Apache Doris 整合 FLINK 、 Hudi 构建湖仓一体的联邦查询入门
1.概览
多源数据目录(Multi-Catalog)功能,旨在能够更方便对接外部数据目录,以增强Doris的数据湖分析和联邦数据查询能力。
在之前的 Doris 版本中,用户数据只有两个层级:Database 和 Table。当我们需要连接一个外部数据目录时,我们只能在Database 或 Table 层级进行对接。比如通过 create external table 的方式创建一个外部数据目录中的表的映射,或通过 create external database 的方式映射一个外部数据目录中的 Database。如果外部数据目录中的 Database 或 Table 非常多,则需要用户手动进行一一映射,使用体验不佳。
而新的 Multi-Catalog 功能在原有的元数据层级上,新增一层Catalog,构成 Catalog -> Database -> Table 的三层元数据层级。其中,Catalog 可以直接对应到外部数据目录。目前支持的外部数据目录包括:
- Apache Hive
- Apache Iceberg
- Apache Hudi
- Elasticsearch
- JDBC: 对接数据库访问的标准接口(JDBC)来访问各式数据库的数据。
- Apache Paimon(Incubating)
该功能将作为之前外表连接方式(External Table)的补充和增强,帮助用户进行快速的多数据目录联邦查询。
这篇教程将展示如何使用 Flink + Hudi + Doris 构建实时湖仓一体的联邦查询分析,Doris 2.0.3 版本提供了 的支持,本文主要展示 Doris 和 Hudi 怎么使用,同时本教程整个环境是都基于伪分布式环境搭建,大家按照步骤可以一步步完成。完整体验整个搭建操作的过程。
2. 环境
本教程的演示环境如下:
- Centos7
- Apache doris 2.0.2
- Hadoop 3.3.3
- hive 3.1.3
- Fink 1.17.1
- Apache hudi 0.14
- JDK 1.8.0_311
3. 安装
- 下载 Flink 1.17.1
wget https://dlcdn.apache.org/flink/flink-1.17.1/flink-1.17.1-bin-scala_2.12.tgz
## 解压安装
tar zxf flink-1.17.1-bin-scala_2.12.tgz - 下载 Flink 和 Hudi 相关的依赖
wget https://repo1.maven.org/maven2/org/apache/flink/flink-table-planner_2.12/1.17.1/flink-table-planner_2.12-1.17.1.jar
wget https://repo1.maven.org/maven2/org/apache/hudi/hudi-hive-sync-bundle/0.14.0/hudi-hive-sync-bundle-0.14.0.jar
wget https://repo1.maven.org/maven2/org/apache/hudi/hudi-flink1.17-bundle/0.14.0/hudi-flink1.17-bundle-0.14.0.jar
wget https://repo1.maven.org/maven2/org/apache/hudi/hudi-hadoop-mr-bundle/0.14.0/hudi-hadoop-mr-bundle-0.14.0.jar将上面这些依赖下载到 flink-1.17.1/lib 目录,然后将之前的 flink-table-planner-loader-1.17.1.jar 删除或者移除。
3. 创建 Hudi 表并写入数据
3.1 启动 Flink
bin/start-cluster.sh启动 Flink client
./bin/sql-client.sh embedded shell#设置返回结果模式为tableau,让结果直接显示
set sql-client.execution.result-mode=tableau;3.2 启动 Hive MetaStore 和 HiveServer
nohup ./bin/hive --service hiveserver2 >/dev/null 2>&1 &
nohup ./bin/hive --service metastore >/dev/null 2>&1 &3.3 创建 Hudi 表
我们来创建 Hudi 表,我们这里使用 Hive MetaStore Service 来保存 Hudi 的元数据。
CREATE TABLE table1(
uuid VARCHAR(20) PRIMARY KEY NOT ENFORCED,
name VARCHAR(10),
age INT,
ts TIMESTAMP(3),
`partition` VARCHAR(20)
)
PARTITIONED BY (`partition`)
with(
'connector'='hudi',
'path' = 'hdfs://localhost:9000/user/hive/warehouse/demo.db',
'table.type'='COPY_ON_WRITE',
'hive_sync.enable'='true',
'hive_sync.table'='hudi_hive',
'hive_sync.db'='demo',
'hive_sync.mode' = 'hms',
'hive_sync.metastore.uris' = 'thrift://192.168.31.54:9083'
);
- 'table.type'='COPY_ON_WRITE', -- MERGE_ON_READ方式在没生成 parquet 文件前,hive不会有输出
- 'hive_sync.enable'='true', -- required,开启hive同步功能
- 'hive_sync.table'='${hive_table}', -- required, hive 新建的表名
- 'hive_sync.db'='${hive_db}', -- required, hive 新建的数据库名
- 'hive_sync.mode' = 'hms', -- required, 将hive sync mode设置为hms, 默认jdbc
- 'hive_sync.metastore.uris' = 'thrift://ip:9083' -- required, metastore的端口
写入数据:
INSERT INTO table1 VALUES
('id1','Danny',23,TIMESTAMP '1970-01-01 00:00:01','par1'),
('id2','Stephen',33,TIMESTAMP '1970-01-01 00:00:02','par1'),
('id3','Julian',53,TIMESTAMP '1970-01-01 00:00:03','par2'),
('id4','Fabian',31,TIMESTAMP '1970-01-01 00:00:04','par2'),
('id5','Sophia',18,TIMESTAMP '1970-01-01 00:00:05','par3'),
('id6','Emma',20,TIMESTAMP '1970-01-01 00:00:06','par3'),
('id7','Bob',44,TIMESTAMP '1970-01-01 00:00:07','par4'),
('id8','Han',56,TIMESTAMP '1970-01-01 00:00:08','par4');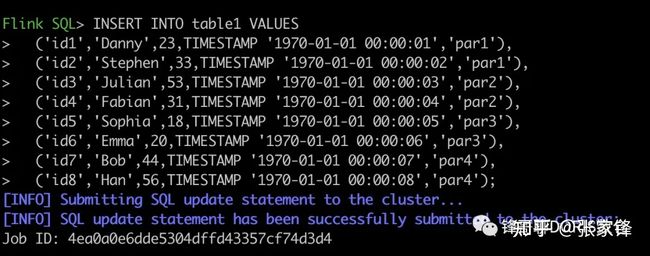
通过 Flink 查询 Hudi 表的数据
SELECT * FROM TABLE1
我们可以查看 HDFS 上这个数据文件已经存在,在 hive client 下也可以看到这表
hive> use demo;
OK
Time taken: 0.027 seconds
hive> show tables;
OK
hudi_hive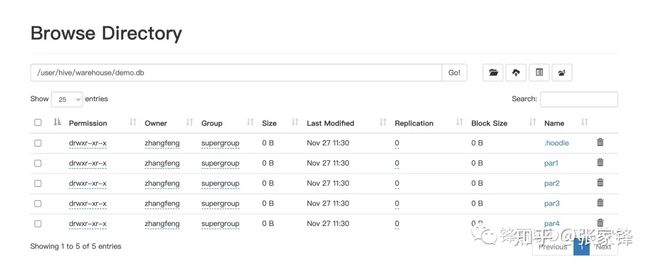
4. Doris On Hudi
Doris 操作访问 Hudi 的数据很简单,我们只需要创建一个 catalog 就可以,不需要再想之前一样写一个完整的建表语句,同时当 Hudi 数据源中增删表或者增删字段,Doris 这边可以通过配置自动刷新或者手动刷新Catalog 自动感知。
下面我们在Doris 下创建一个 Catalog 来访问 Hudi 外部表的数据
CREATE CATALOG hudi PROPERTIES (
'type'='hms',
'hive.metastore.uris' = 'thrift://192.168.31.54:9083'
);这里我们上面Hudi的元数据是使用HMS存储的,我们创建的时候只需要指定上面两个信息即可,如果你的HDFS是高可用的,你需要添加NameNode HA的信息:
'hadoop.username' = 'hive',
'dfs.nameservices'='your-nameservice',
'dfs.ha.namenodes.your-nameservice'='nn1,nn2',
'dfs.namenode.rpc-address.your-nameservice.nn1'='172.21.0.2:4007',
'dfs.namenode.rpc-address.your-nameservice.nn2'='172.21.0.3:4007',
'dfs.client.failover.proxy.provider.your-nameservice'='org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider'具体参照Doris 官网文档
创建成功之后我们可以通过下面的红框标识出来的步骤去看到 Hudi 的表。

执行查询 Hudi 表:

将 Hudi 表里的数据迁移到 Doris
这里我们先创建好 Doris的表,建表语句如下:
CREATE TABLE doris_hudi(
uuid VARCHAR(20) ,
name VARCHAR(10),
age INT,
ts datetime(3),
`partition` VARCHAR(20)
)
UNIQUE KEY(`uuid`)
DISTRIBUTED BY HASH(`uuid`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true"
);通过 Insert Select 语句将 Hudi 数据迁移到 Doris :
insert into doris_hudi select uuid,name,age,ts,partition from hudi.demo.hudi_hive;查询 Doris 表
mysql> select * from doris_hudi;
+------+---------+------+-------------------------+-----------+
| uuid | name | age | ts | partition |
+------+---------+------+-------------------------+-----------+
| id1 | Danny | 23 | 1970-01-01 08:00:01.000 | par1 |
| id2 | Stephen | 33 | 1970-01-01 08:00:02.000 | par1 |
| id3 | Julian | 53 | 1970-01-01 08:00:03.000 | par2 |
| id4 | Fabian | 31 | 1970-01-01 08:00:04.000 | par2 |
| id5 | Sophia | 18 | 1970-01-01 08:00:05.000 | par3 |
| id6 | Emma | 20 | 1970-01-01 08:00:06.000 | par3 |
| id7 | Bob | 44 | 1970-01-01 08:00:07.000 | par4 |
| id8 | Han | 56 | 1970-01-01 08:00:08.000 | par4 |
+------+---------+------+-------------------------+-----------+
8 rows in set (0.02 sec)我们那还可以通过 CATS方式将 hudi数据迁移到Doris,Doris 自动完成建表
create table doris_hudi_01
PROPERTIES("replication_num" = "1") as
select uuid,name,age,ts,`partition` from hudi.demo.hudi_hive;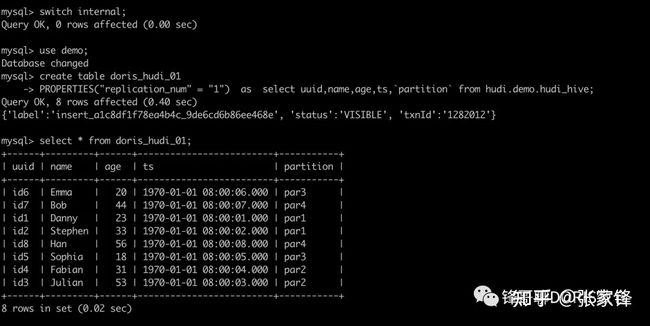
5. 总结
是不是使用非常简单,快快体验Doris 湖仓一体,联邦查询的能力,来加速你的数据分析性能