论文阅读:Synthesizing Obama: Learning Lip Sync from Audio
文章目录
-
-
- 音频到landmarks
- 面部纹理合成
-
- 候选帧选择
- 加权中位数纹理的合成
- 牙齿proxy (Teeth Proxy)
-
音频到视频部分出现的术语:
- stock video footage:the many hours of online weekly address video
- source:the input audio track
- target video: stock video clip into which we composite the synthesized mouth region
音频到landmarks
- 音频部分的处理:
- 给定16KHz单声道音频, 使用ffmpeg的RMS-based normalization 正则化volume
- 在每个25ms长的滑动窗口上进行离散傅里叶变换, 采样间隔为10ms
- 在傅里叶功率谱上应用40个三角形的Mel-scale lters,对输出进行对数处理。
- 应用离散余弦变换,将维度降低到13维矢量。
最后输出28维度的向量, 13维度加上对数平均能量和其一阶导数
- 脸部的处理:
- 对每帧obama的脸进行frontalize, 正面化, 用了14年的论文:Total moving face reconstruction
- 然后检测嘴部landmarks, 这里是给出了18个点, 也就是36个数, 然后PCA到20维的系数
- Finally, we temporally upsample the mouth shape from 30Hz to 100Hz by linearly interpolating PCA coeffcients, to match the audio sampling rate. Note that this upsampling is only used for training; we generate the final video at 30Hz.(最后,我们通过线性插值PCA系数将口型从30Hz升采样到100Hz,以匹配音频采样率。请注意,这种上采样只用于训练;我们以30Hz的频率生成最终视频。)
之前音频间隔是10ms也就是1s取100次, 视频1s100hz也就是1s采样100次,和音频一一对应, 这里是正常取了30,中间的通过插值得到
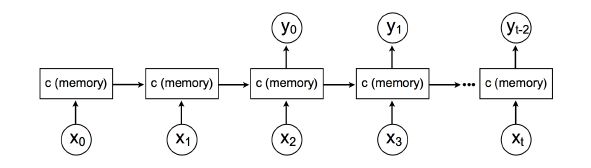
- RNN的处理:
重要的点:音频和嘴部并不完全同步, 举个例子, 比如你张开嘴发出啊的声音, 但是可能张嘴要比出声早了一点时间, 所以说网络需要看到未来的一部分音频信息, 比如我关注到几十个ms后的啊了我就知道应该张嘴了
-
所以在这里很重要的一点是要添加time delay, 把网络输出在时间上向前移动, 为输出增加时间延迟, 也就是说输入是当前的声音, 但是预测的landmarks有些许的延后, 这样效果挺好
-
time-delayed RNN的delay为2, 网上一般叫target-delay, 搜了好长时间才发现····
效果图如下:
这里有个疑问, 这样的话输入和输出相比不是一一对应的, 前面说是音频和视频采样率调整到一致了, 这个地方是怎么处理的呢?
是不是输出还是同样的, 但是我不取前两个而是取后面的作为输出? -
cell state c是60维, time delay是20 steps(200 ms), 也就是预测的嘴部会落后音频200ms
这部分我看了源码之后懂了, 来自Obama Net的train.py:
timeDelay = 20
lookBack = 10
n_epoch = 20
n_videos = 12
for key in tqdm(keys[0: n_videos]):
audio = audioKp[key]
video = videoKp[key]
if (len(audio) > len(video)):
audio = audio[0: len(video)]
else:
video = video[0: len(audio)]
start = (timeDelay - lookBack) if (timeDelay - lookBack > 0) else 0
for i in range(start, len(audio) - lookBack):
a = np.array(audio[i: i + lookBack])
v = np.array(video[i + lookBack - timeDelay]).reshape((1, -1))
X.append(a)
y.append(v)
- 这里audio是一个序列,但是landmarks是一个, 也就是一个序列预测一个landmarks, 同时landmarks是超前audio一点的, 超前的数字是time delay
model = Sequential()
model.add(LSTM(25, input_shape = (lookBack, 39)))
model.add(Dropout(0.25))
model.add(Dense(8))
- 这是用keras写的, 输出是8然后经过PCA一些处理之后得到正常的40
面部纹理合成
-
有了landmarks怎么到人脸呢, 有些方法是用嘴部的替换原来的, 然后经过pix2pix合成过去, 但是很明显的一点是假如测试的时候并没有嘴部的牙齿等细节, 网络怎么能够输出细节呢?看看这篇文章怎么做的。
-
因为这篇文章主要合成的是嘴部的关键点,所以主要是合成下部脸部区域像嘴巴,下巴, 脸颊和鼻子嘴巴周围的区域。 看看下面的mask:

a 是没有衬衫的区域,加上neck和shirt部分, mouth是合成的部分, 最后得到的合成的frame
这个mouth区域是怎么合成的呢, 一步步来吧。
作者提到, Instead, we propose an approach that combines weighted median and high frequencies from a teeth proxy。 也就是把teeth proxy的加权中位数和高频的信息融合起来。
现在我们有嘴部关键点和target video, 算法概述如下:
- per mouth PCA shape, select a fixed number of target video frames that best match the given shape; 对于每个嘴部PCA后的shape, 选择固定数量的最符合给定shape的video frames, 比如说算算序列嘴部的距离平均值, 最小就选这个序列
- apply weighted median on the candidates to synthesize a median texture; 在候选的身上应用加权中位数合成中位数纹理
- select teeth proxy frames from the target video, and transfer high-frequency teeth details from the proxy into the teeth region of the media texture. 从目标视频中选择teeth proxy frames, 然后把高频的牙齿细节transfer到介质的texture, 下面逐一介绍。
候选帧选择
- 给定生成的嘴部shape, 选取最匹配的帧。 方法如下:
-
在目标视频上检测landmarks, 同时估计3D pose并正面化, 因为之前landmarks是正面化的, 计算3D face model用到了论文Total moving face reconstruction., 其实就是他自己论文hhhh, 同时使用下巴和背景的粗略近似来增强它, 作者说这个增强显著改善了正面化的结果, 没开源说个·····
-
3d face model 被扩展到包括下巴, 通过假设一个平面背景并求解一个连接face 和背景的光滑平面来实现, 3D face model is extended to include the chin by assuming a planar background and solving for a smooth surface that connects the face to the background.
-
最小化面部的二阶导数: 假设初始表面参数化在二维深度图上:
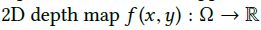

这个地方挺难搞懂, 就贴了原文。思想就是重建3d model, 重建后包含下巴,如下图:

- 然后对每个帧估计drift-free 3D pose, 把模型用到每一帧上, 然后把头部向后投影到正面视图。 尽管这个geometry在远离face的地方不准确, 但是it suffices as a frontal-warping proxy since the final synthesized texture will be warped back to the original pose using the same geometry.(它足以作为一个正面扭曲的代理,因为最终合成的纹理将被扭曲到使用相同几何体的原始姿态。)
纹理是在一个由manually drawn的mask所指定的区域内合成的, 包括正面姿势下的脸部和脖子区域。
mask只画一次。此外,由于在某些姿势下,颈部被遮挡,我们在每一帧视频中自动遮挡衣服(通过HSV空间的简单阈值处理;所有结果都使用相同的阈值), 并对被遮挡的区域进行in-paint, 使用OpenCV实现。
一旦所有的帧都被正面化并计算出姿势,就会选择帧的口形与目标口形之间具有最小的L2距离的n个帧。
加权中位数纹理的合成
现在我们有一组正面化的嘴部候选帧图像 { I 1 , . . . I n } \{I_1, ...I_n\} {I1,...In}以及与其相关的嘴部shape S 1 , . . . S n S_1, ...S_n S1,...Sn, S i ∈ R 2 ∗ 18 S_i\text∈R^{2*18} Si∈R2∗18, 同时还有目标嘴部的shape S t a r g e t S_{target} Starget, 首先计算每个像素的加权中位数 ( u , v ) (u, v) (u,v):

这是每个R, G, B通道单独计算的, c是输出像素的强度, w i w_i wi代表 S i S_i Si和 S t a r g e t S_{target} Starget的相似程度.

选择正确的 σ σ σ挺重要, 太小会create a peak distribution on a few images which can cause temporal flickering(在几个图像上创建一个峰值分布,这可能会导致时间的抽流), 类似于拍摄单一的原始画面。大的 σ σ σproduce a blurry result.

也就是说这个参数是动态选择的一个所有帧的加权值, 公式如下:
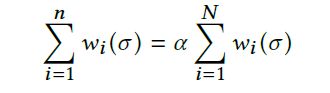
其中N是视频帧的总数。是可以用二进制搜索的方式有效地解出 σ σ σ我们将 σ σ σ调至0.9,并将n调至
视觉质量和时间平滑度之间的最佳平衡。(图4)。一旦选择了n,每个输出帧的 σ σ σ都会变化
在计算了所有的 w i w_i wi之后,方程9就可以通过对像素强度的排序来有效地解决了。
同时挑选位于总权重的一半的强度




这里是说候选n不能太少, 需要一个合适的值,
牙齿proxy (Teeth Proxy)
合成逼真的牙齿是令人惊讶的挑战。牙齿必须显得僵硬、锋利、姿势对齐、光线正确,并正确遮挡嘴唇。我们对先前方法的评估都表现出这些问题的一个或多个方面。特别是,类似 AAM 的模型产生了模糊的结果,而牙齿代理方法产生了组合伪影
作者提到实现的最好方法combines low-frequencies from the weighted median texture, and
high frequency detail from a teeth proxy image(结合了加权中位数纹理的低频和牙齿代理图像的高频细节)
the key insight is that the median texture provides a good (but blurry) mask for the teeth region, whereas the teeth proxy does a good job of capturing sharp details.(中值纹理为牙齿区域提供了良好的但blurry的mask, teeth proxy在捕捉锐利细节方面挺好)Hence, we apply the high frequencies of the teeth proxy only in the (automatically detected) teeth region of the median image.(因此作者在自动检测出的中位image牙齿区域应用牙齿代理的高频信息)
牙齿代理参考帧是手动选择的,是牙齿正面朝上且高度可见的目标帧之一。
我们需要一个上牙代理和一个下牙代理;这两个代理可以从不同的帧中选择。这是一个手工操作的步骤,必须对每个目标序列进行重复。

通过在landmarks中给出的口腔区域内的 HSV 空间中应用阈值(低饱和度、高值),检测到中位纹理中的牙齿区域,我们将向该区域传输代理详细信息。因为牙齿是明显的白色, 所以有hsv的限制, 假如是RGB的话那么应该限制在大约255? 我猜测可能是这样, 映射到1的话那就都是1左右.