linux正则表达式及文本处理三剑客grep、sed、awk
目录
Linux正则表达式
Linux文本处理三剑客之grep
Linux文本处理三剑客之sed
Linux文本处理三剑客之awk
Linux正则表达式
Linux核心通配符:
*:匹配任意长度的任意字符
?:匹配任意单个字符
[ ]:匹配指定范围内的任意单个字符
[ ^ ]:匹配指定范围外的任意单个字符
Linux文本处理三剑客之grep
grep:(全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来。
作用:文本搜索工具,根据用户指定的“模式(过滤条件)”对目标文本逐行进行匹配检查;打印匹配到的行;模式:由正则表达式的元字符及文本字符所编写出的过滤条件;
用法:
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
选项OPTIONS:
--color=auto 对匹配到的文本进行高亮显示
-E:支持使用扩展正则表达式
-i:忽略大小写
-o:仅仅显示匹配到的字符串本身
-n:显示行号
-v:显示不能被匹配到的行
-A num:后num行
-B num:前num行
-C num:前后num行
grep -w : 使grep命令只查找作为一个词,而不是词的一部分去做匹配
[root@localhost tmp]# grep 'tom' /etc/passwd
tom:x:1000:1000::/home/tom:/bin/bash
tomnew:x:1001:1001::/home/tomnew:/bin/bash
[root@localhost tmp]# grep -w 'tom' /etc/passwd
tom:x:1000:1000::/home/tom:/bin/basLinux文本处理三剑客之sed
sed是一种新型的、非交互的编辑器。
sed工作原理:
sed编辑器逐行处理文件(或输入),并将输出结果发送到屏幕。sed把当前正在处理的行保存在一个临时缓冲区中(这个缓冲区称为模式空间或临时缓冲),sed处理完模式空间中的行后(即在该行上执行sed命令后),就把该行发送到屏幕上。sed处理完文件的最后一行后,sed便结束运行。sed把每一行都存在模式空间中,对这个副本进行编辑,所以不会修改或破坏原文件。
sed用法(按行处理)
sed [OPTION]... {script-only-if-no-other-script} [input-file]...
option
-n:不输出模式空间中的内容到标准输出
-e:多点编辑
-f file:
-r:支持扩展正则表达式
-i:直接编辑源文件 {script-only-if-no-other-script}
地址定界:
1、空地址:代表整个文件
2、指定地址 #:指定的行 /pattern/:匹配到的行
3、地址范围 #,# #,+# #,/pattern/ /pattern/,# /pattern1/,/pattern2/
4、1~2,代表所有奇数行 2~2,代表所有偶数行 1~#,间隔#行
5、$行尾
分界符 @ 、^、 、!、 |
编辑命令
d:删除
p:显示模式空间中的内容
a:在行后
i:在行前
w /path/to/somefile :把模式空间中匹配到的行保存到指定的文件
=:为模式匹配到的行打印行号
r /path/to/somefile:
!:
s/old/new/g:查找替换@@@ ###
g 全局替换
高阶用法
保持空间、模式空间
高阶命令
显示偶数行 sed -n 'n;p'
逆序显示文件内容
取出最后一行 sed '$!'
显示奇数行 sed 'n;d'
在原有的每行后加一行空白行
[root@localhost ~]# sed -n "n;p" /etc/passwd(显示偶数行)
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
halt:x:7:0:halt:/sbin:/sbin/halt
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
systemd-network:x:192:192:systemd Network Management:/:/sbin/nologin
polkitd:x:999:998:User for polkitd:/:/sbin/nologin
postfix:x:89:89::/var/spool/postfix:/sbin/nologin
Linux文本处理三剑客之awk
awk是一种编程语言
语法结构
awk options commonds filename
 options
options
-F:定义分隔符 默认是制表符 tab
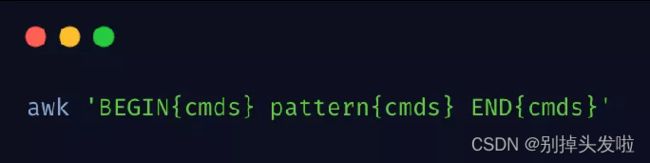
commonds 'BEGIN{} /pattern/{body} END{}'
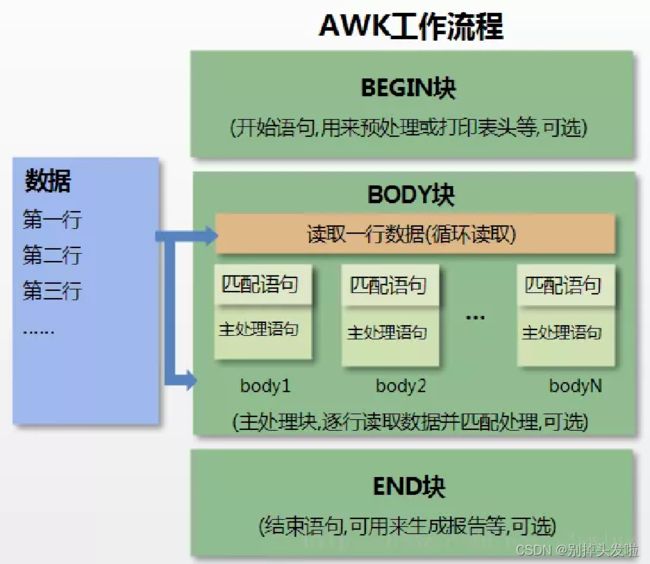
要时刻记着:BEGIN 是预处理阶段, body 是 awk 真正工作的阶段,END 是最后处理阶段。
- 首先,执行关键字 BEGIN 标识的 {} 中的命令;
- 其次,完成 BEGIN 大括号中命令的后,开始执行 body命令;
- 逐行读取数据,默认读到 \n 分割的内容为一条 记录,其实就是行的概念;
- 将记录按照指定的分隔符划分为字段,其实就是 列的概念;
- 循环执行 body 块中的命令,每读取一行,执行一 次 body,最终完成 body 执行;
- 最后,执行 END 命令,通常会在 END 中输出最后 的结果;
awk中,$0 代表行记录 $1----$#每个字段 最多100个字段 显示时默认以空格为分割符, 内部变量 FS默认是空格 awk在输出的时候 print
内置变量:
FS:输入字段的分隔符,默认为空格,多个空白字符
OFS:输出字段分隔符
ORS:输出记录分隔符
RS:输入记录分隔符,默认是换行符
NF:字段数
NR:已经读入的记录中的行号,在body区域 和END区域内容显示有区别
FNR:输入文件的记录数
FILENAME:当前处理文件的文件名
字符串变量
\n 换行符
\t 水平制表符
\v 垂直制表符
变量:
自定义变量
变量自增自减 ++$1 $1++ --$1 $1--
一元操作 -$1 +$1 算数操作 +-*/%
字符串操作
赋值操作
=
+=
*= /= %=
比较操作
>,>=,<,<=,==,!=,&&,|| 精确匹配
~,!~ 模糊匹配
编程语言
循环 分支判断
if
单个if
if-else
awk -f awk.file
BEGIN{
FS=":"
}
{
if($4<=50000)
print $2,"is less than 50000!"
else
print $2,"is more than 50000!"
}
# awk 'BEGIN{FS="[,:%]"} {if($4 <= 50000) {print $2,"is less than 50000" }
else {print $2,"is more than 50000"}}' file
if-else if
BEGIN{
FS="[,:%]";print "-----------" }
{ if($4 <30000)
print $2,"is less than 30000"
else if($4 > 60000)
print $2,"is more than 60000"
else
print $2,"XXXXXXXX"
}
END{
print "--------"
}
# awk 'BEGIN{FS="[,:%]"} {if($4 < 30000) {print $2,"is less than 50000" }
else if($4 > 60000) {print $2 } else {print $2,"is more than 50000"}}' file
格式化输出 printf