Map集合
1. 认识map集合:
- Map集合称为双列集合,格式:{key1=value1 , key2=value2 , key3=value3 , ...}, 一次需要存一对数据做为一个元素.
- Map集合的每个元素“key=value”称为一个键值对/键值对对象/一个Entry对象,Map集合也被叫做“键值对集合”
- Map集合的所有键是不允许重复的,但值可以重复,键和值是一一对应的,每一个键只能找到自己对应的值
2. 使用场景
- 需要存储一一对应的数据时,就可以考虑使用Map集合来做
3. map集合体系
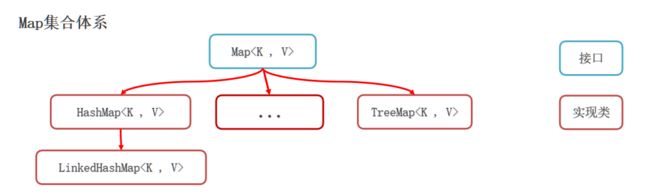
4. Map集合体系的特点
注意:Map系列集合的特点都是由键决定的,值只是一个附属品,值是不做要求的
- HashMap(由键决定特点): 无序、不重复、无索引; (用的最多)
- LinkedHashMap (由键决定特点):由键决定的特点:有序、不重复、无索引。
- TreeMap (由键决定特点):按照大小默认升序排序、不重复、无索引。

示例(使用HashMap演示上面的方法):
Map map = new HashMap<>();
//1.添加元素
map.put("张三",1000);
map.put("坤子",1020);
map.put("李四",1900);
System.out.println(map);
//2.获取集合的大小
System.out.println(map.size());
//3.清空结婚
// map.clear();
// System.out.println(map);
//4.判断集合元素是否为空,空返回true,反之返回false
System.out.println(map.isEmpty());
//5.根据键获取值
System.out.println(map.get("张三"));
//6.根据建删除整个元素
map.remove("坤子");
System.out.println(map);
//7.判断是否包含某个键
System.out.println(map.containsKey("李四"));
//8.判断是否包含某个值
System.out.println(map.containsValue(1900));
//9.获取全部键的集合
Set set = map.keySet();
System.out.println(set);
//10.获取Map集合的全部值
Collection val = map.values();
System.out.println(val);
5. Map集合的遍历方式
- 方式一(键找值)
- 先获取Map集合全部的键,再通过遍历键来找值
| 方法名称 |
说明 |
| public Set |
获取所有键的集合 |
| public V get(Object key) |
根据键获取其对应的值 |
- 示例
package com.itheima.demo04;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Test01 {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("郭靖", "黄蓉");
map.put("杨过", "小龙女");
map.put("张无忌", "赵敏");
map.put("张翠山", "殷素素");
Set keys = map.keySet();
for (String key : keys) {
String value = map.get(key);
System.out.println(key + "===>" + value);
}
}
} - 方式二(键值对)
- 把“键值对“看成一个整体进行遍历(难度较大)
package com.itheima.demo04;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class Test02 {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("郭靖", "黄蓉");
map.put("杨过", "小龙女");
map.put("张无忌", "赵敏");
map.put("张翠山", "殷素素");
Set> entries = map.entrySet();
for (Map.Entry entry : entries) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "===>" + value);
}
}
} - 方式三(Lambda表达式)
- 使用Lambda表达式 (参数)->{方法体}
示例:(使用BiConsumer接口)
package com.itheima.demo04;
import java.util.HashMap;
import java.util.Map;
import java.util.function.BiConsumer;
public class Test03 {
public static void main(String[] args) {
Map map = new HashMap<>();
map.put("郭靖", "黄蓉");
map.put("杨过", "小龙女");
map.put("张无忌", "赵敏");
map.put("张翠山", "殷素素");
map.forEach(new BiConsumer() {
@Override
public void accept(String s, String s2) {
System.out.println(s + "===>" + s2);
}
});
System.out.println("----------------------");
map.forEach((k, v) -> {
System.out.println(k + "==>" + v);
});
}
} 综合案例:
- 统计投票人数
某个班级8名学生,现在需要组织秋游活动,班长提供了四个景点依次是(大理、漓江、泰山、泰国),每个学生只能选择一个景点,请统计出最终哪个景点想去的人数最多。
package com.itheima.demo04;
import java.util.*;
public class Demo {
public static void main(String[] args) {
//1.创建集合存储所有投票结果
List list = new ArrayList<>();
//2.创建一个数组存储景点
String[] select = {"大理", "漓江", "泰山", "深圳"};
Random r = new Random();
//3.for循环模拟学生投票
for (int i = 0; i < 80; i++) {
int index = r.nextInt(4);
//3.1将投票的结果存到集合中
list.add(select[index]);
}
System.out.println(list);
//4.创建一个HashMap集合来存储景点和投票数
Map result = new HashMap<>();
//5、将投票结果put到result里面
for (String s : list) {
if (result.containsKey(s)) { //如果集合中存在了这个景点,在票数上加1
result.put(s, result.get(s) + 1);
} else { //第一次遍历到景点直接赋值为1
result.put(s, 1);
}
}
System.out.println(result);
}
} 6. HashMap
- HashMap跟HashSet的底层原理是一模一样的,都是基于哈希表实现的。
- JDK8之前,哈希表 = 数组+链表
- JDK8开始,哈希表 = 数组+链表+红黑树
- 哈希表是一种增删改查数据,性能都较好的数据结构。
- 如果键存储的是自定义类型的对象,可以通过重写hashCode和equals方法,这样可以保证多个对象内容一样时,HashMap集合就能认为是重复的。
- HashMap的键依赖hashCode方法和equals方法保证键的唯一
- 示例:
package com.itheima.demo05;
import java.util.Objects;
//定义学生类,包含name和age属性
public class Student {
private String name;
private int age;
//重写equals()和hashCode()方法去重
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && name.equals(student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
/**
* 获取
* @return name
*/
public String getName() {
return name;
}
/**
* 设置
* @param name
*/
public void setName(String name) {
this.name = name;
}
/**
* 获取
* @return age
*/
public int getAge() {
return age;
}
/**
* 设置
* @param age
*/
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "Student{name = " + name + ", age = " + age + "}";
}
}
//测试类
import java.util.HashMap;
import java.util.Map;
public class Test {
public static void main(String[] args) {
Student s1 = new Student("张三",23);
Student s2 = new Student("李四",24);
Student s3 = new Student("王五",25);
Student s4 = new Student("张三",23);
Map map = new HashMap<>();
map.put(s1,"广东");
map.put(s2,"哈尔滨");
map.put(s3,"广西");
map.put(s4,"湖南");
map.forEach((k,v)->{
System.out.println(k+" ==> "+v);
});
}
}
7. LinkedHashMap
- 底层数据结构依然是基于哈希表实现的,只是每个键值对元素又额外的多了一个双链表的机制记录元素顺序(保证有序)。
- 有序、不重复、无索引。
8. TreeMap
- 特点:不重复、无索引、可排序(按照键的大小默认升序排序,只能对键排序)
- 原理:TreeMap跟TreeSet集合的底层原理是一样的,都是基于红黑树实现的排序。
8.1. TreeMap集合同样也支持两种方式来指定排序规则
- 让类实现Comparable接口,重写比较规则。
- TreeMap集合有一个有参数构造器,支持创建Comparator比较器对象,以便用来指定比较规则。
9. 集合嵌套
- 示例
package com.itheima.demo07_集合嵌套;
import java.util.*;
public class Demo {
public static void main(String[] args) {
// 1. 我们需要先定义一个Map集合,用于存放所有的省份 及其 城市
Map> map = new HashMap<>();
// 2.我们需要给每一个省份对应的城市 弄一个集合存放
// 江苏省的城市
List cities1 = new ArrayList<>();
Collections.addAll(cities1, "南京市", "扬州市", "苏州市", "无锡市", "常州市");
List cities2 = new ArrayList<>();
Collections.addAll(cities2, "武汉市", "孝感市", "十堰市", "宜昌市", "鄂州市");
List cities3 = new ArrayList<>();
Collections.addAll(cities3, "石家庄市", "唐山市", "邢台市", "保定市", "张家口市");
// 3.把省份 以及 对应的 城市存放到Map
map.put("江苏省", cities1);
map.put("湖北省", cities2);
map.put("河北省", cities3);
System.out.println(map);
// 4.遍历里面所有的省份 及其 对应的城市
map.forEach((k, v) -> {
// k : 江苏省 、湖北省、 河北省南
// v : 上面的 cities1 , cities2 , cities3
System.out.println("省份是:" + k);
// List
v.forEach((val) -> {
System.out.print(val + "\t");
});
System.out.println();
});
}
}