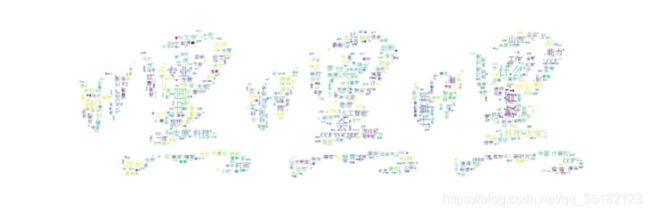Airtest爬朋友圈并生成中文词云图
- 使用Airtest来爬取朋友圈的内容。参考链接,参考链接中的手机滑动的功能在我的实际操作过程不可使用,故对其进行改动。
该部分整体代码如下:
# -*- encoding=utf8 -*-
__author__ = " "
from airtest.core.api import *
from poco.drivers.android.uiautomation import AndroidUiautomationPoco
poco = AndroidUiautomationPoco(use_airtest_input=True, screenshot_each_action=False)
start_app('com.tencent.mm') # 启动微信
poco(text="通讯录").click()
# 找到对应的人 并进行点击
while True:
if poco(text="要爬取的备注名"):
poco(text="要爬取的备注名").click()
break
else:
# 滑动一个屏幕
screenWidth,screenHeigth = poco.get_screen_size()
swipe((screenWidth*0.5,screenHeigth*0.9),vector=[0,-0.8],duration=2.5)
sleep(1) # 暂停 1秒
# 点击朋友圈
poco(text="朋友圈").click()
# 一个列表用于存放所爬取的内容
a=list()
# 获取100个屏幕的内容
for k in range(100):
# 到朋友圈的界面
result_obj = poco("com.tencent.mm:id/ezu")
# 假设一个屏幕可出现15条动态
for i in range(15):
try:
# 获取界面的每一个动态的文本 并追加到列表中
# 获取链接的评论文本
content1 =result_obj.offspring("com.tencent.mm:id/mk")[i].get_text()
# print(content1)
a.append(content1)
# 获取链接的标题
content2 =result_obj.offspring("com.tencent.mm:id/dbo")[i].get_text()
# print(content2)
a.append(content2)
# 获取图片的文字
content3 =result_obj.offspring("com.tencent.mm:id/pi")[i].get_text()
# print(content3)
a.append(content3)
except:
pass
# 完成一个屏幕的内容获取 进行滑动
screenWidth,screenHeigth = poco.get_screen_size()
swipe((screenWidth*0.5,screenHeigth*0.9),vector=[0,-0.8],duration=2.5)
sleep(3) # 暂停 2.5 秒
# 输出获取的内容至控制台
print(a)
auto_setup(__file__)
- 因为没有找到直接可以将 Airtest 获取的内容存到文本(有知道的可以交流一下),所以进行复制-粘贴。将获取的内容存到记事本中,并作为生成词云的原始数据。
- 爬取到的内容形式为
['第一条内容','第二条内容',' ' ,'', '。。。']。首先去掉数据中的表情(/uxxxx和/Uxxxxxxx这种形式),去掉斜杠及回车符,提取不一样的内容,因为每条数据是存放在单引号内,所以进行单引号内内容的提取。python代码如下:
#coding=utf-8
import re
import pandas as pd
#提取单引号内的内容
def prepro(data):
data_str = str(data)
# 去掉\u
data_rem_u = re.sub(r"\\(u[0-9a-fA-F]*)","",data_str)
data_rem_U = re.sub(r"\\(U[0-9a-fA-F]*)","",data_rem_u)
# 去掉\和回车
data_rem_res = data_rem_U.replace(r"\n","").replace("\\","").replace("...","")
# 提取单引号中的内容 并转为list
data_clean = re.findall(r"'([\S\s]+?)'",data_rem_res)
return data_clean
#根据列名获取该列的类别 输出不一样的内容
def getCategory(data,columns):
data_group = data.groupby(by = columns)
product_list = list(data_group.groups.keys())
return product_list
#打开原始数据
with open("moment-orginal-data.txt", "r", encoding = 'utf-8') as f: #打开文件
data = f.readlines() #读取文件
# 去除空格回车等内容
data_pro = prepro(data)
# 将列表转换为数据帧 并添加列名
data_clean = pd.DataFrame(data_pro,columns=['one'])
# 去除重复特征
data_clean_list = getCategory(data_clean,'one')
# 转为可存储结构
data_res = pd.DataFrame(data_clean_list,columns=['desc'])
file = open('moment-clean-data.txt','w');
file.write(str(data_clean_list));
file.close()
- 使用现行的分词工具对处理完的文本(moment-clean-data.txt)进行分词和去除停用词的简单操作,并生成词云图。分词可以使用jieba,nlp,pkuseg等。代码如下:
import jieba
import pkuseg
import pandas as pd
from pyhanlp import * # 不显示词性
with open("moment-clean-data.txt", "r") as f: #打开文件
data = f.readlines() #读取文件
HanLP.Config.ShowTermNature = False # 可传入自定义字典 [dir1, dir2]
segment = DoubleArrayTrieSegment() # 激活数字和英文识别
segment.enablePartOfSpeechTagging(True)
cut_pyhanlp = segment.seg(str(data))
def load_from_file(path):
""" 从词典文件加载DoubleArrayTrie :param path: 词典路径 :return: 双数组trie树 """
map = JClass('java.util.TreeMap')() # 创建TreeMap实例
with open(path,'rb') as src:
for word in src:
word = word.strip() # 去掉Python读入的\n
map[word] = word
return JClass('com.hankcs.hanlp.collection.trie.DoubleArrayTrie')(map) ## 去掉停用词
def remove_stopwords_termlist(termlist, trie):
return [term.word for term in termlist if not trie.containsKey(term.word)]
# 提用词denywords.txt请上网自行搜索或https://github.com/NLP-LOVE/Introduction-NLP/blob/master/data/dictionnary/stopwords.txt
trie = load_from_file('denywords.txt')
termlist = segment.seg(str(data))
# print('去掉停用词前:', termlist)
res = remove_stopwords_termlist(termlist,trie)
print(res)
- 利用wordcloud生成词云图,代码如下:
from wordcloud import WordCloud
import jieba
from scipy.misc import imread
from os import path
import matplotlib.pyplot as plt
# 绘制词云 穿入分词结果
def draw_wordcloud(cut_text):
color_mask = imread("h.jpg") # 读取背景图片
cloud = WordCloud(
# 设置字体,不指定就会出现乱码
font_path="STSONG.TTF",
# 设置背景色
background_color='white',
# 词云形状
mask=color_mask,
#允许最大词汇
max_words=5000,
#最大号字体 为60
max_font_size=60
)
# print(cut_text)
word_cloud = cloud.generate(cut_text) # 产生词云
word_cloud.to_file("h-2.jpg") # 保存图片
# 显示词云图片
plt.imshow(word_cloud)
plt.axis('off')
plt.show()
draw_wordcloud(str(res))
ps:背景图是读取白底中的黑色部分,如:
该背景图下的词云图为: