java8 stream运行原理之顺序流原理详解
接下来将通过两篇文章介绍stream的原理,本文介绍顺序流,下篇文章介绍并行流。
一、顺序流原理总述
下图是Stream的继承结构:
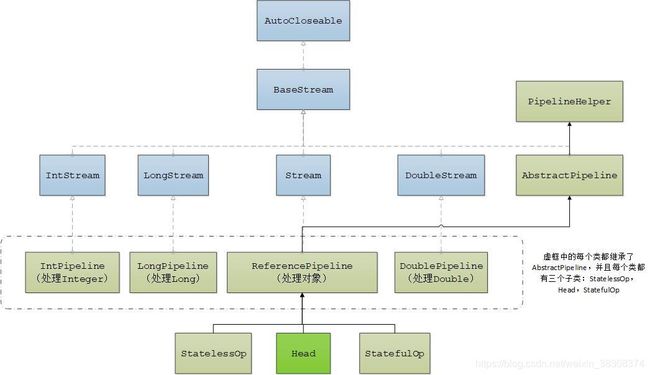
蓝框表示接口,灰框表示抽象类,绿框表示非抽象类。
因为Integer、Double、Long比较常用且特殊,java8提供了专门的Stream类。不过这三个类的原理与ReferencePipeline是一样的,本文接下来就以ReferencePipeline为例做介绍。
ReferencePipeline是最常用的流对象,一般使用的流对象都是该类。该类是抽象类,它有三个子类,分别是StatelessOp、StatefulOp、Head,前面两个类表示操作类型,分别表示无状态操作和有状态操作。java将流经过的操作组装成一个链表,这个链表的头结点就是Head对象,Head对象不表示任何操作,仅仅标示一个流的开始,之后的中间操作分为有状态的和无状态的,最后一个终端操作使用TerminalOp表示,在这个链条上每创建一个操作对象,便使用该对象的属性previousStage记录前一个操作对象的引用,同时也会更新前一个操作的nextStage属性值为当前操作对应的引用,最后形成下图的链表,注意终端操作并没有接到链表上:

当创建了TerminalOp对象之后,便要从TerminalOp对象开始向前遍历每个操作对象,将每个操作对象转换为Sink对象,这样每个元素需要的操作处理就从操作对象转换到了Sink对象上。Sink对象也会形成一个链表,每个Sink对象里面有一个属性downstream记录了当前操作的后一个Sink对象。Head没有对应的Sink对象,就上图来说,Sink对象形成的链表头结点是StatefulOp对应的节点,上图形成的Sink对象链表如下图:

Sink对象链表创建好后,接下来就开始遍历每个元素,对元素执行Sink对象链表上的每个操作。当执行完后,就可以得到本次流操作的结果。
下图是Sink和TerminalOp的继承关系图:
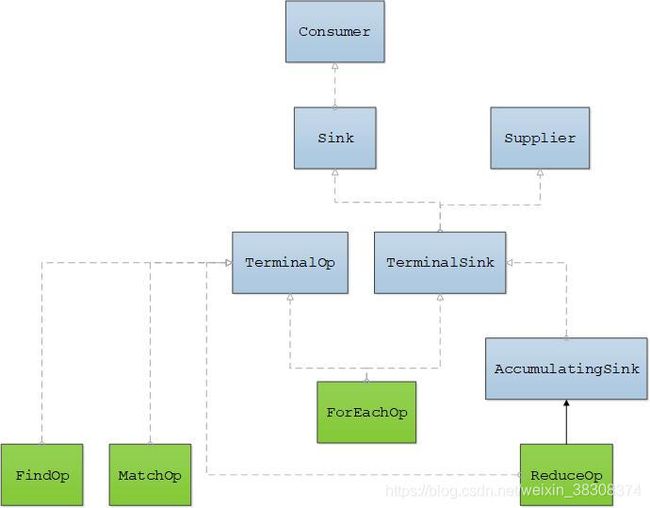
蓝框表示接口,绿框表示非抽象类。collect()/max()/min()/count()这几个终端操作从上图没有找到对应的Op类,其实它们都归属到了ReduceOp类中。
Sink接口对所有操作都提供了对应的实现类,只不过有些实现类有类名字,有些是内部匿名类,没有类名字,我没有在上图一一画出这些实现类。
除了Sink、Stream之外,还有一个大的集成体系,那便是Spliterator继承结构:
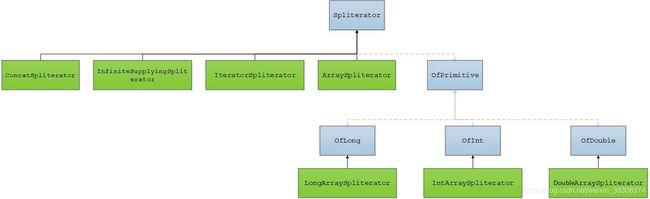
Spliterator是一个分离器,数据流的源便保存在分离器中,分离器提供了一些方法,包括遍历流中的元素,检查是否还有未处理元素,流中元素的总个数等。
如果数据源是一个数组,该数组对象会保存到ArraySpliterator对象中;如果是集合或者Iterator,那么便使用IteratorSpliterator保存;如果使用Stream.concat()融合两个流,分离器使用ConcatSpliterator;如果使用Stream.generate()创建流,分离器使用InfiniteSupplyingSpliterator。
除了上面这些类之外,java还提供了一些工具类,这些类里面主要是静态方法:

二、源码分析
public static void main(String argv[]){
Stream<String> stream=Stream.of("1","2","","123");
stream.filter(x->x.length()>=1).forEach(System.out::println);
}
下面我以上述代码为例介绍Stream源码的执行过程。
1、Stream.of()
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
Stream.of()的入参为数组,里面将请求传给Arrays,最终调用到Arrays.stream()方法上,
//startInclusive是数组的开始下标,在本例中是0,
//endExclusive是数组的结束下标,在本地中是数组的长度
public static <T> Stream<T> stream(T[] array, int startInclusive, int endExclusive) {
//最后的入参表示是否是并行流
return StreamSupport.stream(spliterator(array, startInclusive, endExclusive), false);
}
在Arrays.stream()里面首先要调用spliterator()方法创建一个Spliterator对象:
public static <T> Spliterator<T> spliterator(T[] array, int startInclusive, int endExclusive) {
//创建Spliterator对象
//spliterator()的最后一个入参表示本分离器的特征:结构上不可变,元素与元素之间关联有序
return Spliterators.spliterator(array, startInclusive, endExclusive,
Spliterator.ORDERED | Spliterator.IMMUTABLE);
}
//下面这个方法是Spliterators.spliterator()
public static <T> Spliterator<T> spliterator(Object[] array, int fromIndex, int toIndex,
int additionalCharacteristics) {
//对入参做合法性校验
checkFromToBounds(Objects.requireNonNull(array).length, fromIndex, toIndex);
//创建ArraySpliterator对象
return new ArraySpliterator<>(array, fromIndex, toIndex, additionalCharacteristics);
}
//ArraySpliterator的构造方法
public ArraySpliterator(Object[] array, int origin, int fence, int additionalCharacteristics) {
this.array = array;
this.index = origin;
this.fence = fence;
//特征值增加两个:元素个数已知,且对数据源做任意切分,元素个数都是已知的
this.characteristics = additionalCharacteristics | Spliterator.SIZED | Spliterator.SUBSIZED;
}
创建出Spliterator对象后,下面要执行StreamSupport.stream()方法:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
//创建出Head对象,也就是操作对象链表的头结点,最后一个入参表示是否是并行流
//Head对象继承自AbstractPipeline,创建Head对象构造方法调用AbstractPipeline
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
//AbstractPipeline类的构造方法
AbstractPipeline(Spliterator<?> source,
int sourceFlags, boolean parallel) {
this.previousStage = null;//前一个操作对象引用,这里是null
this.sourceSpliterator = source;//分离器,持有分离器也就持有了数据源
this.sourceStage = this;//当前操作对象
this.sourceOrOpFlags = sourceFlags & StreamOpFlag.STREAM_MASK;//特征值
this.combinedFlags = (~(sourceOrOpFlags << 1)) & StreamOpFlag.INITIAL_OPS_VALUE;
this.depth = 0;//表示操作链表的深度
this.parallel = parallel;//是否是并行流
}
Stream.of()方法最后创建出Head对象,并将Head对象返回给调用方。
2、stream.filter()
filter()是一个无状态的操作,因此执行该方法时,内部创建一个StatelessOp对象:
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
//StatelessOp继承自AbstractPipeline,创建StatelessOp对象需要调用AbstractPipeline的构造方法
//注意:这里的this是Head对象
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
//当执行到终端方法时,使用下面的方法将当前操作对象转换为Sink对象
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
//下面是AbstractPipeline的构造方法
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;
this.previousStage = previousStage;//记录前一个操作,形成一个双向链表
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);//融合特征值
this.sourceStage = previousStage.sourceStage;//sourceStage记录的是Head对象的引用
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;//记录当前链表的深度
}
3、stream.forEach()
public void forEach(Consumer<? super P_OUT> action) {
evaluate(ForEachOps.makeRef(action, false));
}
先来看一下ForEachOps.makeRef():
public static <T> TerminalOp<T, Void> makeRef(Consumer<? super T> action,
boolean ordered) {
Objects.requireNonNull(action);
//创建一个ForEachOp对象,OfRef继承自ForEachOp
//OfRef内部属性会记录action引用
return new ForEachOp.OfRef<>(action, ordered);
}
创建完ForEachOp对象之后,接下来执行stream.evaluate()方法:
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
//因为是顺序流,接下来执行terminalOp.evaluateSequential()
//注意:这里的this对象是前面filter()方法创建出的StatelessOp对象
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
//下面是terminalOp.evaluateSequential()方法
//helper是filter()方法创建出的StatelessOp对象
//this是ForEachOp对象
public <S> Void evaluateSequential(PipelineHelper<T> helper,
Spliterator<S> spliterator) {
return helper.wrapAndCopyInto(this, spliterator).get();
}
//下面是helper.wrapAndCopyInto()
//入参sink是ForEachOp对象,ForEachOp实现了Sink接口
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
在wrapAndCopyInto()方法里面调用了两个很关键的方法wrapSink()和copyInto(),前者负责创建Sink对象链表,后者负责对每个元素执行Sink链表上的操作,注意调用的这两个方法属于StatelessOp对象,也就是filter()创建的对象,下面首先来看wrapSink()方法:
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
//从操作对象链表的最后开始向前遍历,因为Head对象的depth=0,所以遍历不会访问到Head
//opWrapSink()将每个操作转换为Sink对象,然后将Sink作为入参接着向下传递
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
//下面会以filter操作对象的opWrapSink()方法为例做介绍
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
//下面是filter()方法里面创建StatelessOp对象时实现的方法,这个在上面已经展示过了
//为了方便看,再展示一遍
//下面这个方法将filter的StatelessOp操作对象转换为Sink对象
//ChainedReference是Sink接口的抽象类
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
//predicate是过滤条件,也就是filter()方法的入参
if (predicate.test(u))
downstream.accept(u);
}
};
}
//下面是ChainedReference构造方法,使用属性downstream记录Sink对象链表上下一个Sink对象
public ChainedReference(Sink<? super E_OUT> downstream) {
this.downstream = Objects.requireNonNull(downstream);
}
wrapSink()遍历操作对象链表,将每个操作对象转换为Sink对象,使用属性downstream记录下一个Sink对象,这样形成一个Sink对象链表,将链表传递给copyInto()方法。
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
//下面这个if判断是检查终端操作是否是短路操作
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
//调用Sink链表上每个begin()方法,表示下面要开始遍历流中的数据了
wrappedSink.begin(spliterator.getExactSizeIfKnown());
//forEachRemaining()用于遍历每个元素,入参为Sink链表
spliterator.forEachRemaining(wrappedSink);
//调用Sink链表上每个end()方法
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
下面是spliterator.forEachRemaining()方法:
public void forEachRemaining(Consumer<? super T> action) {
Object[] a; int i, hi; // hoist accesses and checks from loop
if (action == null)
throw new NullPointerException();
//下面的while循环遍历每个元素
if ((a = array).length >= (hi = fence) &&
(i = index) >= 0 && i < (index = hi)) {
//action对象是Sink链表上的头结点,也就是filter操作对应的Sink对象
do { action.accept((T)a[i]); } while (++i < hi);
}
}
//下面是filter操作对应的Sink对象的accept()方法
//这个方法在介绍wrapSink()时已经展示过,它是在创建Sink对象时使用匿名内部类实现的
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
//downstream()是Sink对象链表上的下一个Sink对象,
//如果符合filter条件便将元素交给下一个Sink处理
downstream.accept(u);
}
到这里为止,按照本小节的例子介绍了一遍执行流程,其他的Stream方法执行流程都是类似的,大家可以参考本小节的内容了解其他方法。
从上面的源码可以看到,对流进行处理是在最后执行终端方法时才进行的。