【网安AIGC专题10.11】软件安全+安全代码大模型
软件安全+安全代码大模型
- 写在最前面
- 一些启发
-
- 科研方法
- 科研思路
- 课程考察要求
- 软件供应链安全
- 漏洞复制
-
- 1、代码克隆
- 2、组件依赖分析
- 关键组件安全不足,漏洞指数级放大
-
- 供应链投毒
- 内部攻击
- 源代码攻击
- 分发、下载网站攻击
- 更新、补丁网站攻击
- 形成技术壁垒(找方向)
- 体系化工作:安全代码大模型(重点)
-
- 论文1:细粒度源代码漏洞识别(对一种特定的漏洞)
- 论文2:对识别的漏洞进行分类(对多种漏洞)
- 论文3:漏洞定位
- 模型可解释性
- 健壮性
- 验证漏洞
- (未来)修复
写在最前面
本文为邹德清教授的《网络安全专题》课堂笔记系列的文章,本次专题主题为大模型。
第一次课上,邹德清教授对软件安全+安全代码大模型进行了介绍

一些启发
科研方法
最好进行一系列体系性工作,科研连贯、市场需求、能落地(业务:提供代码扫描检测)、
批判性思维
科研思路
(数据集趋势)有监督-》无监督(因此可以尝试大模型)
异常数据识别-》提高acc
代码检测,bug修复
基于代码相似性,可控语义等价代码替换
模型可解释性:启发式搜索、决策树、规则提取
识别(label01、全局+局部)——分类(label增加)——定位(GCN、图结构传播)——可解释性(启发式搜索、决策树、规则提取)——健壮性(基于相似性,可控语义等价替换)——验证——修复
课程考察要求
针对分享文章的研究内容以及related work进行分析,比较,批判,总结,形成综述。
使用IEEE格式,中英文皆可,形成纸质版材料。字数要求按照平常论文投稿要求(10页以内)。
提交时间:本学期放假前
软件供应链安全
软件供应链的三种不同解释。
涵盖了从开发人员编写源代码、第三方组件的集成、构建和编译过程、部署和维护等多个环节。
供应链中的每个环节都可能受到潜在威胁,而软件供应链安全旨在降低这些威胁的风险。
软件供应链安全是确保在开发、交付和维护软件产品的整个生命周期中,不会出现恶意或不安全的元素或活动的一系列实践和措施。
漏洞复制
由于开源组件,导致的漏洞复制
漏洞复制是指由于在不同的软件项目或组件中,使用相同或相似的开源组件,而导致相同漏洞在多个项目中出现的情况。
软件开发阶段:依赖分析
1、代码克隆
软件依赖-》克隆检测
粒度
索引方法
代码克隆是指在不同的代码片段之间存在相似性或相同性,通常是由于代码被重复使用、复制或修改而产生的。
克隆检测是一种用于识别和管理代码克隆的技术,以帮助维护软件的质量和可维护性。
粒度和索引方法是克隆检测的两个重要方面:
-
克隆检测的粒度:
- 行级克隆检测: 这是最细粒度的克隆检测,它比较源代码文件的每一行,以找到相似的行。这有助于检测代码中的小规模复制和修改。
- 函数级克隆检测: 这一级别的检测关注函数或方法的相似性,不仅仅是行的相似性。它可以帮助找到在不同上下文中重复使用的功能。
- 模块/文件级克隆检测: 这一级别的检测关注整个源代码文件或模块的相似性。它有助于发现在不同文件中复制和粘贴的代码段。
-
索引方法:
- 标记索引: 标记索引是将代码分割成标记(tokens),然后为这些标记构建索引,以便查找相似性。这通常涉及对代码进行分词,并使用标记来表示代码结构和内容。
- 语法树索引: 语法树索引会将代码解析为语法树,并使用语法树来表示代码结构。这允许检测工具查找具有相似语法结构的代码片段。
- 抽象语法树(AST)索引: AST索引类似于语法树索引,但更关注代码的高级结构,而不是详细的语法。它有助于找到在不同上下文中使用相似抽象结构的代码。
- 哈希索引: 哈希索引会将代码块转换为哈希值,并将哈希值用于比较代码块之间的相似性。这通常用于加速检测过程。
精确的克隆检测有助于开发人员更好地管理代码库,提高代码的可维护性,并识别潜在的缺陷。
它也有助于维护软件的质量和安全性,因为相似的代码可能在多个地方引入相同的漏洞或问题。
2、组件依赖分析
代码复用
(不看全部代码的情况下进行检测)
依赖配置文件
软件包管理
- 组件依赖: 组件依赖是指一个软件项目或系统依赖于其他软件组件、库或模块来实现特定功能。这些依赖可以是开源组件、第三方库、或其他内部开发的模块。
依赖分析工具:自动识别项目的组件依赖。扫描项目的代码和配置文件,然后生成依赖图或列表。一些常见的依赖分析工具包括:
- OWASP Dependency-Check: 用于检查Java和.NET项目的开源组件漏洞的工具,它可以帮助你了解项目的依赖关系并检查漏洞。
- snyk: 用于检测和修复开源组件漏洞的工具,支持多种编程语言和环境。
- Dependabot: 自动检测并升级项目依赖项的工具,它可以帮助你保持依赖项的最新版本。
-
代码复用: 代码复用是指在不同的部分或项目中重复使用相同或类似的代码。它有助于减少开发工作量,提高代码的一致性和可维护性。在软件开发中,代码复用通常可以通过将通用函数、类或模块提取到单独的库或组件中来实现。
-
依赖配置文件: 依赖配置文件是一种用于定义项目中所需依赖项的文件。这些文件通常包含了项目所需的库和版本信息,以便软件包管理工具能够自动下载和安装这些依赖项。一些常见的依赖配置文件包括:
- package.json: 在Node.js项目中使用的配置文件,用于管理项目的依赖项。
- requirements.txt: 在Python项目中使用的配置文件,列出了项目所需的Python包和版本。
- pom.xml: 在Java项目中使用的配置文件,用于定义项目的依赖关系。
-
软件包管理: 软件包管理是一种工具或系统,用于管理和维护项目所需的软件包、库和依赖项。一些常见的软件包管理工具包括:
- npm (Node Package Manager): 用于Node.js项目的软件包管理工具,通过
package.json文件管理依赖项。 - pip (Python Package Installer): 用于Python项目的软件包管理工具,通过
requirements.txt文件管理依赖项。 - Maven: 用于Java项目的构建工具和依赖管理工具,通过
pom.xml文件管理依赖关系。 - NuGet: 用于.NET项目的包管理器,用于管理.NET组件和库的依赖关系。
- npm (Node Package Manager): 用于Node.js项目的软件包管理工具,通过
关键组件安全不足,漏洞指数级放大
十几个组件的复用
供应链投毒
供应链投毒是指恶意攻击者在软件供应链的某个环节中植入恶意代码、漏洞或后门。这可以发生在开源组件或库被感染,或者在开发者或第三方组件提供者受到攻击时。如果关键组件受到供应链投毒,那么整个软件项目将面临潜在的风险,因为这些恶意组件可能会导致漏洞指数级放大。
内部攻击
内部攻击是指软件开发过程中的内部人员,如开发者或维护者,恶意修改或操纵关键组件的行为。这可能包括恶意的代码更改、潜在的后门或恶意存储库提交。这种行为可能导致关键组件的安全不足,从而影响整个软件项目的安全性。
源代码攻击
攻击者可能尝试通过修改或篡改关键组件的源代码来引入漏洞或恶意功能。这种源代码攻击可能通过恶意Pull请求、开发者帐户被入侵或恶意合并请求等方式发生。
分发、下载网站攻击
如果恶意攻击者能够控制或篡改软件分发和下载网站,他们可以向用户分发包含恶意组件的软件。用户可能会下载并安装这些被篡改的软件,从而将恶意组件引入其系统。
更新、补丁网站攻击
更新和补丁网站是用户获取软件更新和安全补丁的主要来源。如果攻击者能够攻击这些网站,他们可以分发带有恶意组件或漏洞的更新。
形成技术壁垒(找方向)
恶意代码检测,打不过大厂安全专家
常规精准漏洞检测
1、特征复杂
2、根据语法特征,规则检测
自动化恶意代码检测
体系化工作:安全代码大模型(重点)
之前+之后
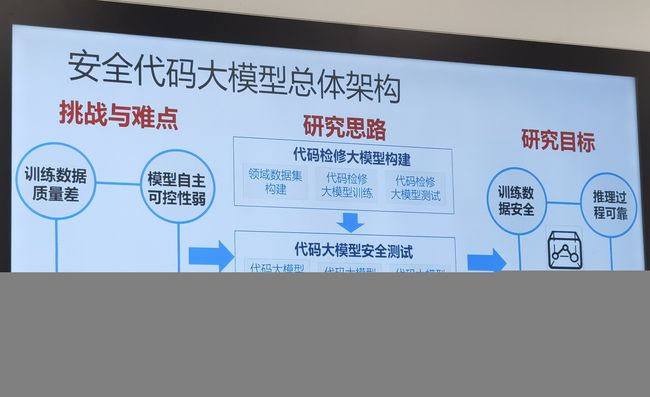
体系化工作,连贯性思维(常用方法,邹德清教授团队方法将在下面展开介绍):
-
漏洞发现: 可以通过各种手段实现,包括静态代码分析、动态安全测试、渗透测试、模糊测试等。漏洞可能是由恶意攻击者利用的已知漏洞,也可能是新的漏洞,需要深入研究和分析。
-
漏洞分类: 可以根据其类型进行分类,例如安全漏洞、性能漏洞、配置漏洞等。
-
深入代码审查: 深入代码审查是一种通过仔细分析源代码来定位漏洞的方法。这可能涉及查找潜在的漏洞源、漏洞触发条件和漏洞利用路径。
-
动态分析: 动态分析涉及在运行时监视应用程序以查找漏洞。这可能包括利用调试器或监视应用程序的网络流量和行为。
-
复现漏洞: 为模拟漏洞利用的条件,并验证漏洞的存在。
-
漏洞修复: 可能涉及更改源代码、应用程序配置或应用程序的安全策略,以防止漏洞被利用。
-
跟踪漏洞: 以确保它们得到妥善处理和修复。这通常需要漏洞管理系统来记录漏洞的状态和修复进展。
论文1:细粒度源代码漏洞识别(对一种特定的漏洞)
切片技术
全局,采用code gadget
局部,引入code attention
补充说明:
-
细粒度源代码漏洞识别: 对源代码进行深入分析,以发现和理解其中的漏洞,包括那些非常微小或难以察觉的漏洞。通常结合了静态和动态分析方法。
-
切片技术: 一种源代码分析方法,用于找到和提取与特定问题或特征相关的代码片段。这可以帮助分析人员聚焦于问题的核心,并降低复杂性。在漏洞识别中,切片技术可用于确定漏洞的根本原因以及可能的传播路径。
-
全局方法: 涉及到对整个代码库进行分析,以查找漏洞的存在或可能性。这可以帮助发现全局性的问题,但也可能产生大量的误报。
-
局部方法: 关注代码的特定部分,以查找局部范围内的漏洞或问题。这可以帮助降低误报率。
-
Code Gadget: 源代码中的可疑代码块或模块,这些代码块可能容易受到攻击或包含漏洞。检测和关注这些"Code Gadgets"有助于找出可能的安全问题。
-
Code Attention: 引入了关注机制,以将关注点放在潜在的漏洞或问题上。这有助于提高分析的效率。
论文2:对识别的漏洞进行分类(对多种漏洞)
传统的漏洞分类通常是基于漏洞类型(例如,SQL注入、XSS等)和漏洞严重性(高、中、低)等。
但分类时,深度学习可能不易理解,效果不佳?(这里不太确认是不是因为这个原因了)
通过整理,提出api漏洞等多种新的分类解释,深度学习效果也不错
但由于是首次提出进行这项工作,因此审稿人意见不一
幸运的是最后接收了,并且这几年引用率特别高,被多个院士团队所引用,这表明工作在学术界和研究领域具有价值
论文3:漏洞定位
GCN图神经网络
在图上执行卷积操作来学习节点之间的关系和表示,适用于分析和处理漏洞定位中的图结构数据。
模型可解释性
启发式搜索
决策树
规则提取
启发式搜索: 基于启发式信息(经验和专业知识)的搜索方法,用于在大规模的搜索空间中找到最佳解决方案。在模型可解释性方面,启发式搜索可以用于解释模型的预测结果或内部决策。
例如,可以使用启发式搜索来确定在特定情况下哪些特征对模型的预测结果产生了最大影响,从而帮助解释模型的工作原理。
决策树: 决策树是一种用于分类和回归分析的监督学习方法,它生成树状结构,其中每个节点表示一个特征或属性,每个分支表示一个决策规则,而每个叶子节点表示一个类别或数值输出。决策树模型具有直观的可解释性,因为它们可以轻松地转化为规则,帮助理解模型的决策过程。
规则提取: 规则提取是一种将模型的预测结果转化为易于理解的规则或规则集的方法。这些规则可以帮助解释模型的决策过程,并提供透明性。规则提取通常用于黑盒模型,如神经网络或支持向量机,以提高模型的可解释性。这些规则可以基于模型的输入特征和权重来生成。
健壮性
可控语义等价代码替换(代码相似性)
健壮性(Robustness)指的是系统、应用程序或算法对于异常情况、攻击、噪声或不良输入的鲁棒性。
可控语义等价代码替换: 这是一种方法,旨在通过替代现有代码的部分或整个部分,以提高系统或应用程序对于恶意攻击或异常输入的鲁棒性。通过进行可控的代码替换,可以确保替代的代码在语义上等价于原始代码,从而不会破坏系统的正确性。
有助于增加系统的多样性,减少攻击者的成功概率,因为攻击者难以预测替代代码的行为。
代码相似性: 代码相似性是指不同代码段之间的结构或语义相似性。在健壮性的上下文中,代码相似性可用于识别和比较潜在的替代代码块,以增强系统对于异常情况的处理。
例如,如果系统能够检测到与已知漏洞相似的代码结构,它可以采取适当的措施,如拒绝请求或进行进一步的验证。
验证漏洞
模拟漏洞利用的条件,并验证漏洞的存在。