集相关论文[2]被自然语言处理顶会NAACL2021录用,同时该数据集加入中文开源数据计划千言[3],将与其他开源数据集一起推动中文信息处理技术的进步。借此机会,本文回顾了美团情感分析技术的演进和在典型业务场景中的应用,整体技术框架如下图4所示:
情感分析介绍
情感分析的目标是分析文本中表达或蕴含的正向(褒义)、负向(贬义)或中立的情感倾向。根据所处理文本的粒度,情感分析可以分为篇章/句子级情感分析和属性级情感分析[4],与属性级情感分析密切相关的还有观点三元组分析。
篇章/句子级情感分析的目标是判断整篇文档或整句子的情感倾向(即正向、负向或中立)。
属性级情感分析与篇章/句子级情感分析不同,需要同时考虑目标信息(属性)及其对应的情感。例如“这家餐厅装修很有格调,饭菜也很好吃,就是位置很不显眼,找了好久才找到,并且服务员态度也不够满意。”如果从整体看,很难说这句话应该被判断成褒义还是贬义,因为在评论中,用户称赞了餐厅的装修和菜品属性,但是吐槽了餐厅的位置和服务属性。为了得到更全面和精确的情感信息,我们需要识别粒度更细的属性级情感。这种任务学术上被称为ABSA(Aspect Based Sentiment Analysis,基于属性的情感分析),可以划分为ACSA(Aspect Category Sentiment Analysis,基于属性类别的情感分析)和ATSA(Aspect Term Sentiment Analysis,基于属性项的情感分析)[5],其中ACSA是识别在相应预定义属性类别(Aspect Category)上的情感倾向,如上述评论在属性类别“菜品口味”上表达正向情感,在属性类别“服务态度”上表达负向情感。ATSA中是识别针对文本中出现的相应属性(Aspect Term)的情感倾向,如上述评论中针对属性“饭菜”表达正向情感,针对属性“服务员”表达负向情感。本文所述属性级情感分析主要指ACSA任务。
观点三元组分析包括属性抽取(Aspect Extraction)、观点抽取(Opinion Extraction)以及属性-观点对(Aspect-Opinion)的情感倾向分析三个任务,在学术上称为Aspect Sentiment Triplet Extraction[6]或者Opinion Triplet Extraction[7]。属性抽取和观点抽取属于信息抽取的范畴,属性-观点对的情感倾向分析属于分类任务。属性抽取任务中抽取的属性(Aspect Term),是上述ATSA任务的基础,观点抽取任务是抽取人们针对属性所表达的观点,例如评论“宫保鸡丁这道菜真是棒极了,太好吃了!”中的属性“宫保鸡丁”,观点“真是棒极了,太好吃了!”属性-观点对的情感倾向分析是识别基于该属性表达观点的情感倾向,例如 “宫保鸡丁——真是棒极了,太好吃了!”情感倾向为正向。
篇章/句子级情感分析及应用
篇章/句子级情感分析即给定一段文本,通过模型给出该文本整体的情感强度或情感倾向。根据模型输出类型划分,主要分为回归方案和分类方案,其中回归方案的输出为连续的情感强度[0~1](趋向0代表负向程度,趋向1代表正向程度),分类方案的输出为离散的情感倾向(正向、负向、中立)三分类。调研多个业务场景对情感分析的需求,同时考虑模型在应用中的通用性和灵活性,我们最终采用了回归模型方案。为了建立精准的情感分析能力,在数据标注时我们将情感强度划分为离散的七档评分——[非常负向, 负向, 轻微负向, 中性, 轻微正向, 正向, 强烈正向] ,并采用Min-Max Normalization将标注Label归一化到[0~1]。
在这个任务上,业界主流技术方案主要有TextCNN[8]、Att-BLSTM[9]以及BERT[10]为代表的预训练模型。其中Att-BLSTM提出利用注意力机制获取句子中最重要的信息,且在学习长距离语义上优于TextCNN,因此第一版模型框架采用了图5所示的Att-BLSTM方案。2018年以来,以BERT(可参阅《美团BERT的探索和实践一文)为代表的预训练模型在多项NLP任务中取得巨大进展,BERT在特征抽取上具有较强优势,如浅层的句法特征以及深层的语义特征。基于上述考虑,我们用自研MT-BERT[11]模型对Att-BLSTM架构中的编码器进行升级,并在多个业务评测上取得了显著效果提升,部分实验结果见下图6。

图5 篇章/句子级情感分析模型架构

篇章/句子级情感分析在美团业务中有着广泛应用,如广告和推荐业务中的文本安全管控和商家运营情感监测等。如图7(a)所示,美团App和大众点评App首页信息流文案大部分抽取自用户真实评论,需要从内容供给上严格控制文本质量,通过句子级情感分析对供给内容中的负向内容进行过滤,提升终端用户体验。此外,在商业智能场景中,句子级情感分析还可以帮助商家优化运营策略,如图7(b)所示,美团商业大脑通过情感分析能力,可以监控用户对商家评价的情感曲线以及评论情感占比等指标,从而来改善商家的运营。

属性级情感分析及应用
篇章/句子级情感分析只是针对文本整体表达或蕴含的情感倾向分析,无法获取针对评价观点对象(属性)上的情感倾向。为了得到更细粒度的情感分析结果,我们需要针对美团业务场景构建属性级情感分析能力,即给定一段文本,通过模型给出该文本在指定属性上的情感倾向。
数据收集与分析:针对大量用户评论进行统计分析,同时参考SemEval数据集[12],并与业务产品专家沟通美团业务特点后,我们将餐饮业务下的属性设计为菜品、环境、价格、服务、位置,共5类。数据分析中发现美团业务下的用户评论趋于多样化和细粒度化。以该真实用户评论“...装修看起来很高大上的样子,但是因为主厅在举办婚礼非常混乱,感觉特别吵...”为例,用户对装修和噪声两个环境细分属性表现出相反情感倾向。因此我们将属性从上述5个类别细分到18个子类别,最终设计为两级属性体系,如下图8所示:

为了构建高质量数据集,我们进行了详细数据分析和调研业界标准,最终制定了面向用户评论的属性级情感分析标注规则。对于每条评论,标注人员需要先判断预定义的属性是否在该评论中被提及,再判断被提及属性上的情感倾向。因此。对于每个属性共有4种标签——[未提及, 负向, 中立, 正向]。
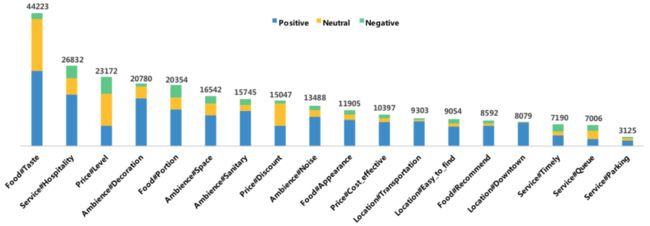
我们对ASAP数据集中属性及其对应的情感倾向分布做了统计,如下图9所示。本次标注主要面向餐饮商家下的用户评论,所以94.7%的评论都提及菜品口味这一属性。除此之外,用户们还比较关心服务人员态度、价格水平、装修情况等属性。
与属性级情感分析开源数据集SemEval RESTAURANT[13]相比,ASAP在数据量上远远超出,可以支撑深度神经网络模型的探索。相对于单句级别的RESTAURANT,包含多子句评论级别的ASAP具有更长的平均长度,因此往往包含更丰富的属性信息。在ASAP数据集中平均每条评论包含5.8个属性,是RESTAURANT数据集的4.7倍,相对于RESTAURANT数据集具有更大的挑战性。
属性级情感分析多任务学习框架:在该类问题上,业界主流技术方案根据模型结构不同可以分为两种,分别为基于非预训练模型的方案和基于预训练模型的方案。基于非预训练模型的方案中,Att-BLSTM[9]需要为每个属性单独训练一个模型,无论模型训练还是模型应用都比较复杂;ATAE-LSTM[14]通过属性向量(Aspect Embedding)引入属性信息,同时提出基于注意力(Attention)机制让模型聚焦到对应的属性相关信息上来提升模型准确率;CapsNet[15]可以用于ABSA任务中学习属性(Aspect)和文本(评论)之间关系。基于预训练模型的方案中,QA-BERT[16]将ABSA任务转化为问答形式的句间分类任务,每个属性都和文本构成句对作为输入,实际应用中属性数量较多时,计算量较大;CapsNet-BERT[17]在CapsNet方案的基础上将语义编码层(Encoder)从Bi-GRU升级为BERT。上述模型都只考虑了属性与文本的关系,把每个属性都单独处理,没有考虑不同属性间的关系。
通过数据分析部分可知,ASAP数据集在不同属性上的分布非常不均衡,这会导致模型训练时数据量小的属性上更容易出现过拟合,不同属性上的情感倾向表达有共性同时也有各自特定的表达方式。模型设计时需要结合业务数据特点同时兼顾计算效率,最终我们采用了多任务学习框架来兼顾属性间关系,同时处理一条评论的多个属性,模型整体设计为两层,分别为共享层和任务相关层,如下表所示:

共享层为语义编码层(Encoder),目标是学习文本在不同属性上的上下文深度语义表征。通过参数共享实现知识的迁移可缓解数据不均衡带来的问题,同时对新增属性的扩展具有较好的兼容性。

其中,为评论经过语义编码层(Encoder)编码后得到的向量,Ζ代表评论的长度。
任务相关层包括注意力层和分类层,注意力层设计上我们借鉴了ATAE-LSTM中注意力池化的方法,让模型可以聚焦到整条评论中和指定属性最相关的句子或者片段,减少其他属性等无关信息的干扰,提升该属性上的情感倾向判断准确率。

其中,αi是注意力权重向量,对句子中不同重要程度的词语给予不同的权重。ri是评论针对第i个属性经过注意力池化后得到的加权表征。
最后模型经过Softmax分类器,

对于给定的评论R属性级情感分析的损失如下:
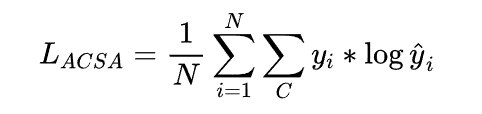
其中,N为属性(Aspect)数量,C是分类类别数。
随着预训练语言模型技术的快速发展,结合团队自研的预训练模型MT-BERT不断迭代,我们在上述多任务框架的基础上,对参数共享层的语义编码(Encoder)部分做了持续的迭代,由最初的Bi-GRU到Google-BERT-Base,再到MT-BERT-Base,以及目前的MT-BERT-Large,模型在Benchmark上的指标得到了进一步的提升,如下图11所示:

典型应用:属性级情感分析在美团业务中有非常多的应用场景,如精选点评、个性化推荐、智能搜索、商家运营等。大众点评App的精选点评模块是属性级情感分析的典型应用场景之一,如图12所示。精选点评模块作为点评App用户查看高质量评论的入口,其中精选点评标签承载着内容结构化聚合的作用,支撑着用户高效查找目标评论内容的需求。鉴于属性级情感分析能够挖掘用户评论在不同属性上表达的情感倾向,根据其构建的属性级情感标签能够较好的帮助用户筛选查看,同时外露更多的商家信息,帮助用户高效的从评论中获取消费指南。

美团商业大脑运营分析是属性级情感分析在美团商业智能典型应用场景,如下图13所示。美团商业大脑是美团搭建起的面对生活服务业商家提供大数据分析决策支持的知识图谱平台,通过细致刻画商家服务现状、商家竞争力分析,以及商圈洞察等方式,为商户提供精细化经营建议。美团商业大脑通过对用户评论进行全方属性级情感分析与归纳总结,从而可以发现商家在市场上的竞争优势/劣势、用户对于商家的总体印象趋势、商家菜品的受欢迎程度变化,并对商家提供前瞻性经营方向,智能化指导商家精准优化经营模式。

观点三元组分析及应用
在观点三元组抽取任务中,工业界目前主流的方案是基于Pipeline的方案,即先分别抽取属性和观点,然后抽取两者关系,最后通过句子级情感分析获得属性和观点对的情感倾向。Pipeline方案的优点是整个任务可以模块化,复用关系抽取、情感分析等通用能力,且各模块可以单独迭代优化;缺点是误差会在Pipeline模块中传导累积,后序模块对前序模块的准确度有较强的依赖性,且计算效率低。
在学术界,最新的一些工作MTL[7]和GTS[18]等提出了多任务学习的解决方案。结合美团业务特点同时兼顾计算效率的考虑,最终我们选择了多任务学习的方案,模型架构如图14所示。模型整体由四部分组成:Pretrained Language Model、Aspect Tagger、Opinion Tagger、Sentiment Parser,其中Pretrained Language Model为基于预训练语言模型的编码器,兼容BERT、RoBERTa[19]、ELECTRA[20]等主流预训练模型,Aspect Tagger执行属性序列标注任务,Opinion Tagger执行观点描述序列标注任务,Sentiment Parser执行属性与观点描述关系依赖及其情感分析解析任务,主要为一个Biaffine Scorer[21]。
如图14中的例子所示,Aspect Tagger将“虾滑”和“墨鱼滑”这两个属性抽取出来,而Opinion Tagger则对应地将“很不错”和“并不新鲜”这两个观点描述抽取出来,Sentiment Parser给出句子中的所有字之间的情感依赖关系(即正向、负向、中立、无关)四分类。我们利用抽取出来的属性和观点描述在所有字之间的情感依赖关系上进行索引和记录,最终可以得到“虾滑”和“很不错”之间的2*3=6个情感依赖关系中最多的关系为正向情感,而“虾滑”和“并不新鲜”之间的2*4=8个情感依赖关系中最多的关系为无关。类似地,我们可以推断出“墨鱼滑”和”并不新鲜“之间的关系为负向情感。模型训练时,模型整体对三个子任务损失进行联合优化。

此外,我们对Pretrained Language Model模块进行了优化,由最初的Google BERT-Base,到自研MT-BERT-Base,再到目前的MT-BERT-Large,模型在Benchmark上的指标得到了进一步的提升,如下图15所示。由于观点三元组分析既包括分类任务也包括抽取任务,评价指标上我们采用了EM-F1和Fuzzy-F1,其中EM-F1需要任意两个观点三元组(属性,观点描述,情感)中三个元素全部正确整体才算一次命中,Fuzzy-F1会考虑抽取片段的重合度(包括属性和观点描述),EM-F1比Fuzzy-F1更加严格。

通过观点三元组分析技术可以构建基于属性的情感观点知识库,其中每个属性(商品或服务)节点都会被一个或多个带情感依赖的观点描述指向,如下图16所示。通过【属性+正向观点】的模板方法可以构造推荐文案,例如"酸汤鱼片:酸酸甜甜,妙不可言",可以用于美团App和大众点评App首页推荐或广告文案场景,同时可以根据用户对属性(商品或服务)的偏好,展示个性化推荐文案,帮助用户更加高效的获取信息。同时这些基于属性(商品或服务)的情感观点信息可以帮助商家更加精细化的运营。
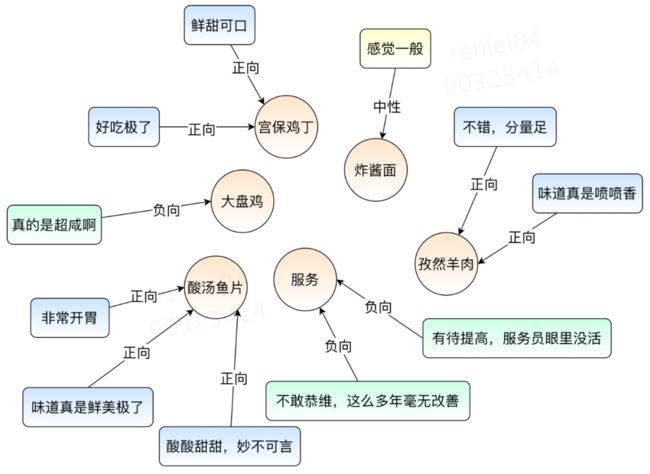
图16 基于属性(商品或服务)的情感观点知识库样例展示
情感分析服务化
很多美团业务场景对情感分析有迫切需求,例如推荐理由、Feeds内容、广告文案、精选评价标签、商家运营、对话系统等场景都需要识别文本在整体或属性上的情感倾向。针对美团业务特点我们构建了在线实时预测服务和离线批量预测服务。

图17 在线实时预测
在线实时预测服务主要针对需要实时计算的场景,如对话系统需要实时识别用户对话内容的情感倾向,提供Thrift接口调用方式,方便美团内部业务服务调用;离线批量预测服务主要针对需要离线批量计算的场景,如每日新生产的Feeds内容需要批量进行情感分析后才能进入线上内容供给池。我们依托于美团机器学习平台MLP搭建了情感分析离线计算服务,业务使用方仅需要简单的配置输入/输出数据表以及计算队列即可便捷调用,同时该服务支持了定时调度,可以便捷接入到业务方整体的调度流程中。目前,情感分析服务已经为美团内部十多个业务场景提供了服务。
总结与展望
本文总结了美团情感分析技术的演进和在典型业务场景中的应用,包括篇章/句子级情感分析、属性级情感分析和观点三元组分析,其中属性级情感分析工作向业界开源了迄今规模最大的基于真实场景的中文属性级情感分析数据集ASAP,该数据集相关论文《ASAP: A Chinese Review Dataset Towards Aspect Category Sentiment Analysis and Rating Prediction》被自然语言处理顶会NAACL2021录用。在技术迭代上,紧跟预训练语言模型技术的快速发展,结合团队自研的MT-BERT模型不断迭代升级。在业务应用上,依托情感分析技术能力构建了在线实时预测服务和离线批量预测服务,截至目前情感分析服务已经为美团内部十多个业务场景提供服务。
属性级情感分析已经在美团多个场景落地应用,但对于某些领域跨度较大的新场景(比如从餐饮领域到休闲娱乐领域),我们总是需要人工预定义新的属性,并进行一定数量的数据标注。预定义属性需要对每个业务都有深入的理解,在实际中,很难把每个业务的属性都预定义得非常全面,尤其是某些占比不高但具有业务特色的属性。这些成本会对属性级情感分析在新业务场景的快速落地有一定程度的影响。我们也在探索迁移学习、少样本学习、属性自动挖掘等技术在情感分析上的应用,以加速情感分析在新领域快速应用,来满足美团业务快速发展的需求。
参考文献
[1] https://github.com/Meituan-Dianping/asap.
[2] Bu J, Ren L, Zheng S, et al. ASAP: A Chinese Review Dataset Towards Aspect Category Sentiment Analysis and Rating Prediction. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021.
[3] https://www.luge.ai/
[4] Zhang, L. , S. Wang , and B. Liu . "Deep Learning for Sentiment Analysis : A Survey." Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery (2018):e1253.
[5] Liu, Bing. "Sentiment analysis and opinion mining." Synthesis lectures on human language technologies 5.1 (2012): 1-167.
[6] Peng, Haiyun, et al. "Knowing what, how and why: A near complete solution for aspect-based sentiment analysis." In Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 05. 2020.
[7] Zhang, Chen, et al. "A Multi-task Learning Framework for Opinion Triplet Extraction." In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings. 2020.
[8] Yoon Kim. 2014. Convolutional neural networks for sentence classification. arXiv preprint arXiv:1408.5882.
[9] Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li,Hongwei Hao, and Bo Xu. 2016. Attention-based bidirectional long short-term memory networks for relation classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pages 207–212.
[10] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[11] 杨扬、佳昊等. 美团BERT的探索和实践.
[12] Pontiki, Maria, et al. "Semeval-2016 task 5: Aspect based sentiment analysis." International workshop on semantic evaluation. 2016.
[13] Pontiki, M. , et al. "SemEval-2014 Task 4: Aspect Based Sentiment Analysis." In Proceedings of International Workshop on Semantic Evaluation at (2014).
[14] Yequan Wang, Minlie Huang, and Li Zhao. 2016. Attention-based lstm for aspect-level sentiment classification. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 606–615.
[15] Sara Sabour, Nicholas Frosst, and Geoffrey E Hinton. 2017. Dynamic routing between capsules. In Advances in neural information processing systems, pages 3856–3866.
[16] Chi Sun, Luyao Huang, and Xipeng Qiu. 2019. Utilizing bert for aspect-based sentiment analysis via constructing auxiliary sentence. arXiv preprint arXiv:1903.09588.
[17] Qingnan Jiang, Lei Chen, Ruifeng Xu, Xiang Ao, and Min Yang. 2019. A challenge dataset and effective models for aspect-based sentiment analysis. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 6281–6286.
[18] Wu, Zhen, et al. "Grid Tagging Scheme for End-to-End Fine-grained Opinion Extraction." In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings. 2020.
[19] Liu, Yinhan, et al. "Roberta: A robustly optimized bert pretraining approach." arXiv preprint arXiv:1907.11692 (2019).
[20] Clark, Kevin, et al. "Electra: Pre-training text encoders as discriminators rather than generators." arXiv preprint arXiv:2003.10555 (2020).
[21] Timothy Dozat and Christopher D. Manning. 2017.Deep biaffine attention for neural dependency parsing. In 5th International Conference on Learning Representations, ICLR 2017.
作者介绍
任磊、佳昊、张辰、杨扬、梦雪、马放、金刚、武威等,均来自美团平台搜索与NLP部NLP中心。
招聘信息
美团搜索与NLP部/NLP中心是负责美团人工智能技术研发的核心团队,使命是打造世界一流的自然语言处理核心技术和服务能力。NLP中心长期招聘自然语言处理算法专家/机器学习算法专家,感兴趣的同学可以将简历发送至[email protected],具体要求如下。
岗位职责
-
预训练语言模型前瞻探索,包括但不限于知识驱动预训练、任务型预训练、多模态模型预训练以及跨语言预训练等方向;
-
负责百亿参数以上超大模型的训练与性能优化;
-
模型精调前瞻技术探索,包括但不限于Prompt Tuning、Adapter Tuning以及各种Parameter-efficient的迁移学习等方向;
-
模型inference/training压缩技术前瞻探索,包括但不限于量化、剪枝、张量分析、KD以及NAS等;
-
完成预训练模型在搜索、推荐、广告等业务场景中的应用并实现业务目标;
-
参与美团内部NLP平台建设和推广
岗位要求
-
2年以上相关工作经验,参与过搜索、推荐、广告至少其一领域的算法开发工作,关注行业及学界进展;
-
扎实的算法基础,熟悉自然语言处理、知识图谱和机器学习技术,对技术开发及应用有热情;
-
熟悉Python/Java等编程语言,有一定的工程能力;
-
熟悉Tensorflow、PyTorch等深度学习框架并有实际项目经验;
-
熟悉RNN/CNN/Transformer/BERT/GPT等NLP模型并有过实际项目经验;
-
目标感强,善于分析和发现问题,拆解简化,能够从日常工作中发现新的空间;
-
条理性强且有推动力,能够梳理繁杂的工作并建立有效机制,推动上下游配合完成目标。
加分项
-
熟悉模型训练各Optimizer基本原理,了解分布式训练基本方法与框架;
-
对于最新训练加速方法有所了解,例如混合精度训练、低比特训练、分布式梯度压缩等
---------- END ----------
美团科研合作
美团科研合作致力于搭建美团各部门与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕人工智能、大数据、物联网、无人驾驶、运筹优化、数字经济、公共事务等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:[email protected] 。
也许你还想看
| 美团BERT的探索和实践
| Transformer 在美团搜索排序中的实践
| 常识性概念图谱建设以及在美团场景中的应用
阅读更多
---
前端 | 算法 | 后端 | 数据
安全 | Android | iOS | 运维 | 测试