cpu飙高问题,案例分析(二)——批处理数据过大引起的应用服务CPU飙高
上接cpu飙高问题,案例分析(一)
一、批处理数据过大引起的应用服务CPU飙高
1.1 问题场景
某定时任务job 收到cpu连续(配置的时间是180s)使用超过90%的报警;
1.2 问题定位
- 观察报警中的jvm监控,发现周期性出现即每天8:00,cpu从5%-99%大约持续3分钟左右然后恢复正常,平时cpu使用率较为平稳(排除因为应用发布导致的cpu升高);
- 任务系统周期性出现很可能是定时执行了大量运算导致的,查看任务系统页面,确实存在一个8点执行的定时任务;
- 分析代码梳理该任务的业务逻辑为:一个兜底的定时的job任务;其中涉及大量复杂运算,现在猜测基本是改任务导致的,那么可以复现一下,确认下;
复现操作很简单:
a.找一台机器,观察jvm相关监控;观察日志;
b.修改分片数量为1且指定分片容器ip为监控的容器ip,点击执行分片,查看分片确认成功后, 点击执行一次。通过观察步骤c1)成功复现。
- 至此基本方向确定是这个任务导致的CPU升高,接下来分析为何CPU升高,以及如何优化问题;
1.3 问题分析
- a)也可能是程序运行过程创建大量对象触发GC,GC线程占用CPU过高导致;b)CPU升高原因可能是程序大量运算导致;
- 不管是情况a) 还是情况b) 都需要复现问题,观察使用cpu高的线程有哪些,使用jstack命令导出线程栈的信息进行观察,观察每个线程CPU使用率;
1.4 操作步骤
- 预发环境触发任务执行,复现场景。注意:此步骤需要谨慎操作,由于预发和线上是相同的数据库,所以预发环境部署代码需要把相关的操作屏蔽掉了,比如发送MQ,更新数据库等。避免影响线上数据和MQ等;
- 登录堡垒机使用top命令查看目前的进程信息:
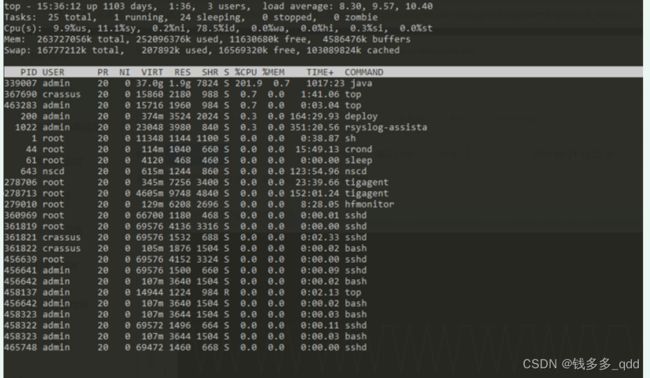
- 发现java进程33907 使用的cpu已经达到200%,使用命令 top-H -p 33907 命令查看该进程下的哪个线程使用的资源最多

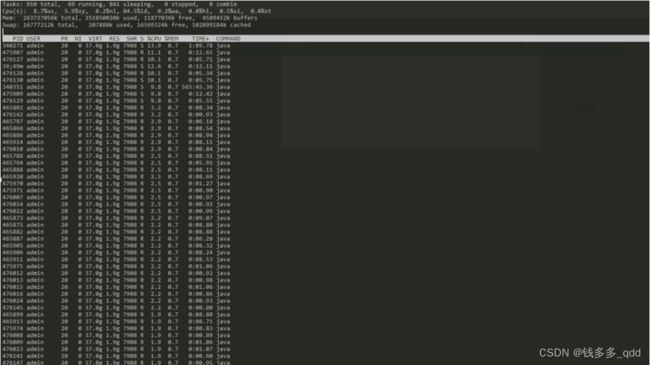

340271 5312f Curator-TreeCache-18" #648 daemon prio=5 os_prio=0 tid=0x00007f10dc156000 nid=0x5312f waiting on condition [0x00007f1158bcb000]
1.5 结论
- ThreadPoolTaskExecutor为该任务显示创建,核心线程数为2,最大为6,队列大小为300,根据线程栈信息可以看出与程序配置一致,根据实际配置可以发现此部分正常配置符合预期;
- 程序中没有创建FrokJoinPool,但是程序使用了大量的 parallelStream();由于parallelStream默认使用的是公共的forkJoinPool线程池,且该线程池的线程数量配置为系统的 Runtime.getRuntime().availableProcessors() - 1; 现在对于parallelStream的使用等于在多线程中,嵌套了多线程;
- Curator-TreeCache 线程的来源,通过发现线程池的初始化参数可知:线程的的拒绝策略为CallerRunsPolicy(),该策略为:如果线程池队列和核心线程数满了后,继续提交到线程池的任务会通过方法线程即调用线程池的那个方法来执行,可以理解为主线程;
1.6 优化方案
- 修改所有的parallelStream() 为stream();4c8G配置的机器cpu使用率稳定在50%左右;
- 2C4G的机器执行,CPU使用率仍然高达90%,通过分析线程栈的dump文件发现主要是业务线程占用资源过高,其中不足2%的还有部分是由于并行流导致的,在job执行时候引用的第三方jar包中,此部分暂时不处理;
对于2C4G优化方案:
- 由于这个任务是兜底的,不需要立即执行完成,且执行频率为1天1次可以将线程池调整为1个线程;
- 申请容器升级为4c*8G.;
1.7 问题引申
parallelStream()原理:
- parallerlStream是jdk8的特性,是在Stream的基础上实现的并行流式操作;旨在简化并行编码,提升运算效率;
- 并行流的底层是基于ForkJoinPool实现的,其中ForkJoinPool采用的思想类似MapReduce的思想,将一个大的运算任务拆分为子任务(fork的过程);然后执行所有的子任务运算后的结果合并在一起(join过程); 通过分治的方式完成一个计算;
1.8 parallelStream()最佳实践
1.8.1 并行流使用问题分析
- 根据parallelSteam的原理我们知道底层是使用的ForkJoinPool;那么我们程序通常会有如下代码:
//code1
WORDS.entrySet()
.parallelStream()
.sorted((a,b)->b.getValue().compareTo(a.getValue()))
.collect(Collectors.toList());
//code2
Set<String> words = new ConcurrentHashSet<>();
words1
.parallelStream()
.forEach(word -> words.add(word.getText()));
- 那么我们并没有创建ForkJoinPool,且不同的集合都在调用parallerStream(), 那么最终用的是哪个线程池呢?很显然既然没有报错,就说明jdk应该会给一个默认的ForkJoinPool。源码如下:
注意:
默认的如果使用默认的线程池执行的话,forkJoinPool会使用当前系统默认的cpu核心数量-1,但是主线程也会参与计算。
执行结果: 可以看出默认的ForkJoinPool线程池,除了worker线程参与运算 ,方法线程也会参与预算。
1.9 最佳实践总结:
- 并行流如果使用,最好使用自定义的线程池,避免使用默认的线程池即线程池隔离思想,造成阻塞或者资源竞争等问题;
- parallelStream 适用的场景是CPU密集型的,假如本身电脑CPU的负载很大,那还到处用并行流,那并不能起到作用,切记不要再paralelSreram操作是中使用IO流;
- 不要在多线程中使用parallelStream,如本次案例,大家都抢着CPU是没有提升效果,反而还会加大线程切换开销;
1.10 踩坑记录:
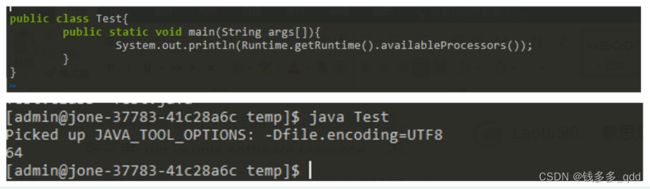
Runtime.getRuntime().availableProcessors() ;是jdk提供的获取当前系统的可用的核心数,本次踩坑在于,现在多数应用都是发布在容器中的,虽然应用部署的容器是2C4G的,但是ForkJoinPool创建的ForkJoinPool.commonPool-worker-线程却有几十个,登录容器所在的物理机查看机器配置如下:

实际为2个cpu每个cpu 32核 总共是64核,编写测试程序验证也是如此:
由此可知,默认的ForkJoinPool获取的是当前系统的核心数量,如果应用部署在docker容器中,那么就获取的是宿主机的CPU核心数。
1.11 Runtime.getRuntime().availableProcessors()问题
容器明明分配的是2个逻辑核心数,为什么java获取的会是物理机的核心数呢?如何解决这个问题呢。
是否是容器构建的时候某些参数配置的原因导致的? 将问题反馈给运维,但是对方并未解决该问题。
那么java是否可以解决呢?毕竟如果我们自定义线程池设置线程数量也会使用
Runtime.getRuntime().availableProcessors()这个方法,这其实是JDK的一个问题,已经trace在 JDK-8140793 ,原因是获取CPU核数是通过读取两个环境变量,其中:

其中_SC_NPROCESSORS_CONF 就是我们需要容器真实的CPU数量。
获取CPU数量的源码
第一种办法是使用新版本的Jdku131以上的版本 :
容器内获取CPU核数的坑
另外一个办法是使用自编译上面的源代码,通过LD_PRLOAD的方式将修改后的so文件加载进去Mock掉CPU的核数。
jdk官方链接声明: Java SE support for Docker CPU and memory limits
1.11.1 使用方法一测试:测试环境容器验证,验证通过,结果如下:
jdk版本 jdk1.8.0_20 :返回cpu核心数28
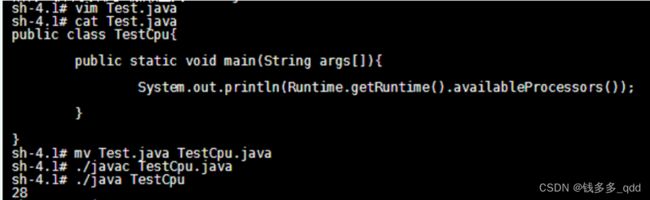
jdk版本: jdk-1.8.0_192 返回cpu核心数2

1.12 建议
尽量使用lambda表达式遍历数据,推荐使用常规的for、for-each模式
原因:
- 性能比传统foreach低;
lambda内部有着一套复杂的处理机制(反射、类型转换、拷贝),性能开销要比常规for、for-eatch大的多。在普通业务场景下这种性能差异可以忽略不计,但是在某些高频场景下(N万次调用/秒)就不能忽略了。它虽然不会导致一次迭代卡顿,但是会持续增加cpu的消耗,以及增加GC的压力。
- 不便于代码调试;
反例:
// lambda并没有起到简化代码的作用,反而会增加系统压力
List<ValidationResult> results = children.stream()
.map(e -> e.validate(context, nextCell, nextCoverCells, occupyAreas))
.collect(Collectors.toList());
List<ValidationResult> failureList =
results.stream().filter(ValidationResult::isFailure).collect(Collectors.toList());
List<ValidationResult> successList =
results.stream().filter(ValidationResult::isSuccess).collect(Collectors.toList());
正例:
// 优化后总cpu下降2%-4%左右。
// 备注:cpu下降如此明显的原因是该代码的调用频率非常高,真正的N万次/秒调用
List<ValidationResult> failureList = new ArrayList<>(4);
List<ValidationResult> successList = new ArrayList<>(4);
for (PathPreAllocationValidator child : children) {
ValidationResult result = child.validate(context, currCell, previousCell, nextCell);
if (result.isSuccess()) {
successList.add(result);
} else {
failureList.add(result);
}
}