ElasticSearch----分布式搜索引擎
ElasticSearch
- ElasticSearch
-
- RESTful
- 全文检索
- Lucene
- ElasticSearch
- ElasticSearch安装
-
- 安装ES服务
- 单节点安装
- HEAD 插件安装
-
- 浏览器插件安装
- 下载插件安装
- 分布式安装
- Kibana 安装
-
- Kibana的基本操作
- curl
- ElasticSearch核心概念介绍
-
- ElasticSearch核心概念
-
- 集群(Cluster)
-
- es6.8
- es7.10
- 节点(Node)
- 索引(Index)
- 类型(Type)
- 文档(Document)
- 分片(Shards)
- 副本(Replicas)
- Settings
- Mapping
- Analyzer
- ElasticSearch Vs 关系型数据库
- ElasticSearch 分词器
-
- 内置分词器
- 中文分词器
-
- 安装
- 测试
- 自定义扩展词库
-
- 本地自定义
- 远程词库
- ElasticSearch管理
-
- 新建索引
-
- 通过 head 插件新建索引
- 通过请求创建
- 更新索引
- 修改索引的读写权限
- 查看索引
- 删除索引
- 索引打开/关闭
- 复制索引
- 索引别名
- ElasticSearch 文档操作
-
- 新建文档
- 获取文档
- 文档更新
-
- 普通更新
- 查询更新
- 删除文档
-
- 根据 id 删除
- 查询删除
- 批量操作
- ElasticSearch文档路由
- ElasticSearch版本控制
-
- 锁
- 版本控制
-
- 内部版本
- 外部版本
- 最新方案(Es6.7 之后)
- ElasticSearch倒排索引
-
- 正排索引
- 倒排索引
- ElasticSearch映射操作
-
- 映射分类
-
- 动态映射
- 静态映射
- 类型推断
- ElasticSearch字段类型
-
- 核心类型
-
- 字符串类型
- 数字类型
- 日期类型
- 布尔类型(boolean)
- 二进制类型(binary)
- 范围类型
- 复合类型
-
- 数组类型
- 对象类型(object)
- 嵌套类型(nested)
- 地理类型
-
- geo_point
- geo_shape
- 特殊类型
-
- IP
- token_count
- ElasticSearch映射参数
-
- analyzer
- search_analyzer
- normalizer
- boost
- coerce
- copy_to
- doc_values 和 fielddata
- dynamic
- enabled
- format
- ignore_above
- ignore_malformed
- include_in_all
- index
- index_options
- norms
- null_value
- position_increment_gap
- properties
- similarity
- store
- term_vectors
- fields
- ElasticSearch 映射模版
- ElasticSearch高级检索(Query)
-
- 索引原理
- Logstash
ElasticSearch
RESTful


全文检索

Lucene
Lucene 是一个开源、免费、高性能、纯 Java 编写的全文检索引擎,可以算作是开源领域最好的全文检索工具包。
在实际开发中,Lucene 几乎适用于任何需要全文检索的场景,所以 Lucene 先后发展出好多语言版本,例如 C++、C#、Python 等。
早在 2005 年,Lucene 就升级为 Apache 顶级开源项目。它的作者是 Doug Cutting,有的人可能没听过这这个人,不过你肯定听过他的另一个大名鼎鼎的作品 Hadoop。
不过需要注意的是,Lucene 只是一个工具包,并非一个完整的搜索引擎,开发者可以基于 Lucene 来开发完整的搜索引擎。比较著名的有 Solr、ElasticSearch,不过在分布式和大数据环境下,ElasticSearch 更胜一筹。
Lucene 主要有如下特点:
- 简单
- 跨语言
- 强大的搜索引擎
- 索引速度快
- 索引文件兼容不同平台
ElasticSearch
ElasticSearch 是一个分布式、可扩展、近实时性的高性能搜索与数据分析引擎。ElasticSearch 基于 Java 编写,通过进一步封装 Lucene,将搜索的复杂性屏蔽起来,开发者只需要一套简单的 RESTful API 就可以操作全文检索。
ElasticSearch 在分布式环境下表现优异,这也是它比较受欢迎的原因之一。它支持 PB 级别的结构化或非结构化海量数据处理

整体上来说,ElasticSearch 有三大功能:
- 数据搜集
- 数据分析
- 数据存储
ElasticSearch 的主要特点:
- 分布式文件存储。
- 实时分析的分布式搜索引擎。
- 高可拓展性。
- 可插拔的插件支持。
ElasticSearch安装
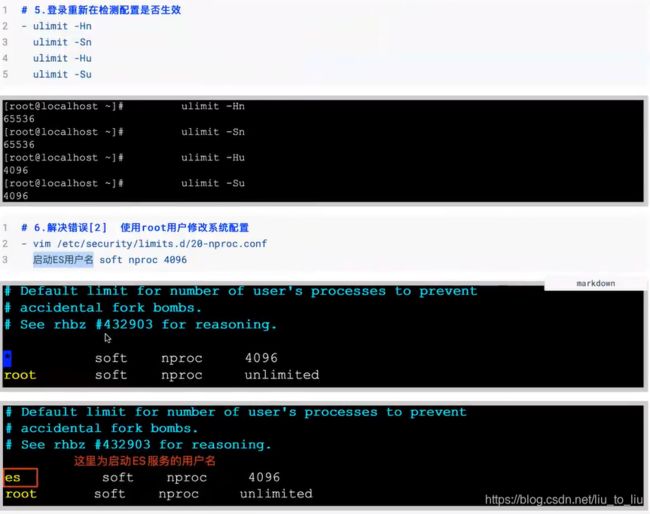
安装ES服务







- /etc/security/limits.conf
* soft nproc 4096
* hard nproc 4096
* soft nofile 65536
* hard nofile 65536

- /etc/sysctl.conf
vm.max_map_count=655360
单节点安装
首先打开 Es 官网,找到 Elasticsearch:
- https://www.elastic.co/cn/elasticsearch/
然后点击下载按钮,选择合适的版本直接下载即可。

将下载的文件解压,解压后的目录含义如下:
| 目录 | 含义 |
|---|---|
| modules | 依赖模块目录 |
| lib | 第三方依赖库 |
| logs | 输出日志目录 |
| plugins | 插件目录 |
| bin | 可执行文件目录 |
| config | 配置文件目录 |
| data | 数据存储目录 |
启动方式:
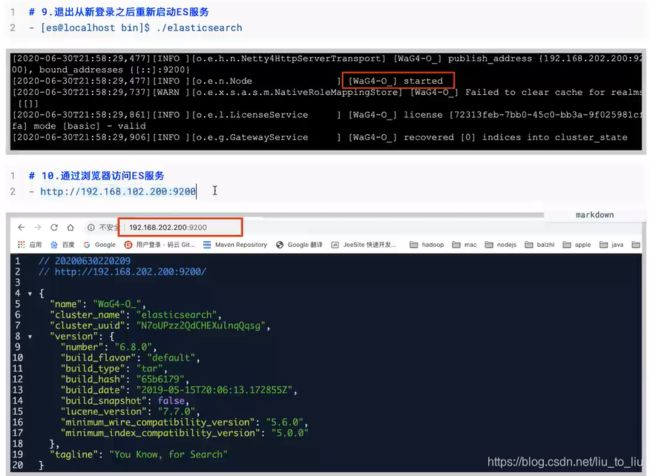
进入到 bin 目录下,直接执行 ./elasticsearch 启动即可。

看到 started 表示启动成功。
默认监听的端口是 9200,所以浏览器直接输入 localhost:9200 可以查看节点信息。

节点的名字以及集群(默认是 elasticsearch)的名字,我们都可以自定义配置。
打开 config/elasticsearch.yml 文件,可以配置集群名称以及节点名称。配置方式如下:
cluster.name: javaboy-es
node.name: master
配置完成后,保存配置文件,并重启 es。重启成功后,刷新浏览器 localhost:9200 页面,就可以看到最新信息。

Es 支持矩阵:
- https://www.elastic.co/cn/support/matrix
HEAD 插件安装
Elasticsearch-head 插件,可以通过可视化的方式查看集群信息。
浏览器插件安装
Chrome 直接在 App Store 搜索 Elasticsearch-head,点击安装即可。

下载插件安装


四个步骤:
git clone git://github.com/mobz/elasticsearch-head.git
cd elasticsearch-head
npm install
npm run start
启动成功,页面如下:

注意,此时看不到集群数据。原因在于这里通过跨域的方式请求集群数据的,默认情况下,集群不支持跨域,所以这里就看不到集群数据。
解决办法如下,修改 es 的 config/elasticsearch.yml 配置文件,添加如下内容,使之支持跨域:
http.cors.enabled: true
http.cors.allow-origin: "*"
配置完成后,重启 es,此时 head 上就有数据了。

分布式安装
- 一主二从
- master 的端口是 9200,slave 端口分别是 9201 和 9202
首先修改 master 的 config/elasticsearch.yml 配置文件:
cluster.name: javaboy-es #(自定义的集群名称)
node.name: master #(自定义的节点名称)
node.master: true #(作为master节点)
network.host: 127.0.0.1 #(主机IP地址)
配置完成后,重启 master。
将 es 的压缩包解压两份,分别命名为 slave01 和 slave02,代表两个从机。
分别对其进行配置。
slave01/config/elasticsearch.yml:
cluster.name: javaboy-es #(自定义的集群名称,同master节点的配置一致)
node.name: slave01 #(自定义的节点名称)
network.host: 127.0.0.1 #(主机IP地址)
http.port: 9201 #(端口号)
discovery.zen.ping.unicast.hosts: ["127.0.0.1"] #(找到master节点)
slave02/config/elasticsearch.yml:
cluster.name: javaboy-es #(自定义的集群名称,同master节点的配置一致)
node.name: slave02 #(自定义的节点名称)
network.host: 127.0.0.1 #(主机IP地址)
http.port: 9202 #(端口号)
discovery.zen.ping.unicast.hosts: ["127.0.0.1"] #(找到master节点)
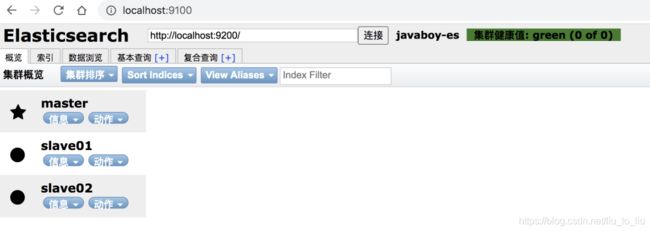
然后分别启动 slave01 和 slave02。启动后,可以在 head 插件上查看集群信息。
Kibana 安装


Kibana 是一个 Elastic 公司推出的一个针对 es 的分析以及数据可视化平台,可以搜索、查看存放在 es 中的数据。
安装步骤如下:
- 下载 Kibana:https://www.elastic.co/cn/downloads/kibana
- 解压
- 配置 es 的地址信息(可选,如果 es 是默认地址以及端口,可以不用配置,具体的配置文件是 config/kibana.yml)
- 执行 ./bin/kibana 文件启动
- localhost:5601

Kibana 安装好之后,首次打开时,可以选择初始化 es 提供的测试数据,也可以不使用。
Kibana的基本操作









curl



ElasticSearch核心概念介绍
ElasticSearch核心概念


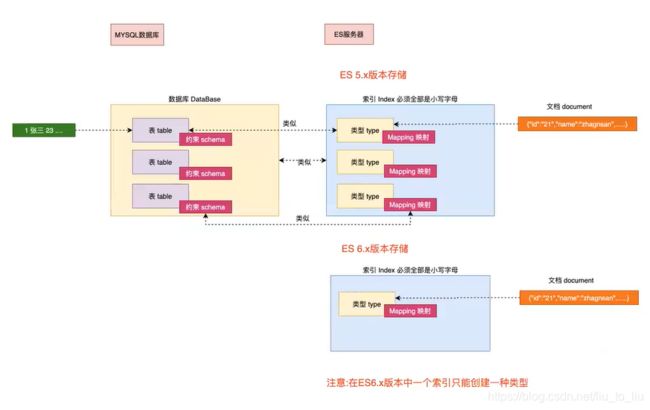
集群(Cluster)
es6.8


es7.10

- es01
cluster.name: el-cluster
node.name: es01
#path.data: /home/es/es01/data
#path.logs: /home/es/es01/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.220.**0","192.168.220.**1","192.168.220.**2"]
cluster.initial_master_nodes: ["192.168.220.**0]
http.cors.enabled: true
http.cors.allow-origin: "*"
- es02
cluster.name: el-cluster
node.name: es02
#path.data: /home/es/es02/data
#path.logs: /home/es/es02/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.220.**0","192.168.220.**1","192.168.220.**2"]
cluster.initial_master_nodes: ["192.168.220.**0]
http.cors.enabled: true
http.cors.allow-origin: "*"
- es03
cluster.name: el-cluster
node.name: es03
#path.data: /home/es/es03/data
#path.logs: /home/es/es03/logs
bootstrap.memory_lock: false
bootstrap.system_call_filter: false
network.host: 0.0.0.0
http.port: 9200
transport.tcp.port: 9300
discovery.seed_hosts: ["192.168.220.**0","192.168.220.**1","192.168.220.**2"]
cluster.initial_master_nodes: ["192.168.220.**0]
http.cors.enabled: true
http.cors.allow-origin: "*"
一个或者多个安装了 es 节点的服务器组织在一起,就是集群,这些节点共同持有数据,共同提供搜索服务。
一个集群有一个名字,这个名字是集群的唯一标识,该名字成为 cluster name,默认的集群名称是 elasticsearch,具有相同名称的节点才会组成一个集群。
可以在 config/elasticsearch.yml 文件中配置集群名称:
cluster.name: javaboy-es
在集群中,节点的状态有三种:绿色、黄色、红色:
- 绿色:节点运行状态为健康状态。所有的主分片、副本分片都可以正常工作。
- 黄色:表示节点的运行状态为警告状态,所有的主分片目前都可以直接运行,但是至少有一个副本分片是不能正常工作的。
- 红色:表示集群无法正常工作。
节点(Node)
集群中的一个服务器就是一个节点,节点中会存储数据,同时参与集群的索引以及搜索功能。一个节点想要加入一个集群,只需要配置一下集群名称即可。默认情况下,如果我们启动了多个节点,多个节点还能够互相发现彼此,那么它们会自动组成一个集群,这是 es 默认提供的,但是这种方式并不可靠,有可能会发生脑裂现象。所以在实际使用中,建议一定手动配置一下集群信息。
索引(Index)
索引可以从两方面来理解:
名词
具有相似特征文档的集合。
动词
索引数据以及对数据进行索引操作。
类型(Type)
类型是索引上的逻辑分类或者分区。在 es6 之前,一个索引中可以有多个类型,从 es7 开始,一个索引中,只能有一个类型。在 es6.x 中,依然保持了兼容,依然支持单 index 多个 type 结构,但是已经不建议这么使用。
文档(Document)
一个可以被索引的数据单元。例如一个用户的文档、一个产品的文档等等。文档都是 JSON 格式的。
分片(Shards)
索引都是存储在节点上的,但是受限于节点的空间大小以及数据处理能力,单个节点的处理效果可能不理想,此时我们可以对索引进行分片。当我们创建一个索引的时候,就需要指定分片的数量。每个分片本身也是一个功能完善并且独立的索引。
默认情况下,一个索引会自动创建 1 个分片,并且为每一个分片创建一个副本。
副本(Replicas)
副本也就是备份,是对主分片的一个备份。
Settings
集群中对索引的定义信息,例如索引的分片数、副本数等等。
Mapping
Mapping 保存了定义索引字段的存储类型、分词方式、是否存储等信息。
Analyzer
字段分词方式的定义。
ElasticSearch Vs 关系型数据库
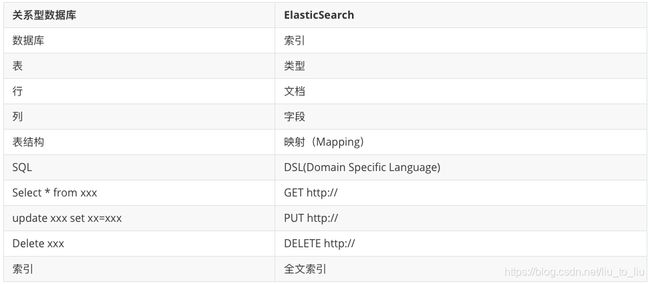
ElasticSearch 分词器
内置分词器
ElasticSearch 核心功能就是数据检索,首先通过索引将文档写入 es。查询分析则主要分为两个步骤:
- 词条化:分词器将输入的文本转为一个一个的词条流。
- 过滤:比如停用词过滤器会从词条中去除不相干的词条(的,嗯,啊,呢);另外还有同义词过滤器、小写过滤器等。
ElasticSearch 中内置了多种分词器可以供使用。
内置分词器:

中文分词器

![]()
![]()


在 Es 中,使用较多的中文分词器是 elasticsearch-analysis-ik,这个是 es 的一个第三方插件,代码托管在 GitHub 上:
- https://github.com/medcl/elasticsearch-analysis-ik
安装
两种使用方式:
第一种:
- 首先打开分词器官网:https://github.com/medcl/elasticsearch-analysis-ik。
- 在 https://github.com/medcl/elasticsearch-analysis-ik/releases 页面找到最新的正式版,下载下来。我们这里的下载链接是 https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip。
- 将下载文件解压。
- 在 es/plugins 目录下,新建 ik 目录,并将解压后的所有文件拷贝到 ik 目录下。
- 重启 es 服务。
第二种:
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.9.3/elasticsearch-analysis-ik-7.9.3.zip
测试
es 重启成功后,首先创建一个名为 test 的索引:

接下来,在该索引中进行分词测试:
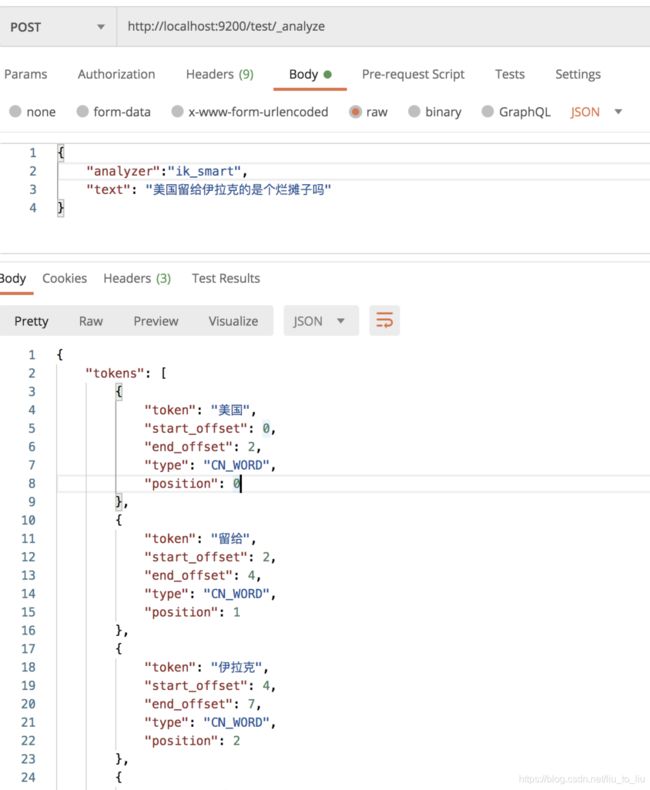
自定义扩展词库
本地自定义
在 es/plugins/ik/config 目录下,新建 ext.dic 文件(文件名任意),在该文件中可以配置自定义的词库。

如果有多个词,换行写入新词即可。
然后在 es/plugins/ik/config/IKAnalyzer.cfg.xml 中配置扩展词典的位置:
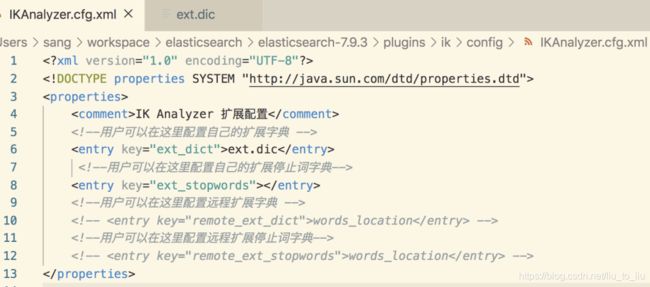
远程词库
也可以配置远程词库,远程词库支持热更新(不用重启 es 就可以生效)。
热更新只需要提供一个接口,接口返回扩展词即可。
具体使用方式如下,新建一个 Spring Boot 项目,引入 Web 依赖即可。然后在 resources/stastic 目录下新建 ext.dic 文件,写入扩展词:
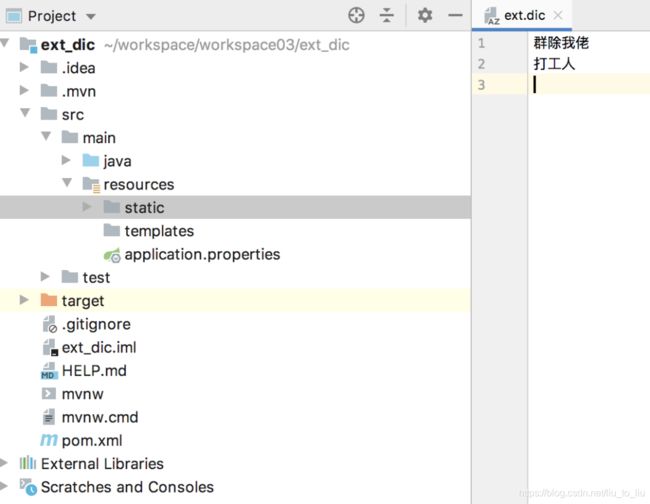
接下来,在 es/plugins/ik/config/IKAnalyzer.cfg.xml 文件中配置远程扩展词接口:
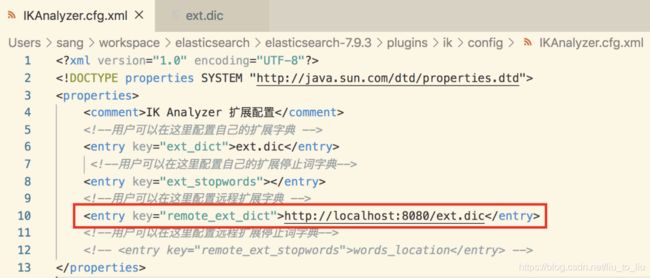
配置完成后,重启 es ,即可生效。
热更新,主要是响应头的 Last-Modified 或者 ETag 字段发生变化,ik 就会自动重新加载远程扩展
ElasticSearch管理
新建索引
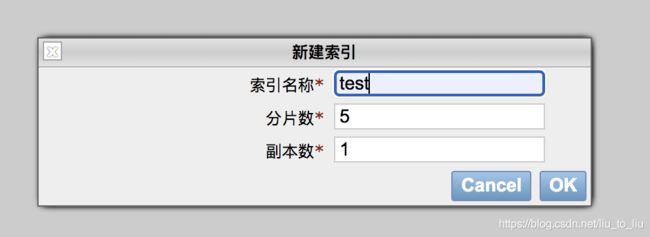
通过 head 插件新建索引
在 head 插件中,选择 索引选项卡,然后点击新建索引。新建索引时,需要填入索引名称、分片数以及副本数。
索引创建成功后,如下图:

0、1、2、3、4 分别表示索引的分片,粗框表示主分片,细框表示副本(点一下框,通过 primary 属性可以查看是主分片还是副本)。.kibana 索引只有一个分片和一个副本,所以只有 0。
通过请求创建
可以通过 postman 发送请求,也可以通过 kibana 发送请求,由于 kibana 有提示,所以这里采用 kibana。
创建索引请求:
PUT book
创建成功后,可以查看索引信息:
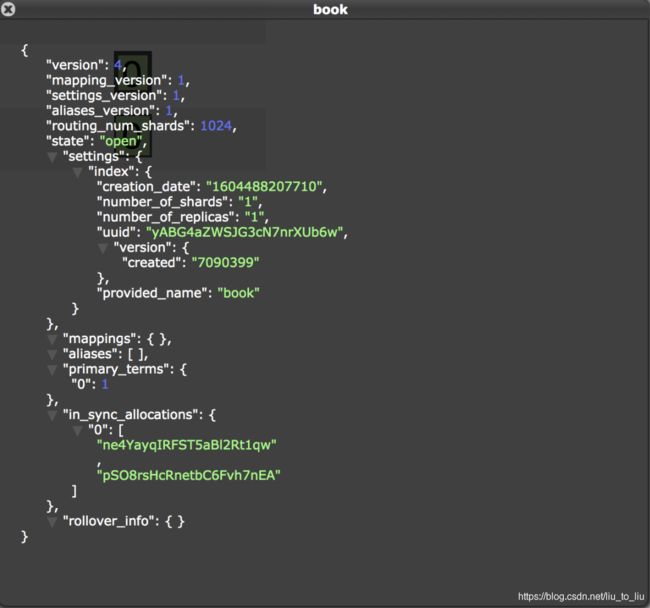
需要注意两点:
-
索引名称不能有大写字母

-
索引名是唯一的,不能重复,重复创建会出错

更新索引
索引创建好之后,可以修改其属性。
例如修改索引的副本数:
PUT book/_settings
{
"number_of_replicas": 2
}
修改成功后,如下:

更新分片数也是一样。
修改索引的读写权限
索引创建成功后,可以向索引中写入文档:
PUT book/_doc/1
{
"title":"三国演义"
}
写入成功后,可以在 head 插件中查看:
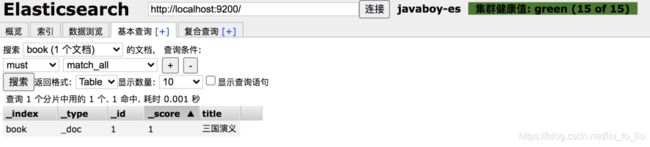
默认情况下,索引是具备读写权限的,当然这个读写权限可以关闭。
例如,关闭索引的写权限:
PUT book/_settings
{
"blocks.write": true
}
关闭之后,就无法添加文档了。关闭了写权限之后,如果想要再次打开,方式如下:
PUT book/_settings
{
"blocks.write": false
}
其他类似的权限有:
- blocks.write
- blocks.read
- blocks.read_only
查看索引
head 插件查看方式如下:
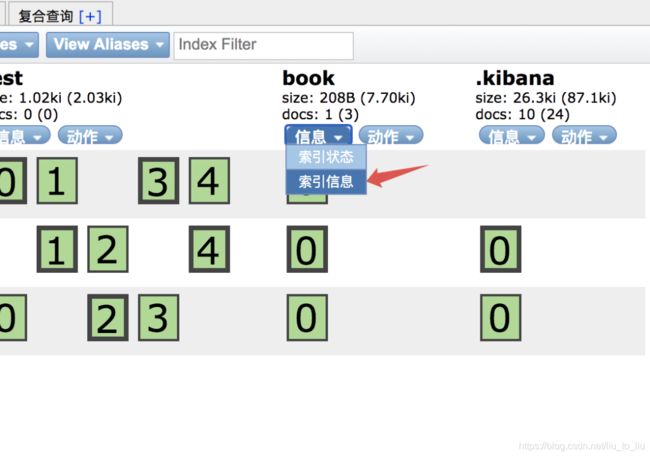
请求查看方式如下:
GET book/_settings
也可以同时查看多个索引信息:
GET book,test/_settings
也可以查看所有索引信息:
GET _all/_settings
删除索引
head 插件可以删除索引:

请求删除如下:
DELETE test
删除一个不存在的索引会报错。
索引打开/关闭
关闭索引:
POST book/_close
打开索引:
POST book/_open
当然,可以同时关闭/打开多个索引,多个索引用 , 隔开,或者直接使用 _all 代表所有索引。
复制索引
索引复制,只会复制数据,不会复制索引配置。
POST _reindex
{
"source": {"index":"book"},
"dest": {"index":"book_new"}
}
复制的时候,可以添加查询条件。
索引别名
可以为索引创建别名,如果这个别名是唯一的,该别名可以代替索引名称。
POST /_aliases
{
"actions": [
{
"add": {
"index": "book",
"alias": "book_alias"
}
}
]
}
添加结果如下:
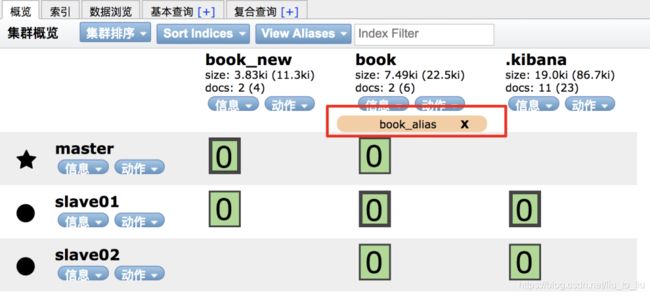
将 add 改为 remove 就表示移除别名:
POST /_aliases
{
"actions": [
{
"remove": {
"index": "book",
"alias": "book_alias"
}
}
]
}
查看某一个索引的别名:
GET /book/_alias
查看某一个别名对应的索引(book_alias 表示一个别名):
GET /book_alias/_alias
可以查看集群上所有可用别名:
GET /_alias
ElasticSearch 文档操作
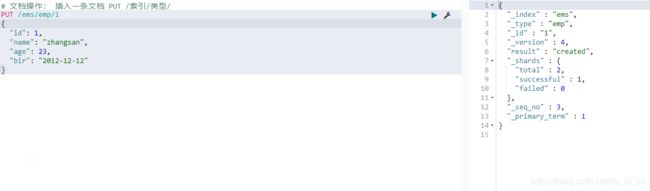
新建文档
首先新建一个索引。
然后向索引中添加一个文档:
PUT blog/_doc/1
{
"title":"6. ElasticSearch 文档基本操作",
"date":"2020-11-05",
"content":"微信公众号**江南一点雨**后台回复 **elasticsearch06** 下载本笔记。首先新建一个索引。"
}
1 表示新建文档的 id。
添加成功后,响应的 json 如下:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"_seq_no" : 0,
"_primary_term" : 1
}
- _index 表示文档索引。
- _type 表示文档的类型。
- _id 表示文档的 id。
- _version 表示文档的版本(更新文档,版本会自动加 1,针对一个文档的)。
- result 表示执行结果。
- _shards 表示分片信息。
- _seq_no 和 _primary_term 这两个也是版本控制用的(针对当前 index)。
添加成功后,可以查看添加的文档:

当然,添加文档时,也可以不指定 id,此时系统会默认给出一个 id,如果不指定 id,则需要使用 POST 请求,而不能使用 PUT 请求。
POST blog/_doc
{
"title":"666",
"date":"2020-11-05",
"content":"微信公众号**江南一点雨**后台回复 **elasticsearch06** 下载本笔记。首先新建一个索引。"
}
获取文档
Es 中提供了 GET API 来查看存储在 es 中的文档。使用方式如下:
GET blog/_doc/RuWrl3UByGJWB5WucKtP
上面这个命令表示获取一个 id 为 RuWrl3UByGJWB5WucKtP 的文档。
如果获取不存在的文档,会返回如下信息:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "2",
"found" : false
}
如果仅仅只是想探测某一个文档是否存在,可以使用 head 请求:
如果文档不存在,响应如下:
![]()
如果文档存在,响应如下:

当然也可以批量获取文档。
GET blog/_mget
{
"ids":["1","RuWrl3UByGJWB5WucKtP"]
}
这里可能有小伙伴有疑问,GET 请求竟然可以携带请求体?
某些特定的语言,例如 JavaScript 的 HTTP 请求库是不允许 GET 请求有请求体的,实际上在 RFC7231 文档中,并没有规定 GET 请求的请求体该如何处理,这样造成了一定程度的混乱,有的 HTTP 服务器支持 GET 请求携带请求体,有的 HTTP 服务器则不支持。虽然 es 工程师倾向于使用 GET 做查询,但是为了保证兼容性,es 同时也支持使用 POST 查询。例如上面的批量查询案例,也可以使用 POST 请求。
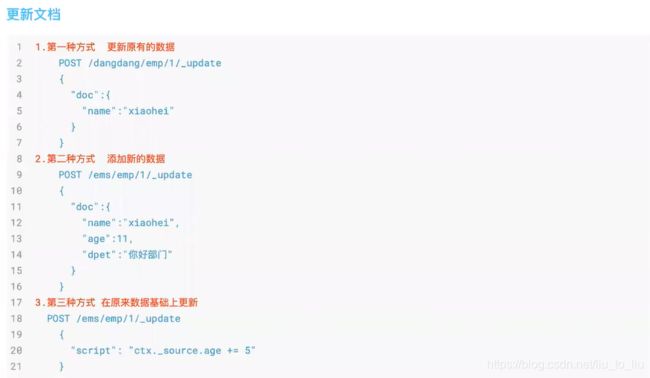
文档更新
普通更新
注意,文档更新一次,version 就会自增 1。
可以直接更新整个文档:
PUT blog/_doc/RuWrl3UByGJWB5WucKtP
{
"title":"666"
}
这种方式,更新的文档会覆盖掉原文档。
大多数时候,我们只是想更新文档字段,这个可以通过脚本来实现。
POST blog/_update/1
{
"script": {
"lang": "painless",
"source":"ctx._source.title=params.title",
"params": {
"title":"666666"
}
}
}
更新的请求格式:POST {index}/_update/{id}
在脚本中,lang 表示脚本语言,painless 是 es 内置的一种脚本语言。source 表示具体执行的脚本,ctx 是一个上下文对象,通过 ctx 可以访问到 _source、_title 等。
也可以向文档中添加字段:
POST blog/_update/1
{
"script": {
"lang": "painless",
"source":"ctx._source.tags=[\"java\",\"php\"]"
}
}
添加成功后的文档如下:

通过脚本语言,也可以修改数组。例如再增加一个 tag:
POST blog/_update/1
{
"script":{
"lang": "painless",
"source":"ctx._source.tags.add(\"js\")"
}
}
当然,也可以使用 if else 构造稍微复杂一点的逻辑。
POST blog/_update/1
{
"script": {
"lang": "painless",
"source": "if (ctx._source.tags.contains(\"java\")){ctx.op=\"delete\"}else{ctx.op=\"none\"}"
}
}
查询更新
通过条件查询找到文档,然后再去更新。
例如将 title 中包含 666 的文档的 content 修改为 888。
POST blog/_update_by_query
{
"script": {
"source": "ctx._source.content=\"888\"",
"lang": "painless"
},
"query": {
"term": {
"title":"666"
}
}
}
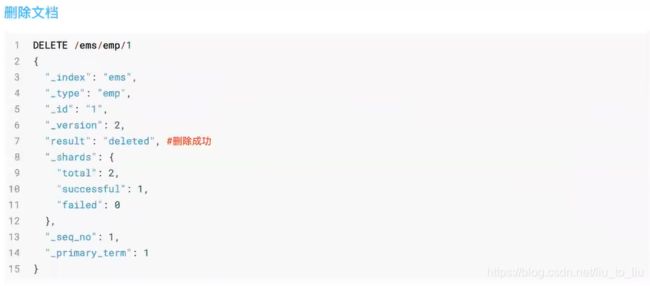
删除文档
根据 id 删除
从索引中删除一个文档。
删除一个 id 为 TuUpmHUByGJWB5WuMasV 的文档。
DELETE blog/_doc/TuUpmHUByGJWB5WuMasV
如果在添加文档时指定了路由,则删除文档时也需要指定路由,否则删除失败。
查询删除
查询删除是 POST 请求。
例如删除 title 中包含 666 的文档:
POST blog/_delete_by_query
{
"query":{
"term":{
"title":"666"
}
}
}
也可以删除某一个索引下的所有文档:
POST blog/_delete_by_query
{
"query":{
"match_all":{
}
}
}
批量操作
es 中通过 Bulk API 可以执行批量索引、批量删除、批量更新等操作。
首先需要将所有的批量操作写入一个 JSON 文件中,然后通过 POST 请求将该 JSON 文件上传并执行。
例如新建一个名为 aaa.json 的文件,内容如下:
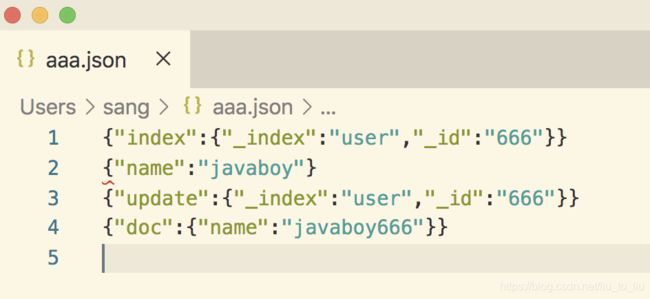
首先第一行:index 表示要执行一个索引操作(这个表示一个 action,其他的 action 还有 create,delete,update)。_index 定义了索引名称,这里表示要创建一个名为 user 的索引,_id 表示新建文档的 id 为 666。
第二行是第一行操作的参数。
第三行的 update 则表示要更新。
第四行是第三行的参数。
注意,结尾要空出一行。
aaa.json 文件创建成功后,在该目录下,执行请求命令,如下:
curl -XPOST "http://localhost:9200/user/_bulk" -H "content-type:application/json" --data-binary @aaa.json
执行完成后,就会创建一个名为 user 的索引,同时向该索引中添加一条记录,再修改该记录,最终结果如下:

ElasticSearch文档路由
es 是一个分布式系统,当我们存储一个文档到 es 上之后,这个文档实际上是被存储到 master 节点中的某一个主分片上。
例如新建一个索引,该索引有两个分片,0个副本,如下:

接下来,向该索引中保存一个文档:
PUT blog/_doc/a
{
"title":"a"
}
文档保存成功后,可以查看该文档被保存到哪个分片中去了:
GET _cat/shards/blog?v
查看结果如下:
index shard prirep state docs store ip node
blog 1 p STARTED 0 208b 127.0.0.1 slave01
blog 0 p STARTED 1 3.6kb 127.0.0.1 master
从这个结果中,可以看出,文档被保存到分片 0 中。
那么 es 中到底是按照什么样的规则去分配分片的?
es 中的路由机制是通过哈希算法,将具有相同哈希值的文档放到一个主分片中,分片位置的计算方式如下:
shard=hash(routing) % number_of_primary_shards
routing 可以是一个任意字符串,es 默认是将文档的 id 作为 routing 值,通过哈希函数根据 routing 生成一个数字,然后将该数字和分片数取余,取余的结果就是分片的位置。
默认的这种路由模式,最大的优势在于负载均衡,这种方式可以保证数据平均分配在不同的分片上。但是他有一个很大的劣势,就是查询时候无法确定文档的位置,此时它会将请求广播到所有的分片上去执行。另一方面,使用默认的路由模式,后期修改分片数量不方便。
当然开发者也可以自定义 routing 的值,方式如下:
PUT blog/_doc/d?routing=javaboy
{
"title":"d"
}
如果文档在添加时指定了 routing,则查询、删除、更新时也需要指定 routing。
GET blog/_doc/d?routing=javaboy
自定义 routing 有可能会导致负载不均衡,这个还是要结合实际情况选择。
典型场景:
对于用户数据,我们可以将 userid 作为 routing,这样就能保证同一个用户的数据保存在同一个分片中,检索时,同样使用 userid 作为 routing,这样就可以精准的从某一个分片中获取数据。
ElasticSearch版本控制
当我们使用 es 的 API 去进行文档更新时,它首先读取原文档出来,然后对原文档进行更新,更新完成后再重新索引整个文档。不论你执行多少次更新,最终保存在 es 中的是最后一次更新的文档。但是如果有两个线程同时去更新,就有可能出问题。
要解决问题,就是锁。
锁
悲观锁
很悲观,每一次去读取数据的时候,都认为别人可能会修改数据,所以屏蔽一切可能破坏数据完整性的操作。关系型数据库中,悲观锁使用较多,例如行锁、表锁等等。
乐观锁
很乐观,每次读取数据时,都认为别人不会修改数据,因此也不锁定数据,只有在提交数据时,才会检查数据完整性。这种方式可以省去锁的开销,进而提高吞吐量。
在 es 中,实际上使用的就是乐观锁。
版本控制
es6.7之前
在 es6.7 之前,使用 version+version_type 来进行乐观并发控制。根据前面的介绍,文档每被修改一个,version 就会自增一次,es 通过 version 字段来确保所有的操作都有序进行。
version 分为内部版本控制和外部版本控制。
内部版本
es 自己维护的就是内部版本,当创建一个文档时,es 会给文档的版本赋值为 1。
每当用户修改一次文档,版本号就回自增 1。
如果使用内部版本,es 要求 version 参数的值必须和 es 文档中 version 的值相当,才能操作成功。
外部版本
也可以维护外部版本。
在添加文档时,就指定版本号:
PUT blog/_doc/1?version=200&version_type=external
{
"title":"2222"
}
以后更新的时候,版本要大于已有的版本号。
- vertion_type=external 或者 vertion_type=external_gt 表示以后更新的时候,版本要大于已有的版本号。
- vertion_type=external_gte 表示以后更新的时候,版本要大于等于已有的版本号。
最新方案(Es6.7 之后)
现在使用 if_seq_no 和 if_primary_term 两个参数来做并发控制。
seq_no 不属于某一个文档,它是属于整个索引的(version 则是属于某一个文档的,每个文档的 version 互不影响)。现在更新文档时,使用 seq_no 来做并发。由于 seq_no 是属于整个 index 的,所以任何文档的修改或者新增,seq_no 都会自增。
现在就可以通过 seq_no 和 primary_term 来做乐观并发控制。
PUT blog/_doc/2?if_seq_no=5&if_primary_term=1
{
"title":"6666"
}
ElasticSearch倒排索引
倒排索引是 es 中非常重要的索引结构,是从文档词项到文档 ID 的一个映射过程。
正排索引
我们在关系型数据库中见到的索引,就是“正排索引”。
关系型数据库中的索引如下,假设我有一个博客表:

我们可以针对这个表建立索引(正排索引):
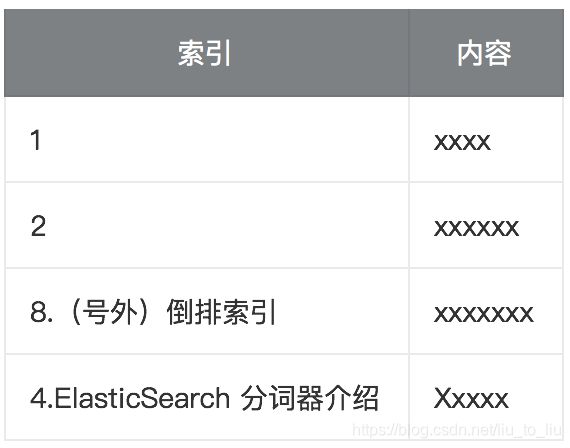
当我们通过 id 或者标题去搜索文章时,就可以快速搜到。
但是如果我们按照文章内容的关键字去搜索,就只能去内容中做字符匹配了。为了提高查询效率,就要考虑使用倒排索引。
倒排索引
倒排索引就是以内容的关键字建立索引,通过索引找到文档 id,再进而找到整个文档。

一般来说,倒排索引分为两个部分:
- 单词词典(记录所有的文档词项,以及词项到倒排列表的关联关系)
- 倒排列表(记录单词与对应的关系,由一系列倒排索引项组成,倒排索引项指:文档 id、词频(TF)(词项在文档中出现的次数,评分时使用)、位置(Position,词项在文档中分词的位置)、偏移(记录词项开始和结束的位置))
当我们去索引一个文档时,就回建立倒排索引,搜索时,直接根据倒排索引搜索。
ElasticSearch映射操作
映射就是 Mapping,它用来定义一个文档以及文档所包含的字段该如何被存储和索引。所以,它其实有点类似于关系型数据库中表的定义。
映射分类
动态映射
顾名思义,就是自动创建出来的映射。es 根据存入的文档,自动分析出来文档中字段的类型以及存储方式,这种就是动态映射。
举一个简单例子,新建一个索引,然后查看索引信息:
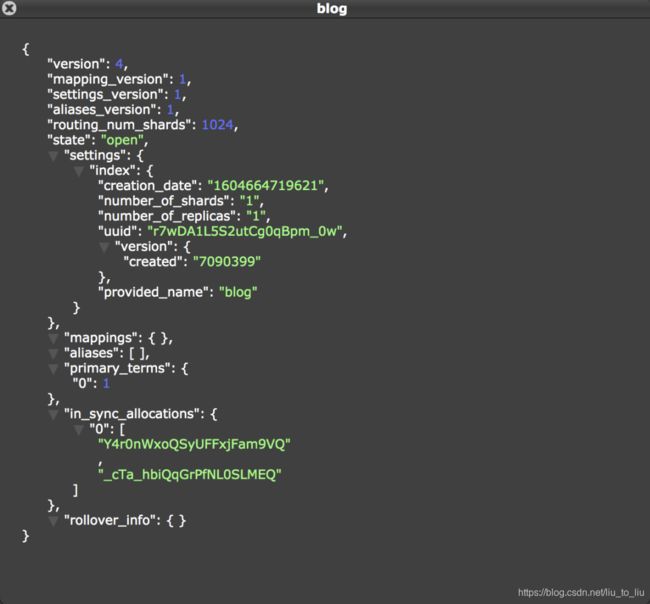
在创建好的索引信息中,可以看到,mappings 为空,这个 mappings 中保存的就是映射信息。
现在我们向索引中添加一个文档,如下:
PUT blog/_doc/1
{
"title":"1111",
"date":"2020-11-11"
}
文档添加成功后,就会自动生成 Mappings:

可以看到,date 字段的类型为 date,title 的类型有两个,text 和 keyword。
默认情况下,文档中如果新增了字段,mappings 中也会自动新增进来。
有的时候,如果希望新增字段时,能够抛出异常来提醒开发者,这个可以通过 mappings 中 dynamic 属性来配置。
dynamic 属性有三种取值:
- true,默认即此。自动添加新字段。
- false,忽略新字段。
- strict,严格模式,发现新字段会抛出异常。
具体配置方式如下,创建索引时指定 mappings(这其实就是静态映射):
PUT blog
{
"mappings": {
"dynamic":"strict",
"properties": {
"title":{
"type": "text"
},
"age":{
"type":"long"
}
}
}
}
然后向 blog 中索引中添加数据:
PUT blog/_doc/2
{
"title":"1111",
"date":"2020-11-11",
"age":99
}
在添加的文档中,多出了一个 date 字段,而该字段没有预定义,所以这个添加操作就回报错:
{
"error" : {
"root_cause" : [
{
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [date] within [_doc] is not allowed"
}
],
"type" : "strict_dynamic_mapping_exception",
"reason" : "mapping set to strict, dynamic introduction of [date] within [_doc] is not allowed"
},
"status" : 400
}
动态映射还有一个日期检测的问题。
例如新建一个索引,然后添加一个含有日期的文档,如下:
PUT blog/_doc/1
{
"remark":"2020-11-11"
}
添加成功后,remark 字段会被推断是一个日期类型。

此时,remark 字段就无法存储其他类型了。
PUT blog/_doc/1
{
"remark":"javaboy"
}
此时报错如下:
{
"error" : {
"root_cause" : [
{
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [remark] of type [date] in document with id '1'. Preview of field's value: 'javaboy'"
}
],
"type" : "mapper_parsing_exception",
"reason" : "failed to parse field [remark] of type [date] in document with id '1'. Preview of field's value: 'javaboy'",
"caused_by" : {
"type" : "illegal_argument_exception",
"reason" : "failed to parse date field [javaboy] with format [strict_date_optional_time||epoch_millis]",
"caused_by" : {
"type" : "date_time_parse_exception",
"reason" : "Failed to parse with all enclosed parsers"
}
}
},
"status" : 400
}
要解决这个问题,可以使用静态映射,即在索引定义时,将 remark 指定为 text 类型。也可以关闭日期检测。
PUT blog
{
"mappings": {
"date_detection": false
}
}
此时日期类型就回当成文本来处理。
静态映射
略。
类型推断
es 中动态映射类型推断方式如下:

ElasticSearch字段类型
核心类型
字符串类型
- string:这是一个已经过期的字符串类型。在 es5 之前,用这个来描述字符串,现在的话,它已经被 text 和 keyword 替代了。
- text:如果一个字段是要被全文检索的,比如说博客内容、新闻内容、产品描述,那么可以使用 text。用了 text 之后,字段内容会被分析,在生成倒排索引之前,字符串会被分词器分成一个个词项。text 类型的字段不用于排序,很少用于聚合。这种字符串也被称为 analyzed 字段。
- keyword:这种类型适用于结构化的字段,例如标签、email 地址、手机号码等等,这种类型的字段可以用作过滤、排序、聚合等。这种字符串也称之为 not-analyzed 字段。
数字类型

- 在满足需求的情况下,优先使用范围小的字段。字段长度越短,索引和搜索的效率越高。
- 浮点数,优先考虑使用 scaled_float。
scaled_float 举例:
PUT product
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"price":{
"type": "scaled_float",
"scaling_factor": 100
}
}
}
}
日期类型
由于 JSON 中没有日期类型,所以 es 中的日期类型形式就比较多样:
- 2020-11-11 或者 2020-11-11 11:11:11
- 一个从 1970.1.1 零点到现在的一个秒数或者毫秒数。
es 内部将时间转为 UTC,然后将时间按照 millseconds-since-the-epoch 的长整型来存储。
自定义日期类型:
PUT product
{
"mappings": {
"properties": {
"date":{
"type": "date"
}
}
}
}
这个能够解析出来的时间格式比较多。
PUT product/_doc/1
{
"date":"2020-11-11"
}
PUT product/_doc/2
{
"date":"2020-11-11T11:11:11Z"
}
PUT product/_doc/3
{
"date":"1604672099958"
}
上面三个文档中的日期都可以被解析,内部存储的是毫秒计时的长整型数。
布尔类型(boolean)
JSON 中的 “true”、“false”、true、false 都可以。
二进制类型(binary)
二进制接受的是 base64 编码的字符串,默认不存储,也不可搜索。
范围类型
- integer_range
- float_range
- long_range
- double_range
- date_range
- ip_range
定义的时候,指定范围类型即可:
PUT product
{
"mappings": {
"properties": {
"date":{
"type": "date"
},
"price":{
"type":"float_range"
}
}
}
}
插入文档的时候,需要指定范围的界限:
PUT product
{
"mappings": {
"properties": {
"date":{
"type": "date"
},
"price":{
"type":"float_range"
}
}
}
}
指定范围的时,可以使用 gt、gte、lt、lte。
复合类型
数组类型
es 中没有专门的数组类型。默认情况下,任何字段都可以有一个或者多个值。需要注意的是,数组中的元素必须是同一种类型。
添加数组是,数组中的第一个元素决定了整个数组的类型。
对象类型(object)
由于 JSON 本身具有层级关系,所以文档包含内部对象。内部对象中,还可以再包含内部对象。
PUT product/_doc/2
{
"date":"2020-11-11T11:11:11Z",
"ext_info":{
"address":"China"
}
}
嵌套类型(nested)
nested 是 object 中的一个特例。
如果使用 object 类型,假如有如下一个文档:
{
"user":[
{
"first":"Zhang",
"last":"san"
},
{
"first":"Li",
"last":"si"
}
]
}
由于 Lucene 没有内部对象的概念,所以 es 会将对象层次扁平化,将一个对象转为字段名和值构成的简单列表。即上面的文档,最终存储形式如下:
{
"user.first":["Zhang","Li"],
"user.last":["san","si"]
}
扁平化之后,用户名之间的关系没了。这样会导致如果搜索 Zhang si 这个人,会搜索到。
此时可以 nested 类型来解决问题,nested 对象类型可以保持数组中每个对象的独立性。nested 类型将数组中的每一饿对象作为独立隐藏文档来索引,这样每一个嵌套对象都可以独立被索引。
{
{
"user.first":"Zhang",
"user.last":"san"
},{
"user.first":"Li",
"user.last":"si"
}
}
优点
文档存储在一起,读取性能高。
缺点
更新父或者子文档时需要更新更个文档。
地理类型
使用场景:
- 查找某一个范围内的地理位置
- 通过地理位置或者相对中心点的距离来聚合文档
- 把距离整个到文档的评分中
- 通过距离对文档进行排序
geo_point
geo_point 就是一个坐标点,定义方式如下:
PUT people
{
"mappings": {
"properties": {
"location":{
"type": "geo_point"
}
}
}
}
创建时指定字段类型,存储的时候,有四种方式:
PUT people/_doc/1
{
"location":{
"lat": 34.27,
"lon": 108.94
}
}
PUT people/_doc/2
{
"location":"34.27,108.94"
}
PUT people/_doc/3
{
"location":"uzbrgzfxuzup"
}
PUT people/_doc/4
{
"location":[108.94,34.27]
}
注意,使用数组描述,先经度后纬度。
地址位置转 geo_hash:http://www.csxgame.top/#/
geo_shape

指定 geo_shape 类型:
PUT people
{
"mappings": {
"properties": {
"location":{
"type": "geo_shape"
}
}
}
}
添加文档时需要指定具体的类型:
PUT people/_doc/1
{
"location":{
"type":"point",
"coordinates": [108.94,34.27]
}
}
如果是 linestring,如下:
PUT people/_doc/2
{
"location":{
"type":"linestring",
"coordinates": [[108.94,34.27],[100,33]]
}
}
特殊类型
IP
存储 IP 地址,类型是 ip:
PUT blog
{
"mappings": {
"properties": {
"address":{
"type": "ip"
}
}
}
}
添加文档:
PUT blog/_doc/1
{
"address":"192.168.91.1"
}
搜索文档:
GET blog/_search
{
"query": {
"term": {
"address": "192.168.0.0/16"
}
}
}
token_count
用于统计字符串分词后的词项个数。
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"length":{
"type":"token_count",
"analyzer":"standard"
}
}
}
}
}
}
相当于新增了 title.length 字段用来统计分词后词项的个数。
添加文档:
PUT blog/_doc/1
{
"title":"zhang san"
}
可以通过 token_count 去查询:
GET blog/_search
{
"query": {
"term": {
"title.length": 2
}
}
}
ElasticSearch映射参数
analyzer
定义文本字段的分词器。默认对索引和查询都是有效的。
假设不用分词器,我们先来看一下索引的结果,创建一个索引并添加一个文档:
PUT blog
PUT blog/_doc/1
{
"title":"定义文本字段的分词器。默认对索引和查询都是有效的。"
}
查看词条向量(term vectors)
GET blog/_termvectors/1
{
"fields": ["title"]
}
查看结果如下:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 0,
"term_vectors" : {
"title" : {
"field_statistics" : {
"sum_doc_freq" : 22,
"doc_count" : 1,
"sum_ttf" : 23
},
"terms" : {
"义" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 1,
"end_offset" : 2
}
]
},
"分" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 7,
"start_offset" : 7,
"end_offset" : 8
}
]
},
"和" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 15,
"start_offset" : 16,
"end_offset" : 17
}
]
},
"器" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 9,
"start_offset" : 9,
"end_offset" : 10
}
]
},
"字" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 4,
"end_offset" : 5
}
]
},
"定" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 1
}
]
},
"对" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 12,
"start_offset" : 13,
"end_offset" : 14
}
]
},
"引" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 14,
"start_offset" : 15,
"end_offset" : 16
}
]
},
"效" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 21,
"start_offset" : 22,
"end_offset" : 23
}
]
},
"文" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 2,
"end_offset" : 3
}
]
},
"是" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 19,
"start_offset" : 20,
"end_offset" : 21
}
]
},
"有" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 20,
"start_offset" : 21,
"end_offset" : 22
}
]
},
"本" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 3,
"start_offset" : 3,
"end_offset" : 4
}
]
},
"查" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 16,
"start_offset" : 17,
"end_offset" : 18
}
]
},
"段" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 5,
"end_offset" : 6
}
]
},
"的" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 6,
"start_offset" : 6,
"end_offset" : 7
},
{
"position" : 22,
"start_offset" : 23,
"end_offset" : 24
}
]
},
"索" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 13,
"start_offset" : 14,
"end_offset" : 15
}
]
},
"认" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 11,
"start_offset" : 12,
"end_offset" : 13
}
]
},
"词" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 8,
"start_offset" : 8,
"end_offset" : 9
}
]
},
"询" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 17,
"start_offset" : 18,
"end_offset" : 19
}
]
},
"都" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 18,
"start_offset" : 19,
"end_offset" : 20
}
]
},
"默" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 10,
"start_offset" : 11,
"end_offset" : 12
}
]
}
}
}
}
}
可以看到,默认情况下,中文就是一个字一个字的分,这种分词方式没有任何意义。如果这样分词,查询就只能按照一个字一个字来查,像下面这样:
GET blog/_search
{
"query": {
"term": {
"title": "定"
}
}
}
无意义!!!
所以,我们要根据实际情况,配置合适的分词器。
给字段设定分词器:
PUT blog
{
"mappings": {
"properties": {
"title":{
"type":"text",
"analyzer": "ik_smart"
}
}
}
}
存储文档:
PUT blog/_doc/1
{
"title":"定义文本字段的分词器。默认对索引和查询都是有效的。"
}
查看词条向量:
GET blog/_termvectors/1
{
"fields": ["title"]
}
查询结果如下:
{
"_index" : "blog",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"found" : true,
"took" : 1,
"term_vectors" : {
"title" : {
"field_statistics" : {
"sum_doc_freq" : 12,
"doc_count" : 1,
"sum_ttf" : 13
},
"terms" : {
"分词器" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 4,
"start_offset" : 7,
"end_offset" : 10
}
]
},
"和" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 8,
"start_offset" : 16,
"end_offset" : 17
}
]
},
"字段" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 2,
"start_offset" : 4,
"end_offset" : 6
}
]
},
"定义" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 0,
"start_offset" : 0,
"end_offset" : 2
}
]
},
"对" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 6,
"start_offset" : 13,
"end_offset" : 14
}
]
},
"文本" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 1,
"start_offset" : 2,
"end_offset" : 4
}
]
},
"有效" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 11,
"start_offset" : 21,
"end_offset" : 23
}
]
},
"查询" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 9,
"start_offset" : 17,
"end_offset" : 19
}
]
},
"的" : {
"term_freq" : 2,
"tokens" : [
{
"position" : 3,
"start_offset" : 6,
"end_offset" : 7
},
{
"position" : 12,
"start_offset" : 23,
"end_offset" : 24
}
]
},
"索引" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 7,
"start_offset" : 14,
"end_offset" : 16
}
]
},
"都是" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 10,
"start_offset" : 19,
"end_offset" : 21
}
]
},
"默认" : {
"term_freq" : 1,
"tokens" : [
{
"position" : 5,
"start_offset" : 11,
"end_offset" : 13
}
]
}
}
}
}
}
然后就可以通过词去搜索了:
GET blog/_search
{
"query": {
"term": {
"title": "索引"
}
}
}
search_analyzer
查询时候的分词器。默认情况下,如果没有配置 search_analyzer,则查询时,首先查看有没有 search_analyzer,有的话,就用 search_analyzer 来进行分词,如果没有,则看有没有 analyzer,如果有,则用 analyzer 来进行分词,否则使用 es 默认的分词器。
normalizer
normalizer 参数用于解析前(索引或者查询)的标准化配置。
比如,在 es 中,对于一些我们不想切分的字符串,我们通常会将其设置为 keyword,搜索时候也是使用整个词进行搜索。如果在索引前没有做好数据清洗,导致大小写不一致,例如 javaboy 和 JAVABOY,此时,我们就可以使用 normalizer 在索引之前以及查询之前进行文档的标准化。
先来一个反例,创建一个名为 blog 的索引,设置 author 字段类型为 keyword:
PUT blog
{
"mappings": {
"properties": {
"author":{
"type": "keyword"
}
}
}
}
添加两个文档:
PUT blog/_doc/1
{
"author":"javaboy"
}
PUT blog/_doc/2
{
"author":"JAVABOY"
}
然后进行搜索:
GET blog/_search
{
"query": {
"term": {
"author": "JAVABOY"
}
}
}
大写关键字可以搜到大写的文档,小写关键字可以搜到小写的文档。
如果使用了 normalizer,可以在索引和查询时,分别对文档进行预处理。
normalizer 定义方式如下:
PUT blog
{
"settings": {
"analysis": {
"normalizer":{
"my_normalizer":{
"type":"custom",
"filter":["lowercase"]
}
}
}
},
"mappings": {
"properties": {
"author":{
"type": "keyword",
"normalizer":"my_normalizer"
}
}
}
}
在 settings 中定义 normalizer,然后在 mappings 中引用。
测试方式和前面一致。此时查询的时候,大写关键字也可以查询到小写文档,因为无论是索引还是查询,都会将大写转为小写
boost
boost 参数可以设置字段的权重。
boost 有两种使用思路,一种就是在定义 mappings 的时候使用,在指定字段类型时使用;另一种就是在查询时使用。
实际开发中建议使用后者,前者有问题:如果不重新索引文档,权重无法修改。
mapping 中使用 boost(不推荐):
PUT blog
{
"mappings": {
"properties": {
"content":{
"type": "text",
"boost": 2
}
}
}
}
另一种方式就是在查询的时候,指定 boost
GET blog/_search
{
"query": {
"match": {
"content": {
"query": "你好",
"boost": 2
}
}
}
}
coerce
coerce 用来清除脏数据,默认为 true。
例如一个数字,在 JSON 中,用户可能写错了:
{"age":"99"}
或者 :
{"age":"99.0"}
这些都不是正确的数字格式。
通过 coerce 可以解决该问题。
默认情况下,以下操作没问题,就是 coerce 起作用:
PUT blog
{
"mappings": {
"properties": {
"age":{
"type": "integer"
}
}
}
}
POST blog/_doc
{
"age":"99.0"
}
如果需要修改 coerce ,方式如下:
PUT blog
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"coerce": false
}
}
}
}
POST blog/_doc
{
"age":99
}
当 coerce 修改为 false 之后,数字就只能是数字了,不可以是字符串,该字段传入字符串会报错。
copy_to
这个属性,可以将多个字段的值,复制到同一个字段中。
定义方式如下:
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"copy_to": "full_content"
},
"content":{
"type": "text",
"copy_to": "full_content"
},
"full_content":{
"type": "text"
}
}
}
}
PUT blog/_doc/1
{
"title":"你好江南一点雨",
"content":"当 coerce 修改为 false 之后,数字就只能是数字了,不可以是字符串,该字段传入字符串会报错。"
}
GET blog/_search
{
"query": {
"term": {
"full_content": "当"
}
}
}
doc_values 和 fielddata
es 中的搜索主要是用到倒排索引,doc_values 参数是为了加快排序、聚合操作而生的。当建立倒排索引的时候,会额外增加列式存储映射。
doc_values 默认是开启的,如果确定某个字段不需要排序或者不需要聚合,那么可以关闭 doc_values。
大部分的字段在索引时都会生成 doc_values,除了 text。text 字段在查询时会生成一个 fielddata 的数据结构,fieldata 在字段首次被聚合、排序的时候生成。
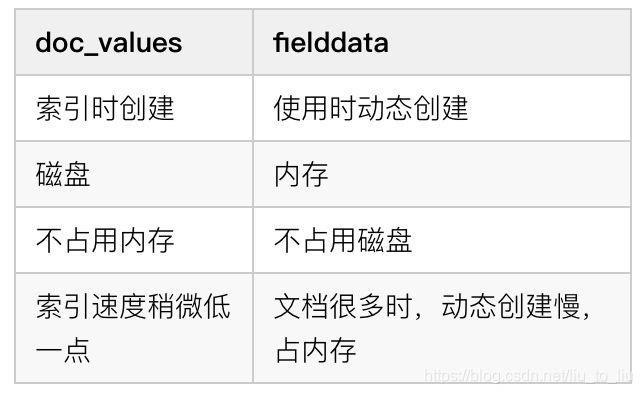
doc_values 默认开启,fielddata 默认关闭。
doc_values 演示:
PUT users
PUT users/_doc/1
{
"age":100
}
PUT users/_doc/2
{
"age":99
}
PUT users/_doc/3
{
"age":98
}
PUT users/_doc/4
{
"age":101
}
GET users/_search
{
"query": {
"match_all": {}
},
"sort":[
{
"age":{
"order": "desc"
}
}
]
}
由于 doc_values 默认时开启的,所以可以直接使用该字段排序,如果想关闭 doc_values ,如下:
PUT users
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"doc_values": false
}
}
}
}
PUT users/_doc/1
{
"age":100
}
PUT users/_doc/2
{
"age":99
}
PUT users/_doc/3
{
"age":98
}
PUT users/_doc/4
{
"age":101
}
GET users/_search
{
"query": {
"match_all": {}
},
"sort":[
{
"age":{
"order": "desc"
}
}
]
}
dynamic
enabled
es 默认会索引所有的字段,但是有的字段可能只需要存储,不需要索引。此时可以通过 enabled 字段来控制:
PUT blog
{
"mappings": {
"properties": {
"title":{
"enabled": false
}
}
}
}
PUT blog/_doc/1
{
"title":"javaboy"
}
GET blog/_search
{
"query": {
"term": {
"title": "javaboy"
}
}
}
设置了 enabled 为 false 之后,就可以再通过该字段进行搜索了。
format
日期格式。format 可以规范日期格式,而且一次可以定义多个 format。
PUT users
{
"mappings": {
"properties": {
"birthday":{
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
}
}
}
}
PUT users/_doc/1
{
"birthday":"2020-11-11"
}
PUT users/_doc/2
{
"birthday":"2020-11-11 11:11:11"
}
- 多个日期格式之间,使用 || 符号连接,注意没有空格。
- 如果用户没有指定日期的 format,默认的日期格式是 strict_date_optional_time||epoch_mills
另外,所有的日期格式,可以在https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-date-format.html 网址查看。
ignore_above
igbore_above 用于指定分词和索引的字符串最大长度,超过最大长度的话,该字段将不会被索引,这个字段只适用于 keyword 类型。
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "keyword",
"ignore_above": 10
}
}
}
}
PUT blog/_doc/1
{
"title":"javaboy"
}
PUT blog/_doc/2
{
"title":"javaboyjavaboyjavaboy"
}
GET blog/_search
{
"query": {
"term": {
"title": "javaboyjavaboyjavaboy"
}
}
}
ignore_malformed
ignore_malformed 可以忽略不规则的数据,该参数默认为 false。
PUT users
{
"mappings": {
"properties": {
"birthday":{
"type": "date",
"format": "yyyy-MM-dd||yyyy-MM-dd HH:mm:ss"
},
"age":{
"type": "integer",
"ignore_malformed": true
}
}
}
}
PUT users/_doc/1
{
"birthday":"2020-11-11",
"age":99
}
PUT users/_doc/2
{
"birthday":"2020-11-11 11:11:11",
"age":"abc"
}
PUT users/_doc/2
{
"birthday":"2020-11-11 11:11:11aaa",
"age":"abc"
}
include_in_all
这个是针对 _all 字段的,但是在 es7 中,该字段已经被废弃了。
index
index 属性指定一个字段是否被索引,该属性为 true 表示字段被索引,false 表示字段不被索引。
PUT users
{
"mappings": {
"properties": {
"age":{
"type": "integer",
"index": false
}
}
}
}
PUT users/_doc/1
{
"age":99
}
GET users/_search
{
"query": {
"term": {
"age": 99
}
}
}
- 如果 index 为 false,则不能通过对应的字段搜索。
index_options
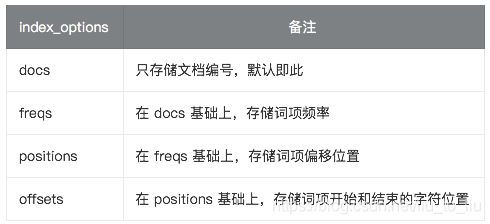
index_options 控制索引时哪些信息被存储到倒排索引中(用在 text 字段中),有四种取值:
norms
norms 对字段评分有用,text 默认开启 norms,如果不是特别需要,不要开启 norms。
null_value
在 es 中,值为 null 的字段不索引也不可以被搜索,null_value 可以让值为 null 的字段显式的可索引、可搜索:
PUT users
{
"mappings": {
"properties": {
"name":{
"type": "keyword",
"null_value": "javaboy_null"
}
}
}
}
PUT users/_doc/1
{
"name":null,
"age":99
}
GET users/_search
{
"query": {
"term": {
"name": "javaboy_null"
}
}
}
position_increment_gap
被解析的 text 字段会将 term 的位置考虑进去,目的是为了支持近似查询和短语查询,当我们去索引一个含有多个值的 text 字段时,会在各个值之间添加一个假想的空间,将值隔开,这样就可以有效避免一些无意义的短语匹配,间隙大小通过 position_increment_gap 来控制,默认是 100。
PUT users
PUT users/_doc/1
{
"name":["zhang san","li si"]
}
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "sanli"
}
}
}
}
sanli搜索不到,因为两个短语之间有一个假想的空隙,为 100。
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li",
"slop": 101
}
}
}
}
可以通过 slop 指定空隙大小。
也可以在定义索引的时候,指定空隙:
PUT users
{
"mappings": {
"properties": {
"name":{
"type": "text",
"position_increment_gap": 0
}
}
}
}
PUT users/_doc/1
{
"name":["zhang san","li si"]
}
GET users/_search
{
"query": {
"match_phrase": {
"name": {
"query": "san li"
}
}
}
}
properties
similarity
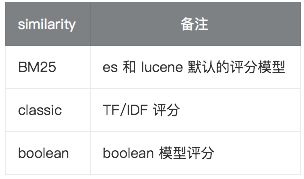
similarity 指定文档的评分模型,默认有三种:
store
默认情况下,字段会被索引,也可以搜索,但是不会存储,虽然不会被存储的,但是 _source 中有一个字段的备份。如果想将字段存储下来,可以通过配置 store 来实现。
term_vectors
term_vectors 是通过分词器产生的信息,包括:
- 一组 terms
- 每个 term 的位置
- term 的首字符/尾字符与原始字符串原点的偏移量
term_vectors 取值:

fields
fields 参数可以让同一字段有多种不同的索引方式。例如:
PUT blog
{
"mappings": {
"properties": {
"title":{
"type": "text",
"fields": {
"raw":{
"type":"keyword"
}
}
}
}
}
}
PUT blog/_doc/1
{
"title":"javaboy"
}
GET blog/_search
{
"query": {
"term": {
"title.raw": "javaboy"
}
}
}
- https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-params.html
ElasticSearch 映射模版

PUT blog
{
"mappings": {
"dynamic_templates": [
{
"long2integer": {
"match_mapping_type": "long",
"mapping": {
"type": "integer"
}
}
}
]
}
}
PUT blog/_doc/1
{
"count":99
}
PUT blog
{
"mappings": {
"dynamic_templates":[
{
"string2long": {
"match_mapping_type": "string",
"match": "num_*",
"unmatch": "*_text",
"mapping": {
"type": "integer"
}
}
}
]
}
}
PUT blog/_doc/1
{
"num_count": "99",
"num_text": "javaboy"
}
PUT blog/_doc/2
{
"num_count": "99",
"num_text":"javaboy",
"num_aaa": 999
}
PUT blog/_doc/1
{
"num_count": "99",
"num_text": "javaboy"
}
ElasticSearch高级检索(Query)



索引原理

Logstash
