常见优化思路
核心优化思路
多机并行:能够充分利用多机的资源
单机多核并行:能够充分利用单机上多核的资源
充分利用单核的性能:
3.1 减少 指令数:选择效率更好的执行策略,数据结果,算法 等
3.2 减少 每个指令需要的周期:SIMD, CPU Cache,分支预测 等
资源的视角
CPU
多核扩展性
Lock
分段
thread local
Lock Free
上下文切换
绑核
用户态线程
线程池
NUMA
Cache Line 伪共享
同步 VS 异步
单核性能
SIMD
分支预测
Cache Miss
C++ 优化点
经验法则
reserve memory for std::vector
编译器优化
函数传参时避免 copy
减少shared_ptr 的 copy
Avoid the compiler ever having to consider a potential call to malloc(), or any extern function, in hot loops.
avoid thread synchronisation anywhere inside a hot loop.
Keep collections of data in a single contiguous block of memory as much as possible
In multi-threading programming, sometimes copying blocks of data can be faster than sharing via a mutex. There are other benefits to this, such as avoiding data synchronisation pitfalls, deadlocks, priority inversions, etc.
Choose std::unordered_set/map over std::set/map
Choose std::streambuf and their variants over std::i/ostream when reading/writing lots of data.
std::unique_ptr over std::shared_ptr.
Evaluate things in constexpr if you can.
Make as many types as possible TriviallyCopyable.
用 lambda 代替 std function https://quick-bench.com/q/4IKpxAA5VEbXVziV1G2Po-ZupSE
std::fill 要注意模板的类型匹配 https://travisdowns.github.io/blog/2020/01/20/zero.html
Multiplying and shifting is a standard technique to emulate the division.
Final 去虚拟化
https://gcc.godbolt.org/z/16zMdjEjY
Virtual functions do not incur too much additional cost by themselves, The number one factor that is responsible for bad performance are data cache misses
Avoiding vector of pointers on a hot path is a must
Most overhead of virtual functions comes from small functions, they cost more to call than to execute
虚函数通常通过虚函数表来实现,在虚表中存储函数指针,实际调用时需要间接访问,这需要多一点时间。
然而这并不是虚函数速度慢的主要原因,真正原因是编译器在编译时通常并不知道它将要调用哪个函数,所以它不能被内联优化和其它很多优化,因此就会增加很多无意义的指令(准备寄存器、调用函数、保存状态等),而且如果虚函数有很多实现方法,那分支预测的成功率也会降低很多,分支预测错误也会导致程序性能下降。
Inline
memcpy
内存相关的操作对性能影响会比较大,memcpy 基础操作的优化点:
Prefetch:小数据量时使用
区分内存对齐和非内存对齐的 Copy,内存对齐的simd 指令会更快
Simd 指令加速:sse,avx,avx2,avx512 等指令
Overlapped: to copy the last 4 <= n <= 7 bytes: copy the first & last 4 bytes。 非对齐字节,
不同 szie 使用不同的策略:小于8,小于16,小于32,小于256,大于256 做不同的处理
绕过 CPU Cache,内存直接写,避免影响 CPU Cache
查表法:拷贝不同小尺寸内存,直接跳转到相应地址解除循环。
循环展开
汇编优化
几个系统的优化实现,代码里面的注释可以细读:
StarRocks: Improve performance of strings::memcpy_inlined https://github.com/StarRocks/starrocks/pull/13330/files
ClickHouse: https://github.com/ClickHouse/ClickHouse/pull/21520/files
folly: https://github.com/facebook/folly/blob/master/folly/memcpy.S
标准库: https://www.zhihu.com/question/35172305
memchr
https://gms.tf/stdfind-and-memchr-optimizations.html
memcmp
http://www.picklingtools.com/study.pdf
dpdk Implement memcmp using AVX/SSE instructio : http://patchwork.dpdk.org/project/dpdk/patch/[email protected]/
+/**
+ * Compare 16 bytes between two locations.
+ * locations should not overlap.
+ */
+static inline bool
+rte_cmp16(const uint8_t *src_1, const uint8_t *src_2)
+{
+ __m128i xmm0;
+ __m128i xmm1;
+ __m128i vcmp;
+ uint32_t vmask;
+
+ xmm0 = _mm_loadu_si128((const __m128i *)src_1);
+ xmm1 = _mm_loadu_si128((const __m128i *)src_2);
+
+ vcmp = _mm_cmpeq_epi16(xmm0, xmm1);
+ vmask = _mm_movemask_epi8(vcmp);
+ return (!(vmask == 0xffffU));
+}
memequal(类似 memcmp)
Loop Optimization
Unrolling
Resize No Initialize
Copy To Move
Std::vector
Code Layout
Compile-time Computation
查表法 Table Lookup
optimize harmonic mean evaluation in hll::estimate_cardinality
https://github.com/StarRocks/starrocks/pull/16351
Make your lookup table do more https://commaok.xyz/post/lookup_tables/
编译期运算 constexpr
#std::inplace_merge 代替 std::merge
std::inplace_merge 是原地 Merge,相比 std::merge 更省内存
https://github.com/StarRocks/starrocks/pull/14609
#用 std::variant 代替 polymorphism
#memory_resource 优化内存分配
http://quick-bench.com/kW0AAZlrPK0ubds9_ZMsEYvFnlI
高性能第三方库
fmt
https://github.com/fmtlib/fmt
https://www.zverovich.net/slides/2017-cppcon.pdf
llfio
https://github.com/ned14/llfio
asio
https://think-async.com/Asio/
zeromq
https://aosabook.org/en/v2/zeromq.html
https://zeromq.org/
nanomsg
https://github.com/nanomsg/nanomsg
phmap
https://github.com/greg7mdp/parallel-hashmap
roaringbitmap
https://roaringbitmap.org/
simdjson
https://github.com/simdjson/simdjson
不同的指令集
High-performance load-time implementation Selection:
https://github.com/CppCon/CppCon2022/blob/main/Presentations/Load-Time-Function-Selection.pdf
数学相关
Computing the number of digits of an integer even faster: https://lemire.me/blog/2021/06/03/computing-the-number-of-digits-of-an-integer-even-faster/
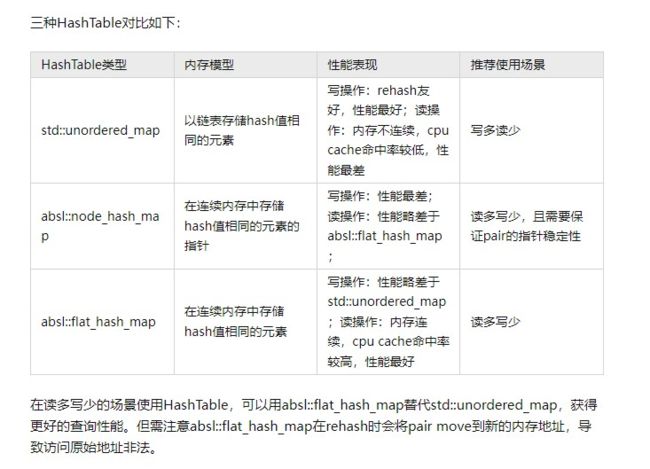
hashtable
https://zhuanlan.zhihu.com/p/614105687?utm_id=0
RPC 优化点
Local exchange pass through
线程模型的设计
# 全 polling 线程模型
# brpc 线程模型
内存管理
连接管理
池化
Batch 操作
用户态 TCP
Cache Miss 优化 (避免跨线程访问资源,保证 cache locally)
序列化
# ProtoBuf
# FlatBuffers
压缩和编码
Zero Copy
流量控制
RDMA
DPDK
参考资料
https://www.youtube.com/watch?v=A7PA37fxfp0&t=1981s
https://www.youtube.com/watch?v=fBpJNrSlQm8&t=1206s
Serverless 优化点
弹性
Scale Out 能力
虚拟化的影响
https://www.p99conf.io/session/cutting-through-the-fog-of-virtualization/
对象存储
并行扫描文件
自适应 IO 调度框架
重试(针对云存储的限额等报错,需要自动重试)
Local Cache 加速
资料
https://cloud.google.com/blog/products/data-analytics/inside-bigquerys-serverless-optimizations
SIMD
注意事项
AVX-512 is not always faster than AVX2. 原因是一些 CPU 可能会降频,还有编译器会 prefer 256-bit SIMD operations
SIMD 基础知识
What SIMD
SIMD Registers
Many Ways to Vectorize
Compile Auto Vectorize
How to Ensure SIMD Instructions Used
Vector Intrinsics
SIMD 优化案例
SIMD text parsing
SIMD data filtering
SIMD string operations
SIMD json
SIMD join runtime filter
SIMD hash table probe
SIMD memcpy
SIMD memcmp
SIMD memequal
SIMD case when
SIMD gather
SIMD branchless
SIMD filter (https://github.com/StarRocks/starrocks/pull/14328/files)
SIMD aggregate
SIMD string to integer parser (https://kholdstare.github.io/technical/2020/05/26/faster-integer-parsing.html)
SIMD std::find & memchr
SIMD std::find and memchr Optimizations (https://gms.tf/stdfind-and-memchr-optimizations.html)
如何更好地触发向量化
循环外提 https://github.com/StarRocks/starrocks/pull/14510
循环展开
多平台多SIMD指令兼容
https://github.com/milvus-io/knowhere/blob/main/src/simd/hook.cc
参考资料
https://15721.courses.cs.cmu.edu/spring2023/slides/08-vectorization.pdf
业务侧优化
数据建模
SQL 改写
#减少不必要的 Join
近似代替精确
抽样代替全量
多核并行优化点
并行执行模型
并行度自适应
线程池 Lock
SpinLock
分段锁 https://github.com/apache/doris/pull/3222
Lock Free
// 通过CAS操作实现Lock-free
do {
...
} while(!CAS(ptr,old_data,new_data ))
One way to avoid the ABA problem is to ensure that the head of the stack never has the same value twice.
The addition of a sleep reduced contention, and consequently both increased throughput while decreasing processor utilization.
https://www.singlestore.com/blog/common-pitfalls-in-writing-lock-free-algorithms/
#Lock-Free Queue
可以支持高效并发的写操作和较少的读操作。
无锁队列的基本思想是使用原子操作和 CAS(Compare-and-Swap)操作来实现并发安全的插入和删除操作,而无需使用显式的锁来保护共享数据。
#Epoch Based Reclamation
EBR 适用于读操作频繁、写操作相对较少且需要回收的内存区域较小的场景。
#Read-Copy Update (RCU)
它适用于读操作频繁、写操作相对较少且修改的数据较小的场景。
协程
避免阻塞等待
更高的并发性
减少上下文切换
更好的资源利用
Use Coroutines for Asynchronous I/O to Hide I/O Latencies and Maximize the Read Bandwidth
(https://db.in.tum.de/~fent/papers/coroutines.pdf?lang=en)
https://mp.weixin.qq.com/s/WbR7dN7wVdVEpB8wHBbxCw(仅花200行代码,如何将60万行的RocksDB改造成协程)
调度
优先级调整
用户态线程
异步
https://www.p99conf.io/session/speedup-your-code-through-asynchronous-programing/
CPU独占 (CPU exclusive)
当一个进程或任务独占CPU时,它独自占用CPU资源,没有其他进程或任务与其共享CPU核心。
这意味着其他进程或任务无法在同一时间片内使用该CPU核心。CPU独占通常用于要求高性能的任务,例如实时系统、高性能计算或需要大量计算资源的应用程序。通过将CPU独占分配给特定进程或任务,可以确保它们获得足够的计算能力。
CPU绑核 (CPU affinity)
CPU绑核可以将特定进程或任务绑定到特定的CPU核心上运行。 通过绑定,该进程或任务将只在指定的CPU核心上运行,不会在其他核心上执行。 这可以用于优化多线程或并行应用程序的性能,以减少因线程迁移和上下文切换而引起的开销。通过将特定的线程或进程绑定到特定的CPU核心,可以提高缓存利用率并减少共享资源竞争。
对 CPU Cache 友好
减少 上下文切换
资源隔离 Cgroups
Numa 优化
当有多个 Numa Node, 且内存的分配和回收是瓶颈时,可以考虑针对 Numa 架构进行优化。
CPU NUMA(Non-Uniform Memory Access)优化通常旨在优化多处理器系统中的内存访问性能。 可以考虑下面几个方面的优化:
内存本地性:NUMA 架构中,每个 CPU 都与一组本地内存相关联。优化内存本地性意味着将数据分配到与执行线程所在的 CPU 相对应的本地内存中。这可以减少远程内存访问的开销,提高内存访问速度和整体性能。
数据局部性:NUMA 架构中,处理器可以更快地访问本地内存,而远程内存的访问速度较慢。因此,优化数据局部性可以使访问模式更加局部化,减少跨 Node 的数据传输和远程内存访问。这可以通过使用本地缓存、数据预取和对齐内存访问等技术来实现。
任务和线程绑定:在 NUMA 系统中,将任务或线程绑定到特定的 CPU 可以提高内存访问性能。通过将任务绑定到与其本地内存相关联的 CPU,可以减少远程内存访问和数据传输,从而提高性能。这可以通过使用操作系统或编程语言级别的线程绑定功能来实现。
NUMA 感知调度 :操作系统和调度程序可以采用 NUMA 感知的调度策略,考虑处理器和内存的 NUMA 布局。通过将任务分配给与其本地内存相关联的处理器,可以减少远程内存访问的开销,提高系统整体的性能。
总而言之,CPU NUMA 优化的目标是最大程度地减少远程内存访问,以提高内存访问性能和整体系统性能。
当需要访问非本地的内存时,进行顺序访问,这样可以通过硬件的预取屏蔽 remote access latency.
内存分配
False Sharing
减少系统调用与上下文切换
存储层优化点
列存
索引
Hash 索引
B+ Tree 索引
Radix tree 索引
https://mp.weixin.qq.com/s/-lPJNRq4UdYYqeSpHPXfLg
前缀索引 
ZoneMap 索引 (块索引)
块级索引,是以块为单位,记录块内元数据的索引(最大值、最小值、空值、COUTN、SUM、相关性等)
BloomFilter 索引
Bitmap 倒排索引
StarRocks Bitmap Index Rationale  StarRocks 的 Bitmap Index 主要包括两部分内容:字典和 Bitmap 行号。 字典保存了原始值到编码 Id的映射,Bitmap 索引记录了每个编码 ID 到 Bitmap 行号的映射。
StarRocks 的 Bitmap Index 主要包括两部分内容:字典和 Bitmap 行号。 字典保存了原始值到编码 Id的映射,Bitmap 索引记录了每个编码 ID 到 Bitmap 行号的映射。
StarRocks Bitmap Index Storage Format  如上图所示,StarRocks 的字典部分和 Bitmap 行号部分都是以 Page 的格式存储,同时为了减少内存占用和加速索引,StarRocks 对字典和 Bitmap 的 Page 都建立了索引。
如上图所示,StarRocks 的字典部分和 Bitmap 行号部分都是以 Page 的格式存储,同时为了减少内存占用和加速索引,StarRocks 对字典和 Bitmap 的 Page 都建立了索引。
当然,如果建 Bitmap 索引列的基数很低,Dict Data Page 和 Bitmap Data Page 只有一个的话,我们就不需要 Dict Index Page 和 Bitmap Index Page。
Operation On Encode Data
当 StarRocks 利用 Bitmap Index 进行过滤的时候,只需要先加载 Dict Index Page 和部分 Dict Data Page 即可,按照字典值进行快速过滤,无需解码数据,也无需把所有 Bitmap Data Page 一次性加载进来。
综上,由于 StarRocks 支持Bitmap 索引的索引和支持按照字典值进行快速过滤,即使 Bitmap Index 列的基数很高,Bitmap Index 整体磁盘存储很大,内存占用也很小。
Bitmap 索引内存缓存  StarRocks 会保证所有的 Dict Index Page 和 Bitmap Index Page 一定在内存,并让尽可能多的 Dict Data Page 和 Bitmap Data Page 在内存,并保证 Bitmap Index 相关的 Page Cache 不被 Column 的数据冲掉。
StarRocks 会保证所有的 Dict Index Page 和 Bitmap Index Page 一定在内存,并让尽可能多的 Dict Data Page 和 Bitmap Data Page 在内存,并保证 Bitmap Index 相关的 Page Cache 不被 Column 的数据冲掉。
这样在点查结果集较小的情况下,即使是第一次 Cold Query,StarRocks 也可以做到只需要一次 Disk Seek。
自适应 Bitmap 索引 当 StarRocks 发现 Bitmap 索引的选择度不高,需要 Seek 很多 Data Page 时,我们就会放弃使用 Bitmap 索引,直接顺序 Scan。
让索引常驻内存
物化列
Cache
多级 Cache RaptorX: Building a 10X Faster Presto
https://prestodb.io/blog/2021/02/04/raptorx
Metastore Versioned Cache
File List cache
Fragment Result Cache
File Descriptor and Footer Cache
Alluxio Data Cache
写入绕过 Cache
TencentCLS: The Cloud Log Service with High Query Performances
https://www.vldb.org/pvldb/vol15/p3472-yu.pdf
vm.dirty_background_ratio vm.dirty_expire_centisecs
异步 IO
IO异步化对于高性能的网络编程、服务器应用程序、多线程和多进程编程等场景非常有用,可以避免因IO阻塞而导致的资源浪费和性能瓶颈。它允许程序更加高效地利用计算资源,并提高系统的并发能力和响应性能。
https://www.vldb.org/pvldb/vol15/p3496-lakshman.pdf
https://db.in.tum.de/~fent/papers/coroutines.pdf?lang=en
IO 多路复用
IO 并行度 自适应
IO 调度
Scan 优先级
Shared Scan
延迟物化
Segment 大小 / 文件大小
https://www.databricks.com/blog/how-databricks-improved-query-performance
文件的个数
太多的文件往往意味着太多的 IO 次数
文件的版本数
动态文件裁剪  数据局部性
数据局部性
压缩
Gzip
LZ4
Brotli
SNAPPY
ZSTD
BZIP2
编码
预取
Runtime filter
表达式下推存储层
Compaction
Prefetch or Predictive Pipelining
根据访问模式,提前从存储层读取所需要的数据。 在存储分离的架构,合理地 Prefetch S3 等分布式存储的文件,对 Scan 性能的优化更明显
https://www.databricks.com/blog/announcing-general-availability-predictive-io-reads.html
硬件 NVMe
Is Sequential IO Dead In The Era Of The NVMe Drive?
https://jack-vanlightly.com/blog/2023/5/9/is-sequential-io-dead-in-the-era-of-the-nvme-drive
数据库中的各种 Cache
Cache 类型
Columnar Disk Caching
In-Memory Block Caching
Near-CPU Data Caching
Cube Relational Caching
Arbitrary Relational Caching
MetaData Cache
统计信息的 Cache
Query Result Cache
Cache 系统的问题
缓存穿透
缓存击穿
缓存雪崩
Cache 设计考虑点
Cache Unit
Cache Key
Cache Value
Cache Format
Cache Policy
Cache Metadata
Cache Storage
Cache 的一致性
Cache 的更新策略
Write-through
Post write
Write back
资料:
https://www.usenix.org/system/files/atc22-yang-tzu-wei.pdf
数据建模
表的模型 / 类型
明细模型
聚合模型
更新模型
主键模型
行存 VS 列存
分区
分桶
SortKey
数据类型
Nullable
查询优化器优化点
Parser 优化
Nullable 优化
Null 和 Nullable 是数据库中比较容易出错的点, Null 相关的很多逻辑都需要特殊处理,比如 Join, 聚合等算子,一些函数,谓词,四则运算 和 逻辑运算等。 而在向量化执行中, Null 和 Nullable 对性能的影响也很大。
Nullable 对性能的影响主要是两点:
null 需要特殊判断,可能会需要很多 if else , 导致一些地方不能向量化和分支预测错误
null 的数据需要占一个 column 或者 bitmap,会有额外的存储和计算开销。
StarRocks 对 Nullable 的优化主要体现在下面几点:
优化器对 Nullable 熟悉进行判断,如果可以确定表达式的结果一定是 Non-nullable 的,就会告诉执行层这个信息,这样执行层处理时完全不需要考虑 Null。比如 StarRocks 的这个PR: https://github.com/StarRocks/starrocks/pull/15380/files 当确定 cast 一定可以成功,且输入是 Non-nullable 的column时,结果就一定是 Non-nullable 的
利用 has_null 标识进行快速短路,如果一个chunk 里面的数据都没有null,就走 Non-nullable 的处理逻辑,在很多算子和函数中可以看到大量这种优化
利用 SIMD 指令快速对 全是 null 和 全不是 null 的 case 进行处理,在 StarRocks 的nullable_aggregate.h 可以看到大量这种优化
在表达式计算中,对 null 的 数组和 data 的数组分别进行向量化处理。
元数据优化
In Memory MetaData
利用元数据加速查询
全表 Count, Sum, Max, Min 的聚合查询可以直接从元数据查询 https://github.com/StarRocks/starrocks/pull/15542
利用元数据加速 统计信息计算的查询
Small Materialized Aggregates: A Light Weight Index Structure for Data Warehousing
https://www.vldb.org/conf/1998/p476.pdf
利用元数据改写查询 
Big Metadata: When Metadata is Big Data
http://vldb.org/pvldb/vol14/p3083-edara.pdf
分区分桶裁剪
常见的RBO 优化
各种表达式的重写和化简
Cast 消除
谓词化简
公共谓词提取
列裁剪
Shuffle 列裁剪 (确保任何多余的列不要参与网络传输)
谓词下推
等价谓词推导(常量传播)
Outer Join 转 Inner Join
Limit Merge
Limit 下推
聚合 Merge
Intersect Reorder
常量折叠
公共表达式复用
子查询改写
Lateral Join 化简
Empty Node 优化
Empty Union, Intersect, Except 裁剪
In 转 Semi Join 或者 Inner Join (http://mysql.taobao.org/monthly/2023/01/01/)
聚合算子复用
# 比如对于下面的 SQL:
# SELECT AVG(x), SUM(x) FROM table
#我们可以让 AVG(x) 复用 SUM(x) 的计算结果,减少计算量
Primary Key 相关优化
冗余 Group By 消除
Sum 常量转 Count
常见的 CBO 优
多阶段聚合优化
Join 左右表 Reorder
Join 多表 Reorder
Join 分布式执行选择
Shuffle Join
Broadcast Join
Bucket Shuffle Join
Colocate Join
Replication Join
Join 和 Aggregate Runtime Colocate, 避免 Shuffle
CTE 复用
CTE 列裁剪
Agg 上拉
Agg 下推 Join
Agg 下推 GroupingSets
窗口下推 Group By
算子融合
物化视图选择与改写
利用基数信息进行优化
统计信息
统计信息的收集方式
统计信息的收集频率
统计信息 Cache
查询执行器优化点
多机执行模型
多核执行模型
单核执行模型
SIMD (https://perf.bcmeng.com/4%20optimization-points/simd.html)
多核并行优化点 (https://perf.bcmeng.com/4%20optimization-points/multi-core.html)
C++ Low Level (https://perf.bcmeng.com/4%20optimization-points/c-plus-plus.html)
列式布局
Batch 操作
按列处理
Shuffle By Column
虚函数调用
查询调度器优化点
Fragment 批量投递
Fragment 元数据 Cache
延迟调度
亲和性调度 Soft Affinity Scheduling
感知负载的调度
查询准入控制
CTE 调度优化
Union 调度优化
本文由 mdnice 多平台发布