前端性能优化
一、地址栏输入URL发生了什么
大致分为:DNS域名解析、TCP连接、HTTP请求、处理请求返回HTTP响应、页面渲染、关闭连接

- 首先会进行 url 解析,根据 dns 系统进行 ip 查找
- 根据 ip 就可以找到服务器,然后浏览器和服务器会进行 TCP 三次握手建立连接,如果此时是 https 的话,还会建立 TLS 连接以及协商加密算法(注意的问题"https 和 http 的区别")
- 连接建立之后浏览器开始发送请求获取文件,此时这里还会出现一种情况就是缓存,建立连接后是走缓存还是直接重新获取,需要看后台设置,涉及到"浏览器缓存机制"
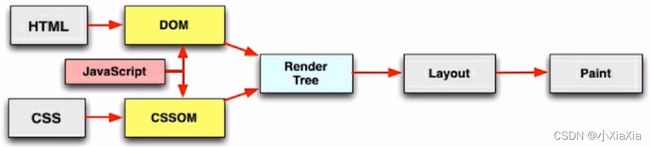
- 首先获取 html 文件,构建 DOM 树。这个过程是边下载边解析,并不是等 html 文件全部下载完了,再去解析 html,这样比较浪费时间,而是下载一点解析一点。同时浏览器主进程负责下载 CSS 文件
- CSS 文件下载完成,解析 CSS 文件成树形的数据结构,然后结合 DOM 树合并成 RenderObject 树
- 布局 RenderObject 树 (Layout/reflow),负责 RenderObject 树中的元素的尺寸,位置等计算
- 绘制 RenderObject 树 (paint),绘制页面的像素信息
- 浏览器主进程将默认的图层和复合图层交给 GPU 进程,GPU 进程再将各个图层合成(composite),最后显示出页面
(4、5、6、7、8属于浏览器渲染)
二、性能优化
(联系博文“http相关”理解)
1、http请求的过程是前端性能优化的核心
减少请求数量
- 将小图片打包成base64
- 利用雪碧图融合多个小图片
- 利用缓存
减少请求时间
- 将js,css,html等文件能压缩的尽量压缩,减少文件大小,加快下载速度
- 利用webpack打包根据路由进行懒加载,不要初始就加载全部,那样文件会很大
- 升级到高版本的http
- 建立内部CDN能更快速的获取文件
部分词解释
a. html压缩
HTML代码压缩就是压缩一些在文本文件中有意义,但是在HTML中不显示的字符,包括空格,制表符,换行符等,还有一些其他意义的字符,如HTML注释也可以被压缩;
方式:使用在线网站进行压缩、nodejs提供的html-minifier工具、后端模板引擎渲染压缩
b.css代码压缩
分为无效代码的压缩、css语义合并
方式:使用在线网站进行压缩、使用html-minifier对html中的css进行压缩、使用clean-css对css进行压缩
c.js压缩与混乱
包括:无效字符的删除(空格,回车等)、剔除注释、代码语义的缩减和优化、代码保护(如果代码不经处理,客户端可直接窥探代码漏洞)
方式:使用在线网站进行压缩(https://tool.oschina.net/jscompress/)、使用html-minifier对html中的js进行压缩、使用uglify.js2对js进行压缩
d.文件合并
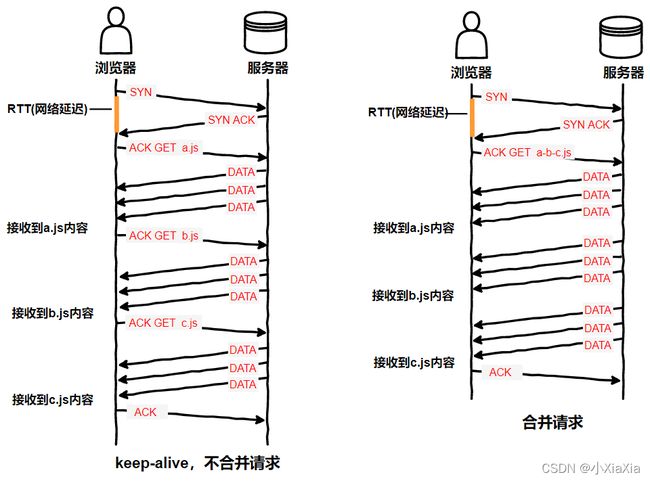
左边的表示使用http长链接keep-alive但不合并请求的情况,需要分三次去获取a.js、b.js、c.js;右边是使用长链接并且合并请求的情况,只需要发送一次获取合并文件a-b-c.js的请求,就能将三个文件都请求回来。
不合并请求有下列缺点:
- 文件与文件之间有插入的上行请求,会增加N-1个网络延迟;
- 受丢包问题的影响更严重:因为每次请求都可能出现丢包的情况,减少请求能有效减少丢包情况;
- keep-alive本身也存在问题:经过代理服务器时可能会被断开;
文件合并存在的问题
首屏渲染问题:当请求js文件的时候,如果页面渲染只依赖a.js文件,由于文件合并,需要等待合并后的a-b-c.js文件请求回来才能继续渲染,这样就会导致页面渲染速度变慢。这种情况大多出现在现代化的前端框架,如Vue等的使用过程中;
缓存失效问题:合并后的文件a-b-c.js中只要其中一个文件(比如a.js)发生变化,那么整个合并文件都将失效,而不采用文件合并就不会出现这种情况;
使用建议:
公共库合并:将不经常发生变化的公共组件库文件进行合并;
将不同页面的js文件单独合并:比如在单页面应用SPA中,当路由跳转到具体的页面时才请求该页面需要的js文件;
方式:使用在线网站进行文件合并、使用nodejs实现文件合并、使用webpack等前端构件化工具也可以很好地实现;
2、图片相关的优化
有损压缩过程

不同格式图片常用的业务场景
- jpg有损压缩,压缩率高,支持透明;应用:大部分不需要透明图片的业务场景;
- png支持透明,浏览器兼容好;应用:大部分需要透明图片的业务场景;
- webp(2010年由谷歌推出)压缩程度更好,在ios webview中有兼容性问题;应用:安卓全部;
- svg矢量图,代码内嵌,相对较小,用于图片样式相对简单的场景;应用:比如logo和iconfont
2.1图片压缩
针对真实图片情况,舍弃一些相对无关紧要的色彩信息。如在线压缩网站:https://tinypng.com/
2.2css雪碧图
将网站上用到的一些图片整合到一张单独的图片中,从而减少网站HTTP请求数量。
原理:设定整张雪碧图可示区域,将想要显示的图标定位到该处(左上角);
缺点:整合图片比较大时,一次加载比较慢。
2.3网页内联图片(Image inline)
将图片的内容内嵌到html当中,减少网站的HTTP请求数量,常用于处理小图标和背景图片。网页内联图片写法为:
<imgsrc="data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAA..."alt="">
浏览器上的表现形式为:
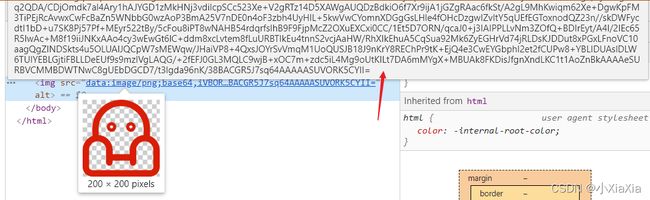
image 转 DataUrI的网址:DataUrl
缺点:浏览器不会缓存内联图片资源、兼容性较差,只支持ie8以上浏览器、超过1000kb的图片,base64编码会使图片大小增大,导致网页整体下载速度减慢
2.4矢量图SVG与iconfont
- 使用iconfont解决icon问题,应尽量使用该方式,比如可以采用阿里巴巴矢量图库:
- 使用SVG进行矢量图的控制
SVG 意为可缩放矢量图形(Scalable Vector Graphics)。SVG 使用 XML 格式定义图像。
2.5webp
webp的优势体现在它具有更优的图像压缩算法,能带来更小的图片体积,而且拥有肉眼识别无差异的图像质量;同时具备了无损和有损的压缩模式、Alpha透明以及动画的特性。在JPEG和PNG上的转化效果都非常优秀、稳定和统一。安卓上不存在兼容性问题,推荐安卓下使用。
在线网站将图片转换为webp:webp
像图片这样的静态文件可以存放在CDN服务器上,让CDN服务器批量地将图片转换成Webp格式;
3、懒加载和预加载
3.1 懒加载
图片进入可视区域之后再请求图片资源的方式称为图片懒加载。适用于图片很多,页面很长的业务场景,比如电商
懒加载的作用:
-
减少无效资源的加载
比如一个网站有十页图片,用户只查看了第一页的图片,这就没必要将十页图片全都加载出来; -
并发加载的资源过多会阻塞js的加载,影响网站正常的使用
由于浏览器对某一个host name是有并发度上限的,如果图片资源所在的CDN和静态资源所在的CDN是同一个的话,过多图片的并发加载就会阻塞后续js文件的并发加载。
懒加载实现的原理:
监听onscroll事件,判断可视区域位置:
图片的加载是依赖于src路径的,首先可以为所有懒加载的静态资源添加自定义属性字段,用于存储真实的url。比如是图片的话,可以定义data-src属性存储真实的图片地址,src指向loading的图片或占位符。然后当资源进入视口的时候,才将src属性值替换成data-src中存放的真实url。

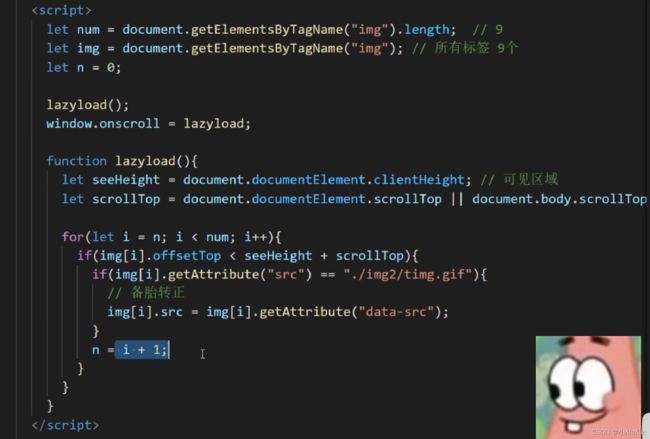
(./img2/timg.gif是图片还没加载时同一展示的一张加载图,也就是src的初始值)
//.jpg_.webp表示当浏览器支持webp时采用webp格式,否则采用jpg格式。
<img src="" class="image-item" alt="" lazyload = "true" data-src="TB27YQvbm_I8KJjy0FoXXaFnVXa_!!400677031.jpg_180x180xzq90.jpg_.webp">
懒加载实例
可以使用元素的getBoundingRect().top来判断当前位置是否在视口内,也可以使用元素距离文档顶部的距离offsetTop和scrollTop是否小于视口高度来判断:

举例:

当快要滚动到需要展示的图片时才进行图片的请求,可以看到图片上有一个lazyload的属性:
(使用插件lazyload)

3.2预加载
预加载与懒加载正好是相反的过程:懒加载实际上是延迟加载,将我们所需的静态资源加载时间延后;而预加载是将图片等静态资源在使用之前的提前请求,这样资源在使用到时能从缓存中直接加载,从而提升用户体验;
预加载的作用:
- 提前请求资源,提升加载速度:使用时只需要读取浏览器缓存中提前请求到的资源即可;
- 维护页面的依赖关系:比如WebGL页面,会依赖一些3D模型,这些都是页面渲染所必须的资源。如果资源都没有加载完毕就进行页面的渲染,就会造成非常不好的体验。
所以时常使用预加载的方式维护页面渲染的依赖关系,比如将WebGL页面依赖的3D模型加载完之后才进行页面渲染。这样渲染的过程就不会有任何阻碍,具有较好的用户体验;
预加载的实例
例如九宫格抽奖业务,每个奖品都有一个选中态和非选中态,实际上这是由两张图片组合而成的。由于每个奖品的选中过程都是一瞬间,这就对图片的选中态和非选中态切换效率要求很高,如果选中态的图片没有预加载的话显然是来不及的

对于九宫格中所有图片选中态的样式和对应的图片都需要进行预加载,从而让我们在抽奖的过程中,能够瞬间从缓存中读取到选中态的图片,从而不影响抽奖效果的展示。
除此之外还有网站登录或活动时需要用到的动画,这是在动画需要的每帧图片都完全预加载完之后才会进行显示的。
4、重绘与回流
实战优化点:
如果我们需要使得动画或其他节点渲染的性能提高,需要做的就是减少浏览器在运行时所需要做的下列工作:
- 计算需要被加载到节点上的样式结果(Recalculate style–样式重计算);
- 为每个节点生成图形和位置(Layout–回流和重布局);
- 将每个节点填充到图层中(Paint Setup和Paint–重绘);
- 组合图层到页面上(Composite Layers–图层重组);
4.1 使用translate替代top等属性来改变位置;
使用top属性改变正方形位置时,存在重绘和回流Layout:
而使用translate属性改变正方形位置时,并不会引起重绘和回流:
4.2使用opacity替代visibility:
使用visibility不触发重排,但是依然重绘;
直接使用opacity既触发重绘,又触发重排(GPU底层设计如此!);
opacity配合图层使用,既不触发重绘也不触发重排;
原因:透明度的改变时,GPU在绘画时只是简单的降低之前已经画好的纹理的alpha值来达到效果,并不需要整体的重绘。不过这个前提是这个被修改opacity本身必须是一个单独的图层。
4.3将多次改变DOM元素样式属性的操作合并成一次操作:
预先定义好class,然后通过修改DOM的className来添加样式;
4.4把DOM离线后再修改:
由于display属性为none的元素不在渲染树中,对隐藏的元素操作不会引发其他元素的重排。如果要对一个元素进行复杂的操作时,可以先隐藏它,操作完成后再显示。这样只在隐藏和显示时触发2次回流
4.5不要使用table布局:
因为很小的一个改动都会造成整个table的重新布局;所以尽量使用div布局;
4.6启用GPU硬件加速:
原理为:浏览器会检测一些特定的css属性,当DOM元素拥有这些css属性的时候,浏览器就会对该DOM元素启动GPU硬件加速;比如:transform: translateZ(0)和transform: translate3d(0, 0, 0)这两个属性都可以启动硬件加速;硬件加速同样不能滥用,否则会导致图层过多,导致合并图层时消耗大量性能。
4.7动画实现速度的选择、为动画元素新建图层,提高动画元素的z-index
这里省略一些点…,可自行参考
5、函数防抖与节流
1.函数防抖
概念:不断触发一个函数,在规定时间内只让最后一次生效,前面都不生效;
实现:定时器;
应用:搜索时等用户完整输入内容后再发送查询请求;
代码实现
function debounce(fn,delay){
var timer = null
// 清除上一次延时器
return function(){
clearTimeout(timer)
// 重新设置一个新的延时器
timer = setTimeout(() => {
fn.call(this)
}, delay);
}
}
使用函数防抖可以减少事件触发的次数和频率,在某些情况下可以起到优化的作用。比如:搜索框,对于核心业务非搜索的网站,一般都是等待用户完整输入内容后才发送查询请求,一次来减少服务器的压力。像百度这样的核心业务为搜索的网站,服务器性能足够强大,所以不进行函数防抖处理;
2.函数节流
概念:不断触发一个函数后,执行第一次,只有大于设定的执行周期后才会执行第二次,以此控制函数执行频率;
实现:定时器,标识;
应用:在游戏中,可以设定人物攻击动作的最快频率,无论手速多快也无法超越这一频率;
代码实现
/*
节流函数:fn:要被节流的函数,delay:规定的时间
*/
functionthrottle(fn, delay){
// 记录上一次函数出发的时间
var lastTime = 0
return function(){
// 记录当前函数触发的时间
var nowTime = new Date().getTime()
// 当当前时间减去上一次执行时间大于这个指定间隔时间才让他触发这个函数
if(nowTime - lastTime > delay){
// 绑定this指向
fn.call(this)
//同步时间
lastTime = nowTime
}
}
}
6、浏览器存储
6.1Cookie
生成方式:
- 客户端生成:
在 JavaScript 中通过 document.cookie 属性,你可以创建、维护和删除 Cookie;设置 document.cookie 属性的值并不会删除存储在页面中的所有 Cookie,它只简单的创建或修改字符串中指定的 Cookie。 - 服务端生成:
Web 服务器通过在HTTP响应头中添加 Set-Cookie字段来创建一个 Cookie,可以在该字段中添加HttpOnly属性禁止JavaScript脚本访问Cookie,以此来避免跨域脚本 (XSS) 攻击。
Cookie的缺陷: - 安全性:由于Cookie在HTTP中是明文传递的,其中包含的数据都可以被他人访问,出现篡改、盗用等问题;
- 大小限制:Cookie的大小限制在4KB左右,若要做大量存储显然不是理想的选择;
- 增加流量:因为Cookie是绑定域名对应的服务器的,所以对同一个域名的每次请求都会在Request Header中带上Cookie
一方面:增加对服务器的请求时间;另一方面:导致大部分不需要用到Cookie信息的场合下流量的浪费;这样浏览器对同一域名的每一次请求都会多出4KB流量,对于大型网站来说这是很大的损耗。
因此要慎用Cookie,不要在Cookie中存储重要和敏感的数据。
Cookie性能优化的方法:
将存放静态资源的CDN服务器域名与主站的域名独立开来。这样每次请求静态文件的时候就不需要携带Cookie,从而可以节省很多流量。
例子:
比如在百度进行登录的时候,请求头里面就会有Set-Cookie字段,其中的BDUSS就是标识用户登录状态的字符串:

Set-Cookie中的httponly属性表示的是禁止js脚本访问cookie,这样能够一定程度防范XSS攻击;
在Chrome调试工具的Application选项中查看Cookies信息,可以发现该Cookie已经被网站“种”到Domain:.baidu.com这个域名下了,并且该Cookie也设置了HttpOnly属性:

此后浏览器的每次请求都会在请求头Request Headers中携带这一Cookie信息。刷新页面后可以看到,请求头中携带了Cookie信息BDUSS:

这样服务器就知道这是已经登录的用户了。
但是不是所有的请求都需要携带Cookie信息,比如优酷:

可以看到请求index.css文件时也携带了Cookie,但是这是不必要的,这就会导致流量的浪费。
所以,将CDN域名和主域名独立出来;
如百度:

可以看到请求这个静态资源的url并不是.baidu.com,而是静态资源服务器CDN;并且该请求的请求头中不会携带Cookie信息:

设置和获取Cookie
设置Cookie的方式很简单,key和value值通过等号连接:
document.cookie = "userName=zhangsan"

打开Application选项查看当前Cookie,可以看到Cookie已被改变:

获取Cookie:document.cookie
备注:
- 静态资源是不会携带Cookie的;
- Cookie一般都是后台种的,很少让前端来直接写;
- Cookie分:持久级别、session级别;
- Cookie一般用于存放session ID与服务器端进行通信;
6.2Web Storage
Web Storage分为SessionStorage和LocalStorage专门用于客户端浏览器的本地存储,同时空间比Cookie大很多,一般支持5-10M;
浏览器端通过 Window.sessionStorage 和 Window.localStorage 属性来实现本地存储机制;
LocalStorage
- LocalStorage是HTML5设计出来专门用于存储浏览器信息的:
- 大小为5~10M左右;
- 仅在客户端中使用,不和服务端进行通信;
- 接口封装较好,提供了js进行读写等操作的API;
- 采用浏览器本地缓存方案,可直接使用浏览器本地缓存,提升网页渲染的速度
如:
比如通过Chrome调试工具的Application选项可以查看淘宝中LocalStorage存储的数据:

这些数据只要不手动清除,即使关闭页面也都会存在。当需要使用图片、js/css文件等资源时就不用重新向服务器发出请求,而是可以直接使用LocalStorage中的缓存,这就是LocalStorage缓存的优势;
而Cookie就不一样了,里面存储的数据都是要带到服务器端的,例如用户登录状态,统计信息等数据:

设置和获取LocalStorage
LocalStorage提供了相对简单的API,采用的也是key和value的形式。
设置时:
localStorage.setItem("key", "value")
获取时:
localStorage.getItem("key")
移除时:
//该方法接受一个键名作为参数,并把该键名从存储中删除。
localStorage.removeItem('key');
//调用该方法会清空存储中的所有键名
localStorage.clear();
SessionStorage
SessionStorage用于存储浏览器的会话信息,标签页关闭之后它存储的数据就会被清空,而LocalStorage的数据不会被清空,这是二者的区别:
- 大小为5~10M左右;
- 仅在客户端使用,不和服务端进行通信;
- 接口封装较好;
- 可对表单信息进行维护;比如添加表单过程中进行了刷新,可以将刷新前填写的信息写入SessionStorage中,这样即使刷新后数据也不会丢失;还有一种场景:分页的表单在进行前进或后退时,如果将信息保存在SessionStorage中就不会丢失;
相应方法:
//设置
sessionStorage.setItem("key", "value")
//获取
sessionStorage.getItem("key")
//该方法接受一个键名作为参数,并把该键名从存储中删除。
sessionStorage.removeItem('key');
//调用该方法会清空存储中的所有键名
sessionStorage.clear();
总结
- 减少 HTTP 请求
- 使用 HTTP2
- 使用服务端渲染
- 静态资源使用 CDN
- 将 CSS 放在文件头部,JavaScript 文件放在底部
- 使用字体图标 iconfont 代替图片图标
- 善用缓存,不重复加载相同的资源
- 压缩文件
- 图片优化
- 通过 webpack 按需加载代码,提取第三库代码,减少 ES6 转为 ES5 的冗余代码
- 减少重绘重排
link
link