MySql之索引,视图,事务以及存储过程举例详解
一.数据准备
数据准备可参考下面的链接中的数据准备步骤
MySql之内连接,外连接,左连接,右连接以及子查询举例详解-CSDN博客
(如有问题可在评论区留言)
二.存储过程
1.定义
2.语法
create procedure 存储过程名称(参数列表)
begin
sql 语句
end3.举例
--创建存储过程 stu(),查询 students 表所有学生信息
CREATE PROCEDURE stu()
BEGIN
SELECT * from students;
end调用存储过程
--调用存储过程stu
call stu();执行结果:

删除存储过程
--删除存储过程,删除的时候不用写名字后面的()
--方法一
DROP PROCEDURE stu;
--方法二(方法二,加了if EXISTS,与方法一的区别就是,如果stu已经被删除,再执行方法一,会报错,但是执行方法二不会报错)
drop PROCEDURE if EXISTS stu;三.视图
1.定义
视图本质就是对select(查询)语句的封装
视图可以理解为一张只读的表,针对视图只能用select,不能用delete和update
2.语法
--创建视图
create view 视图名称 as select 语句;
--使用视图
select * from 视图名称;
--删除视图
方法一
drop view 视图名称;
方法二
drop view if exists 视图名称;
3.举例
创建视图
stu_nan可看成是一个新的表
--创建一个视图,查询所有男生信息
CREATE VIEW stu_nan as
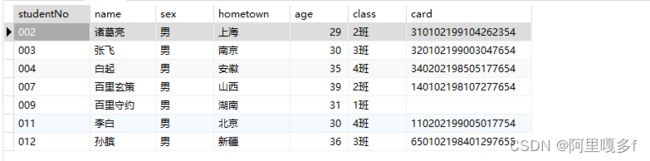
SELECT * from students where sex = '男';使用视图
--使用视图,例1
SELECT * from stu_nan
--使用视图,例2
--在视图 stu_nan 中查找年龄大于25岁的学生信息
select * from stu_nan where age >25;
--使用视图,例3
SELECT * from stu_nan INNER JOIN scores
on stu_nan.studentNo = scores.studentNo;例1运行结果(其他的例子感兴趣可自行验证):
删除视图
--删除视图
--方法一
drop VIEW stu_nan;
--方法二
DROP view if EXISTS stu_nan;4.什么时候用视图
如果某个查询结果出现的非常频繁,也就是,要经常拿这个查询结果来做子查询这种
四.事务
1.为什么要有事务
2.什么是事务
3.事务指令
-
事务是多条更改数据操作的sql语句集合
-
一个集合数据有一致性,要么就都失败,要么就都成功回滚
-
begin ----开始事务,开启事务后执行修改update或者删除delete记录语句,变更会写到缓存中,而不会立刻生效
-
rollback ----回滚事务,放弃对表的修改
-
commit ---- 提交事务,对表的修改生效
没有写begin代表没有事务,没有事务的表操作都是实时生效.
如果只写了begin, 没有rollback,也没有commit, 结果是rollback或者系统退出,结果也是rollback
回滚事务
(第二步执行的完成后,可以用查询语句查询stuents表是否真的删除001的记录--应该是被删除了
第三步执行的完成后,可以用查询语句查询scores表是否真的删除001的记录--应该是被删除了
第四步执行完成后,可以分别查询两个表的内容,001的记录都还存在)
-- 例 1:
-- 第一步执行:开始事务(begin;)
-- 第二步执行:删除 students 表中 studentNo 为 001 的记录,
-- 第三步执行:同时删除 scores 表中 studentNo 为 001 的记录,
-- 第四步执行:回滚事务,两个表的删除同时放弃
begin;
DELETE from students where studentNo = '001';
DELETE from scores where studentNo = '001';
-- 回滚事务,放弃更改
ROLLBACK;注意:如果在第二步执行或者第三步执行完成后,直接把navicat关掉,那么重新进入navicat时,查询students表和scores表的内容时,001记录是存在的(验证了这句话:系统退出或系统有问题了,结果也是rollback)
提交事务
-- 开启事务,
-- 删除 students 表中 studentNo 为 001 的记录,
-- 同时删除 scores 表中 studentNo 为 001 的记录,
-- 提交事务,使两个表的删除同时生效
begin;
DELETE from students where studentNo = '001';
DELETE from scores where studentNo = '001';
--提交事务,一旦提交事务,两个删除操作同时生效
commit;五.索引
1.引入索引
2.创建索引的目的
-
给表建立索引,目的是加快select查询的速度
-
如果一个表记录很少,几十条,或者几百条,不用索引
-
表的记录特别多,如果没有索引,select语句效率会非常低
3.语法
创建索引
-
create index 索引名称 on 表名(字段名称(长度));
-
如果字段为字符串,需要写明创建表字段的时候字符串的长度
-
字段类型如果不是字符串,可以不填写长度部分。
调用索引
-
不需要写调用索引的语句,只要where条件后面用到的字段建立了索引,那么系统会自动调用
查看索引
-
show index from 表名
-
对于主键,系统会自动建立索引
删除索引
-
drop index 索引名 on 表名
4.举例
-- 例1:为表 students 的 age 字段创建索引,名为 age_index
CREATE index age_index on students (age);
-- 例2:为表 students 的 name 字段创建索引,名为 name_index
CREATE INDEX name_index on students (name(10));
-- 查看students表的索引
show index from students;结果(主键会自己自动生成索引):
 调用索引
调用索引
--调用索引
-- where条件后面的字段,数据库系统会自动查找是否有索引
-- 这里会自动调用age_index
select * from students where age = 30;
-- 自动调用name_index
SELECT * from students where name = '李白';
-- 不会调用任何索引,因为sex字段没有索引
SELECT * from students where sex = '女';删除索引
-- 删除索引age_index
drop index age_index on students;
-- 删除索引name_index
drop index name_index on students;5.索引的优缺点
-
提高select的查询速度
-
降低update,delete和insert语句的执行速度
-
项目中80%以上是select,所以index必须的
-
在实际工作中如果涉及到大量的数据修改操作,修改之前可以把索引删除,修改完成后再把索引建立起来