老树开新花:在MyEclipse环境中配置和使用SpringBoot——连接数据库
前言
上一篇:老树开新花:在MyEclipse环境中配置和使用SpringBoot——第一个SpringBoot工程
好了,经过上一篇的罗嗦,我们的原始工程已经能够以SpringBoot Main程序的方式启动了,也就是说,“老树”开始“冒嫩芽”了。
Ummm...但是,一个Java Web工程大多都还是需要连接数据库,并且进行读写操作的。好在从现在来看,大约差不多有个十多年的时间跨度,在这个跨度中的很多老旧的Java Web项目都会或多或少用过Hibernate来处理与数据库的交互。我们只需要将其相关的依赖升级到SpringBoot所支持的版本即可。额外需要做的,可能就是处理一下一些反射方式。
如果您手里的项目工程比这更老旧,可以追溯到新千年前后,几乎没有用到 Hibernate这样的框架,而是采用的传统的jdbc手动代码,那您反而更不用担心,因为那处理起来更为容易。
好了,让我们先从配置文件开始吧。

properties配置
Java程序用来与数据库进行连接并存取数据的方式似乎亘古以来都没怎么太变过——JDBC。这很让人收益,甚至让人反过来觉得其它语言使用ODBC连接数据库简直太繁琐,甚至是反人类。
所幸的是,在最新的SpringBoot框架体系中,我们仍然使用JDBC来处理数据库事务——它是一切的本源。因此,我们就像过去老旧项目一样,先从编写JDBC数据库连接字符串配置开始。
过往的SpringMVC经验让我们习惯性地会将JDBC连接配置单独编写在一个“.properties”文件中,然后再将它引入到其他Spring配置文件中,这使得我们能够在对项目工程进行部署及上线时,能够单独维护与数据库的连接。非常幸运的是,SpringBoot摒弃了其它所有形式的配置文件,但仍然保留了“.properties”文件。
很显然,“.yml”文件并不在我们讨论的范围内,尽管它十分简单易懂,并且在SpringBoot工程构筑过程中可以与“.properties”文件相互替代。
首先,我们需要在resource folder中创建一个“.properties”文件,并且将它固定命名为“application.properties”。之所以这样命名,是因为SpringBoot会自动去搜索这个文件,并把其中的配置项作为初始化参数。
完成之后,我们就可以直接编辑这个文件了。在其中写下如下的配置:
spring.datasource.url=jdbc:mysql://localhost:3306/yumi_website_sys
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=root很明显,我们需要根据实际情况来改变其中的ip地址、端口、数据库名或是连接账户和密码。
原则上,这些配置其实已经足够了。因为SpringBoot会自动去判断数据库的类型。但是我想这并不是一个“老年人”的习惯性思维,所以我们还是“坚持”要把其它配置也都加上。
下面这段配置用来指明数据库的类型和方言:
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
spring.jpa.properties.database-platform=mysql
spring.jpa.properties.database=mysql有意思的是,我们从配置项的名称就能看出,SpringBoot使用了JPA去对数据库进行操作。但实际上,在JPA的后面,隐含的仍然是Hibernate。因此,在使用SpringBoot的时候,我们是可以绕开JPA直接去使用Hibernate的。
下面这段配置也非常重要,它禁止了SpringBoot启动的时候,根据实体类去反向修改数据库的表结构:
spring.jpa.hibernate.ddl-auto=none容我在这件事情上多罗嗦几句。
事实上,我个人认为在程序启动的时候,由实体类的变化去引发数据库表结构的改变并不是一件值得称颂的好事。我始终认为,一个良好的数据库结构设计是项目成功的根本。当我们面对一幅设计完整的ER图的时候,我们能够一眼就清晰地看出每一张业务表所表达的含义,以及它们之间的相互关系。在面向对象的设计过程中,这种表结构关系同时也会反映出实体类的相互关系,从而对构筑出一个完整而毫不杂乱的整体业务模型。
而当客户或用户的需求发生了变化,无论是改变还是新增,我们都能够很容易地看出这些变化同时会影响到其它那些既有的业务,从而帮助我们对整个项目进行统一把控。
当利用一个设计完好的数据库表结构设计去生成一个原始数据库之后,我们就能够轻松地利用各种插件来从表自动生成对应的实体模型类。我认为这是一个正规而正常的过程。
而JPA反向编辑数据库的过程,看起来似乎简化了开发人员的工作,使得设计人员能够免除数据库设计的繁琐。但是,我个人的实际经验告诉我,几乎所有没有数据库设计的项目到最后都会陷入无法维继的窘迫境地——开发人员根本无法全盘掌控客户的整体业务模型和逻辑。
不断且随意地修改实体类的结构,以及它们之间的相互关系,无异于在一个依然杂乱无张的贫民区继续构造各种危险的违章建筑。直到最后,一点点细小而不为人察觉的火星,就能够颠覆这一整片杂乱的社区——即便救火队到达了现场,也绝对无法快速找到出现问题的根源,也不知道这些乱糟糟的违章建筑之间是不是存在着不为人所知的关联关系。
至少在我的从业经历里,我所遇到的倡导无数据库设计的开发人员,其真实本质基本上都是没有能力去做设计的人。
完全没有设计图纸的建筑物,我想没有人会想要住进去的吧。
Ummm...上了年纪的就是爱罗嗦。让我们赶快回来吧。
最后一个配置项如下面所示,它允许我们将SQL语句按照更加漂亮的格式输出:
spring.jpa.properties.hibernate.show-sql=true
spring.jpa.properties.hibernate.format-sql=true至此,我们的整个“application.properties”配置文件看起来像是这样的:
spring.datasource.url=jdbc:mysql://localhost:3306/yumi_website_sys
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.username=root
spring.datasource.password=root
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL57Dialect
spring.jpa.properties.database-platform=mysql
spring.jpa.properties.database=mysql
spring.jpa.hibernate.ddl-auto=none
spring.jpa.properties.hibernate.show-sql=true
spring.jpa.properties.hibernate.format-sql=true依赖
接下来,为了避免在后续步骤当中我们的源代码出现编译错误,我们需要先在pom.xml文件中添加必要的依赖:
org.springframework.boot
spring-boot-starter-data-jpa
2.3.1.RELEASE
mysql
mysql-connector-java
5.1.34
commons-io
commons-io
2.6
实体类
下一步,既然已经有了需要连接的数据库,那意味着我们应该已经有了一些数据库表。因此,我们可以直接使用MyEclipse中的Hibernate插件来直接生成实体类。为了能够与老旧的项目工程保持最大程度的兼容,我们考虑为自己的工程添加Hibernate facet支持(如果您的老旧项目已经有被Hibernate所支撑的实体类,那么可以跳过这个步骤):
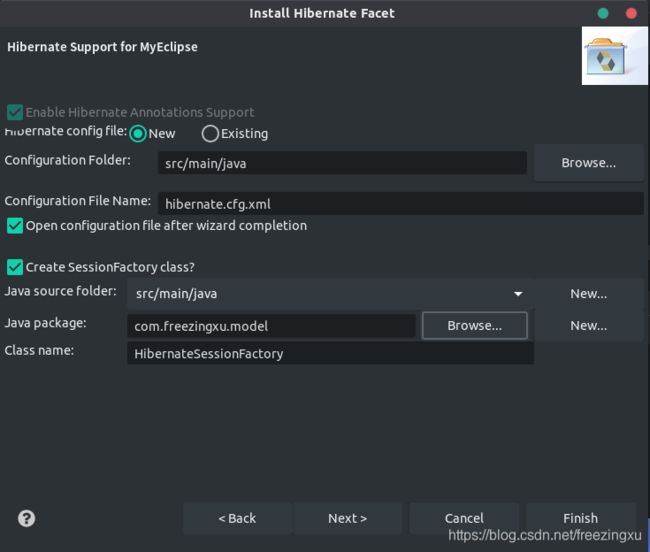
有了这一步做基础,我们就能够从数据库直接生成实体类了:
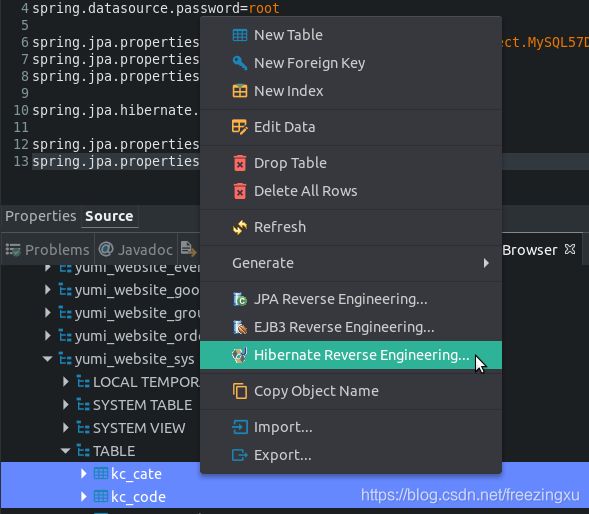
嗯,我想这一步非常容易,许多仍然喜欢MyEclipse的程序员一定对这一操作非常熟悉。所以我们得到的实体类已经包含有必要的注解以及get和set方法,几乎可以不用做任何修改。
具体的代码我在这里就不贴出来了。需要注意的是,在Hibernate5.*的版本中,如果我们对主键生成规则仍然采用“uuid.hex”的话,虽然不影响使用,但是我们会收到这样一条警告:
org.hibernate.id.UUIDHexGenerator 42 - HHH000409: Using org.hibernate.id.UUIDHexGenerator which does not generate IETF RFC 4122 compliant UUID values; consider using org.hibernate.id.UUIDGenerator instead 想要调整的话,就如警告中所述一般,使用“org.hibernate.id.UUIDGenerator”来代替“uuid.hex”即可:
@Id
@GenericGenerator(name = "generator", strategy = "org.hibernate.id.UUIDGenerator")
@GeneratedValue(generator = "generator")Repository
接下来是对数据库的操作层。在过往的SpringMVC-Hibernate框架中,很多人也许和我一样,习惯把这一代码层称为“DAO”。但是在SpringBoot所使用的JPA中,把这些代码层称之为“Repository”。
所以,我们需要建立一些用于处理数据库操作的“Repository”。幸运的是,JPA为我们封装了大多数常规的数据库读写操作,并封装成了两个主要的接口:
1、JpaRepository,其完整的包路径为:org.springframework.data.jpa.repository.JpaRepository。
2、CrudRepository,其完整的包路径为:org.springframework.data.repository.CrudRepository。
我选择了JpaRepository。事实上,我们只需要自己创建一个接口,并继承自JpaRepository接口,一切就都完成了:
public interface KcCateRepository extends JpaRepository需要注意的是,在默认的情况下,JpaRepository接口需要一个范型定义,来告诉JPA当前这个 repository主要针对的是哪一个实体类:
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.stereotype.Repository;
import com.freezingxu.model.KcCate;
@Repository
public interface KcCateRepository extends JpaRepository {
} 接口头部的注解“@Repository”的作用仍然与过往的Spring架构中的作用相同,用来表示该接口是一个数据库操作接口。
本质上,这样一个接口不需要去有具体的类来实现它。我们可以直接在代码中使用这个接口,及其从JpaRepository中所继承而来的一些方法,来完成对数据库的存取操作。我们来看一下JpaReposiroty提供了哪些标准操作:
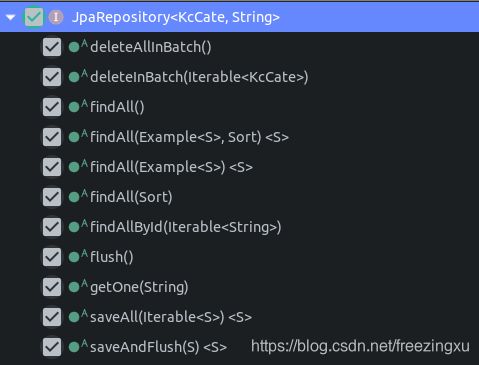
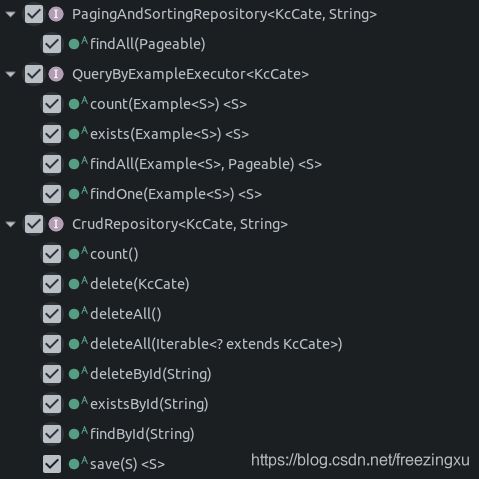
Service
除了对数据库的操作层之外,长久以来的开发习惯还让我强迫自己必须有一个Service层,来作为对业务逻辑的处理所在。关于这一点,我们只需在类的头部增加一个“@Service”注解即可:
import org.springframework.stereotype.Service;
/**
* 对映射类“KcCate”进行相关业务操作
* @Package:com.freezingxu.service.impl
* @File:KcCateManagerImpl.java
* @Date:2020-07-12 13:40:39
* @Author:freezingxu
*/
@Service
public class KcCateManagerImpl {
}在Service层的内部,使用@Autowired注解来对对应的Repository接口进行声明:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.freezingxu.repository.KcCateRepository;
/**
* 对映射类“KcCate”进行相关业务操作
* @Package:com.freezingxu.service.impl
* @File:KcCateManagerImpl.java
* @Date:2020-07-12 13:40:39
* @Author:freezingxu
*/
@Service
public class KcCateManagerImpl {
@Autowired
private KcCateRepository kcCateRepository;
}Controller
好了,最后便是Controller层了。这会稍稍有点儿与过去的MVC不太一样。我们需要创建一个Controller类,这个类将会由“@RestController”和“@RequestMapping”作为注解,前者表明这个类是一个支持restful风格的请求接收和响应处理类,而后者则指明了该类所提供的在http协议中的上下文访问路径:
@RestController
@RequestMapping("/hello")
public class HelloController {
}在这个Controller的内部,我们同样使用注解“@Autowired”来声明需要使用的Service类:
@Autowired
private KcCateManagerImpl kcCateManagerImpl;然后,我们为这个controller编写一个方法,用来捕获来自前端的请求,并返回一些响应:
@RequestMapping(value = "execute" , method = RequestMethod.POST)
@ResponseBody
public String execute(HttpServletRequest request){
}注意这个方法的一些细节:
“@RequestMapping”用“value”来指明请求的上下文,并且用“method”来指示出这个方法可以接收的数据类型。在此是二进制流数据。而“@ResponseBody”则表明了这个方法的返回数据将会直接被作为响应数据处理。
在这个方法的内部,我们通过调用Service层,来见到做一下数据查询操作:
@RequestMapping(value = "execute" , method = RequestMethod.POST)
@ResponseBody
public String execute(HttpServletRequest request){
long count = 0;
try {
BufferedReader bufferedReader = new BufferedReader (new InputStreamReader(request.getInputStream()));
String requestParameter = org.apache.commons.io.IOUtils.toString(bufferedReader);
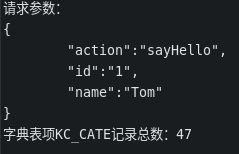
System.out.println("请求参数:\r\n" + requestParameter);
count = this.kcCateManagerImpl.getKcCateRepository().count();
System.out.println("字典表项KC_CATE记录总数:" + count);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return "hello! count = " + count;
}Run!
好了,万事具备了。我们可以尝试着运行一下整个项目:
然后,我们就能尝试发送一个http请求:

很自然的,我们得到了想要的响应数据,并且也在控制台观察到了预设的输出信息: