PaddleDetection训练流程详解
快速上手:
PaddleDetection/GETTING_STARTED_cn.md at release/2.2 · PaddlePaddle/PaddleDetection · GitHub
源码(同时获取更新的一些预训练模型):
https://github.com/PaddlePaddle/PaddleDetection
paddle detection详细使用教程:
https://paddledetection.readthedocs.io/tutorials/
配置文件中部分参数介绍(优化调参必看):
PaddleDetection/DetectionPipeline.md at release/2.0-rc · PaddlePaddle/PaddleDetection · GitHub
配置和训练
1.文件结构

2.参数列表
以下列表可以通过--help查看
FLAG |
支持脚本 |
用途 |
默认值 |
备注 |
-c |
ALL |
指定配置文件 |
None |
必选,例如-c configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.yml |
-o |
ALL |
设置或更改配置文件里的参数内容 |
None |
相较于-c设置的配置文件有更高优先级,例如:-o use_gpu=False |
--eval |
train |
是否边训练边测试 |
False |
如需指定,直接--eval即可 |
-r/--resume_checkpoint |
train |
恢复训练加载的权重路径 |
None |
例如:-r output/faster_rcnn_r50_1x_coco/10000 |
--slim_config |
ALL |
模型压缩策略配置文件 |
None |
例如--slim_config configs/slim/prune/yolov3_prune_l1_norm.yml |
--use_vdl |
train/infer |
是否使用VisualDL记录数据,进而在VisualDL面板中显示 |
False |
VisualDL需Python>=3.5 |
--vdl_log_dir |
train/infer |
指定 VisualDL 记录数据的存储路径 |
train:vdl_log_dir/scalar infer: vdl_log_dir/image |
VisualDL需Python>=3.5 |
--output_eval |
eval |
评估阶段保存json路径 |
None |
例如 --output_eval=eval_output, 默认为当前路径 |
--json_eval |
eval |
是否通过已存在的bbox.json或者mask.json进行评估 |
False |
如需指定,直接--json_eval即可, json文件路径在--output_eval中设置 |
--classwise |
eval |
是否评估单类AP和绘制单类PR曲线 |
False |
如需指定,直接--classwise即可 |
--output_dir |
infer/export_model |
预测后结果或导出模型保存路径 |
./output |
例如--output_dir=output |
--draw_threshold |
infer |
可视化时分数阈值 |
0.5 |
例如--draw_threshold=0.7 |
--infer_dir |
infer |
用于预测的图片文件夹路径 |
None |
--infer_img和--infer_dir必须至少设置一个 |
--infer_img |
infer |
用于预测的图片路径 |
None |
--infer_img和--infer_dir必须至少设置一个,infer_img具有更高优先级 |
--save_txt |
infer |
是否在文件夹下将图片的预测结果保存到文本文件中 |
False |
可选 |
3.模型训练
3.1模型性能



3.2配置文件
注:所有配置文件都是在configs文件下进行修改,主要用来调参
%cd ~/work/PaddleDetection/
将~/work/hw_configs.zip解压到 configs 文件夹下
%cd ~/work/PaddleDetection/
!unzip -o ~/work/hw_configs.zip -d configs/
! ls configs/hw_configs/主配置文件
以yolov3为例:
PaddleDetection-release-2.2/configs/yolov3/yolov3_mobilenet_v1_270e_voc.yml
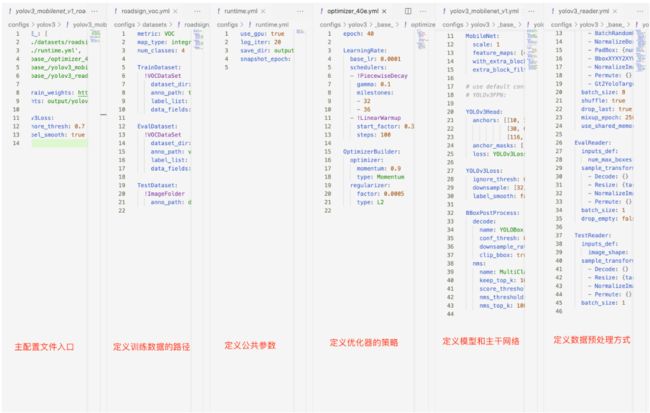
yolov3_mobilenet_v1_270e_voc.yml:主配置文件入口
voc.yml:定义训练数据和验证数据的路径
runtime.yml:定义公共参数,比如说是否使用GPU、每多少个epoch存储checkpoint等
optimizer_270e.yml:定义优化器的策略,说明了学习率和优化器的配置
yolov3_mobilenet_v1.yml:定义模型和主干网络
yolov3_reader.yml:定义数据预处理方式,数据读取器配置,如batch size,并发加载子进程数等,同时包含读取后预处理操作,如resize、数据增强等等
# 主要的配置文件,所有配置文件都是在configs文件下进行修改
_BASE_: [
'../datasets/voc.yml',
'../runtime.yml',
'_base_/optimizer_270e.yml',
'_base_/yolov3_mobilenet_v1.yml',
'_base_/yolov3_reader.yml',
]
snapshot_epoch: 5 #多少epoch保存一次模型
weights: output/yolov3_mobilenet_v1_270e_voc/model_final
# 将collate_batch设置为false,因为VOC数据集上需要真实信息,
# 并且当批量大小大于1时,不应批量整理数据。
EvalReader: # 评估阅读
collate_batch: false
# 自定义collate_fn,处理具有不同数量的关联对象注释(边界框)的批量图像
# collate_fn:如何取样本的,我们可以定义自己的函数来准确地实现想要的功能。
LearningRate:
base_lr: 0.001 #源码中给定的学习率,默认为8卡训学习率
schedulers: #学习率调整策略
- !PiecewiseDecay #分段衰减
gamma: 0.1 #伽马曲线矫正,输出图像对输入信号失真的度量参数
milestones: #学习率变化位置(轮数) milestones: [8, 11]
- 216
- 243
- !LinearWarmup #线性预热
start_factor: 0.
steps: 1000 #一次梯度更新的过程
# 可以看到LinearLR的策略就是设定起始的学习率(优化器中的学习率start_factor)
# 和终止的学习率(默认是优化器中的学习率end_factor,end_factor默认为1.0),
# 然后按照total_iters把起始学习率和终止学习率确定的区间进行均分,
# 然后每个epoch更新一次。
# 需要注意的是,当达到设定的终止学习率之后,即便还没训练完,学习率也不会再更新了。其他的配置文件
PaddleDetection-release-2.2/configs/yolov3/yolov3_mobilenet_v1_270e_voc.yml
voc.yml:数据集配置文件
metric: VOC # 数据类型
map_type: 11point
num_classes: 20 # 目标类别数,不包括背景
TrainDataset:
!VOCDataSet
dataset_dir: dataset/voc # 数据集路径
anno_path: trainval.txt # 训练数据集文件列表
label_list: label_list.txt # 类别名称列表
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
!VOCDataSet
dataset_dir: dataset/voc
anno_path: test.txt # 测试数据集文件列表
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
!ImageFolder
anno_path: dataset/voc/label_list.txtruntime.yml:运行配置文件
use_gpu: true # 是否使用gpu
use_xpu: false
log_iter: 20 # 日志打印间隔
save_dir: output
snapshot_epoch: 1 # 模型保存间隔轮数
print_flops: false
# Exporting the model(导出模型)
export:
post_process: True # 导出模型时是否将后处理(post_process)包含在网络(the network)中
nms: True # 导出模型时网络(the network)中是否包含 NMS
benchmark: False # 它用于测试模型性能,如果设置为“True”,则不会导出后处理和 NMS
fuse_conv_bn: Falseoptimizer_270e.yml:优化器配置文件(训练轮数、学习率与策略、优化器)
epoch: 270 # 总训练轮数
# 学习率设置
LearningRate:
base_lr: 0.001
schedulers: # 学习率调整策略
- !PiecewiseDecay
gamma: 0.1
milestones: # 学习率变化位置(轮数)
- 216
- 243
- !LinearWarmup
start_factor: 0.
steps: 4000
# 优化器
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer: # 正则化
factor: 0.0005
type: L2yolov3_mobilenet_v1.yml:定义模型结构和主干网络
# 模型结构类型
architecture: YOLOv3
# 预训练模型地址
pretrain_weights: https://paddledet.bj.bcebos.com/models/pretrained/MobileNetV1_pretrained.pdparams
norm_type: sync_bn
YOLOv3:
backbone: MobileNet # 骨干网络
neck: YOLOv3FPN
yolo_head: YOLOv3Head
post_process: BBoxPostProcess
MobileNet:
scale: 1
feature_maps: [4, 6, 13]
with_extra_blocks: false
extra_block_filters: []
# use default config
# YOLOv3FPN:
YOLOv3Head:
anchors: [[10, 13], [16, 30], [33, 23],
[30, 61], [62, 45], [59, 119],
[116, 90], [156, 198], [373, 326]]
anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
loss: YOLOv3Loss
YOLOv3Loss:
ignore_thresh: 0.7
downsample: [32, 16, 8]
label_smooth: false
BBoxPostProcess:
decode:
name: YOLOBox
conf_thresh: 0.005
downsample_ratio: 32
clip_bbox: true
nms:
name: MultiClassNMS
keep_top_k: 100
score_threshold: 0.01
nms_threshold: 0.45
nms_top_k: 1000yolov3_reader.yml:数据读取
注:batch_size根据显存设置
# 每张GPU reader进程个数
worker_num: 2
TrainReader: # 训练数据
inputs_def:
num_max_boxes: 50
sample_transforms:
- Decode: {}
- Mixup: {alpha: 1.5, beta: 1.5}
- RandomDistort: {}
- RandomExpand: {fill_value: [123.675, 116.28, 103.53]}
- RandomCrop: {}
- RandomFlip: {}
batch_transforms:
- BatchRandomResize: {target_size: [320, 352, 384, 416, 448, 480, 512, 544, 576, 608], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeBox: {}
- PadBox: {num_max_boxes: 50}
- BboxXYXY2XYWH: {}
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
- Gt2YoloTarget: {anchor_masks: [[6, 7, 8], [3, 4, 5], [0, 1, 2]], anchors: [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]], downsample_ratios: [32, 16, 8]}
batch_size: 8 # 训练时放入显卡多少张图
shuffle: true # 读取数据是否乱序
drop_last: true
mixup_epoch: 250
use_shared_memory: true
# 评估数据
EvalReader:
inputs_def:
num_max_boxes: 50
sample_transforms:
- Decode: {}
- Resize: {target_size: [608, 608], keep_ratio: False, interp: 2}
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
batch_size: 1 # 评估时放入显卡多少张图
# 测试数据
TestReader:
inputs_def:
image_shape: [3, 608, 608]
sample_transforms:
- Decode: {}
- Resize: {target_size: [608, 608], keep_ratio: False, interp: 2}
- NormalizeImage: {mean: [0.485, 0.456, 0.406], std: [0.229, 0.224, 0.225], is_scale: True}
- Permute: {}
batch_size: 1 # 测试时放入显卡多少张图选择配置开始训练。可以通过 -o 选项覆盖配置文件中的参数
最新的模型配置可以从paddledetection的模型库中下载,同时可在库中查看一些评测效果:
PaddleDetection: PaddleDetection的目的是为工业界和学术界提供丰富、易用的目标检测模型 (gitee.com) (建议使用该站,速度更快)
https://github.com/PaddleP addle/PaddleDetection#readme
例如yolov3:
python tools/train.py -c configs/yolov3/yolov3_darknet53_270e_voc.yml --use_vdl=True --eval
# faster_rcnn_r50_vd_fpn
python -u tools/train.py -c configs/hw_configs/faster_rcnn_r50_vd_fpn_roadsign_coco_template.yml -o use_gpu=True --eval
# yolov3
#python -u tools/train.py -c configs/hw_configs/yolov3_mobilenet_v1_roadsign_voc_template.yml -o use_gpu=True --eval
#python tools/train.py -c configs/yolov3/yolov3_darknet53_270e_voc.yml --use_vdl=True --eval
# fcos
#python -u tools/train.py -c configs/hw_configs/fcos_r50_roadsign_coco_template.yml -o use_gpu=True --evalvdl_log_dir 设置vdl日志文件保存路径: --use_vdl=True --vdl_log_dir=vdl_dir/scalar --eval
# faster_rcnn_r50_vd_fpn
python -u tools/train.py -c configs/hw_configs/faster_rcnn_r50_vd_fpn_roadsign_coco_template.yml -o use_gpu=True --use_vdl=True --vdl_log_dir=vdl_dir/scalar --eval
# yolov3
#python -u tools/train.py -c configs/hw_configs/yolov3_mobilenet_v1_roadsign_voc_template.yml -o use_gpu=True --use_vdl=True --vdl_log_dir=vdl_dir/scalar --eval
# fcos
#python -u tools/train.py -c configs/hw_configs/fcos_r50_roadsign_coco_template.yml -o use_gpu=True --use_vdl=True --vdl_log_dir=vdl_dir/scalar --eval
# 下述命令会在127.0.0.1上启动一个服务,支持通过前端web页面查看,可以通过--host这个参数指定实际ip地址
visualdl --logdir vdl_dir/scalar/
4.优化器
https://aistudio.baidu.com/aistudio/projectdetail/1449472
Paddledetection的C++预测部署
https://aistudio.baidu.com/aistudio/projectdetail/2404893
https://blog.csdn.net/m0_63642362/article/details/125956462
