HDFS与Hive实战 + 滴滴出行数据分析
HDFS与Hive实战 + 滴滴出行数据分析
-
- 1.HDFS
-
- 1.1 分布式文件系统
- 1.2 HDFS的Shell命令行
- 1.3 启动Hadoop集群
- 1.4 大数据环境清单
- 2.数据仓库
-
- 2.1 数据仓库与数据库区别
- 3.Hive
-
- 3.1 终端连接Hive
- 3.2 Hive操作命令
- 3.3 Hive函数
- 4. Zeppelin
- 5.滴滴出行数据分析
-
- 5.1 架构图
- 5.2 日志数据集介绍
- 5.3 构建数据仓库
- 5.4 ods创建用户打车订单表
- 5.5 创建分区
- 5.6 上传到对应分区
- 5.7 数据预处理
- 5.8 订单分析
-
- 5.8.1 app层建表
- 5.8.2 加载数据到app表
- 5.8.3 不同地域订单占比分析(省份)
环境配置:链接:https://pan.baidu.com/s/1z8ALyBJ6aWuHE4bR2mvvoA 密码:zylc
1.HDFS
1.1 分布式文件系统
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目. Hadoop 非常适于存储大型数据 (比如 TB 和 PB), 其就是使用 HDFS 作为存储系统. HDFS 使用多台计算机 存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统.
1.2 HDFS的Shell命令行
- 查看文件链表 hadoop fs -ls URL
- 创建文件夹 hadoop fs -p -mkdir /aa/bb
- 上传文件 hadoop fs -put 本地文件 hdfs目的地
- 下载文件 hadoop fs -get 文件 hdfs来源地
- 删除文件 hadoop fs -rm 文件
1.3 启动Hadoop集群
- cd /export/onekey
- ./start-all.sh
1.4 大数据环境清单
| 组件 | 说明 |
|---|---|
| Apache Hadoop | 三大组件: HDFS:分布式文件系统 MapReduce:分布式计算引擎 YARN:资源管理系统 |
| Apache Hive | 数据仓库平台 |
| Apache Spark | 主流的第三代计算引擎 |
| Apache Zeppelin | 大数据可视化操作平台 |
2.数据仓库
是一个很大的数据存储集合,出于企业的分析性报告和决策支持目的而创建,对多样的业务数据进行筛选与整 合。它为企业提供一定的BI(商业智能)能力,指导业务流程改进、监视时间、成本、质量以及控制。数据仓库的输入方是各种各样的数据源,最终的输出用于企业的数据分析、数据挖掘、数据报表等方向。有很多版本的迭代主要用用来查找。
2.1 数据仓库与数据库区别
数据库:面向交易的处理系统,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行 查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题,也被称为联机事务处理 OLTP (On-Line Transaction Processing)。
数据仓库:一般针对某些主题的历史数据进行分析,支持管理决策,又被称为联机分析处理 OLAP (On-Line Analytical Processing)
两者区别:
- 数据库是面向事务的设计,数据仓库是面向主题设计的。
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据。
- 数据库设计是尽量避免冗余,一般针对某一业务应用进行设计,比如一张简单的User表,记录 用户名、密码等简单数据即可,符合业务应用,但是不符合分析。数据仓库在设计是有意引入 冗余,依照分析需求,分析维度、分析指标进行设计。
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
3.Hive
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供 类SQL查询功能。
3.1 终端连接Hive
- 进入到/export/server/spark-2.3.0-bin-hadoop2.7/bin目录中
- 执行以下命令:./beeline
- 输入:!connect jdbc:hive2://node1.itcast.cn:10000,回车
- 输入用户名:root
- 直接回车,即可使用命令行连接到Hive,然后就可以执行HQL了
3.2 Hive操作命令
-
创建数据库
- create database if not exists myhive;
-
查看数据库
- show databases;
-
删除数据库包含数据库下的表一起删除
- drop database myhive cascade;
-
创建表并指定字段之间的分隔符
- create table if not exists myhive.stu2**(id integer ,name string) row format delimited fields terminated by ‘,’ stored as textfile location ‘/user/stu2’;**
-
创建分区表
- create table myhive.score(s_id string, c_id string , s_score int) partitioned by (month string) row format delimited fields terminated by ‘,’
-
加载数据到分区表中
- load data local inpath ‘/root/data/hive-test/score.csv’ into table myhive.score partition (month=‘202006’);
-
添加分区
- alter table myhive.score add partition(month = ‘202007’)
-
创建内部表 默认在hfds的路径
- /user/ hive/warehouse/数据库名/分区名/表名
-
上传的方式向分区中插入数据
- hadoop fs -put 文件.txt /user/ hive/warehouse/数据库名/分区名/表名
3.3 Hive函数
- length() 长度
- data_format() 日期处理 data_format(‘2012-02-12 12:00:01’,‘yyyy-MM-dd HH:mm’)
- 条件函数
- CASE WHEN a THEN b [WHEN c THEN d] * [ELSE e] END
- case when s_id = 1 then ‘张三’ else s_id end
4. Zeppelin
使用Zeppelin来连接到Spark SQL的Thrift Server,这样我们可以以更直观的方式来查看 Hive中的数据。而且Zeppelin也可以以图表的方式展示数据,端口8090
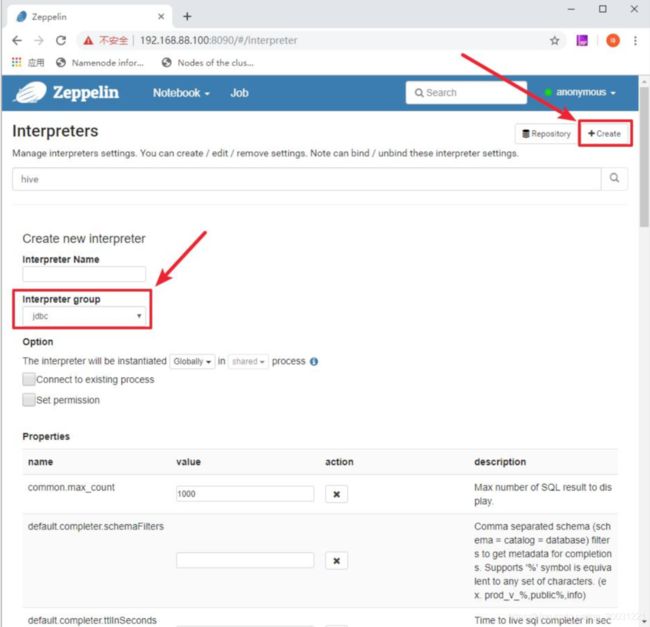

| default.driver | org.apache.hive.jdbc.HiveDriver |
|---|---|
| default.url | jdbc:hive2://node1.itcast.cn:10000 |
| Dependencies artifact | /export/server/hadoop-2.7.5/share/hadoop/common/hadoop-common-2. 7.5.jar /export/server/hive-2.1.0/lib/hive-common-2.1.0.jar /export/server/hive-2.1.0/jdbc/hive-jdbc-2.1.0-standalone.jar /export/server/hive-2.1.0/lib/hive-serde-2.1.0.jar /export/server/hive-2.1.0/lib/hive-service-2.1.0.jar /export/server/hive-2.1.0/lib/curator-client-2.6.0.jar |
5.滴滴出行数据分析
5.1 架构图
-
用户打车的订单数据非常庞大。所以我们需要选择一个大规模数据的分布式文件系统来存储这些 日志文件,此处,我们基于Hadoop的HDFS文件系统来存储数据。
-
为了方便进行数据分析,我们要将这些日志文件的数据映射为一张一张的表,所以,我们基于 Hive来构建数据仓库。所有的数据,都会在Hive下来几种进行管理。为了提高数据处理的性能。
-
我们将基于Spark引擎来进行数据开发,所有的应用程序都将运行在Spark集群上,这样可以保 证数据被高性能地处理。
5.2 日志数据集介绍
以下就是一部门用户打车的日志文件。
b05b0034cba34ad4a707b4e67f681c71,15152042581,109.348825,36.068516, 陕 西 省 , 延 安 市,78.2,男,软件工程,70后,4,1,2020-4-12 20:54,0,2020-4-12 20:06
23b60a8ff11342fcadab3a397356ba33,15152049352,110.231895,36.426178, 陕 西 省 , 延 安 市,19.5,女,金融,80后,3,0,0,2020-4-12 4:04
1db33366c0e84f248ade1efba0bb9227,13905224124,115.23596,38.652724, 河 北 省 , 保 定 市,13.7,男,金融,90后,7,1,2020-4-12 10:10,0,2020-4-12 0:29
日志包含了以下字段:
| 字段名 | 解释 |
|---|---|
| orderld | 订单id |
| telephone | 打车用户手机 |
| long | 用户发起打车的经度 |
| lat | 用户发起打车的纬度 |
| province | 所在省份 |
| city | 所在城市 |
| es_money | 预估打车费用 |
| gender | 用户信息 - 性别 |
| profession | 用户信息 - 行业 |
| age_range | 年龄段(70后、80后、…) |
| tip | 小费 |
| subscribe | 是否预约(0 - 非预约、1 - 预约) |
| sub_time | 预约时间 |
| is_agent | 是否代叫(0 - 本人、1 - 代叫) |
| agent_telephone | 预约人手机 |
| order_time | 订单时间 |
5.3 构建数据仓库
为了方便组织、管理上述的三类数据,我们将数仓分成不同的层,简单来说,就是分别将三类不同 的数据保存在Hive的不同数据库中。
| 数据类别 | 数据库名 | 分层名 |
|---|---|---|
| 原始日志数据(业务系统中保 存的日志文件数据) | ods_didi | 临时存储层 |
| 预处理后的数据 | dw_didi | 数据仓库层 |
| 分析结果数据 | app_didi | 应用层 |
-- 1.1 创建ods库
create database if not exists ods_didi;
-- 1.2 创建dw库
create database if not exists dw_didi;
-- 1.3 创建app库
create database if not exists app_didi;
5.4 ods创建用户打车订单表
-- 2.1 创建订单表结构
create table if not exists ods_didi.t_user_order(
orderId string comment '订单id',
telephone string comment '打车用户手机',
lng string comment '用户发起打车的经度',
lat string comment '用户发起打车的纬度',
province string comment '所在省份',
city string comment '所在城市',
es_money double comment '预估打车费用',
gender string comment '用户信息 - 性别',
profession string comment '用户信息 - 行业',
age_range string comment '年龄段(70后、80后、...)',
tip double comment '小费',
subscribe integer comment '是否预约(0 - 非预约、1 - 预约)',
sub_time string comment '预约时间',
is_agent integer comment '是否代叫(0 - 本人、1 - 代叫)',
agent_telephone string comment '预约人手机',
order_time string comment '预约时间'
)
partitioned by (dt string comment '时间分区')
ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' ;
5.5 创建分区
alter table ods_didi.t_user_order add if not exists partition(dt='2020-04-12');
5.6 上传到对应分区
-- 上传订单数据
hadoop fs -put /root/data/didi/order.csv /user/hive/warehouse/ods_didi.db/t_user _order/dt=2020-04-12
-- 查看文件
hadoop fs -ls /user/hive/warehouse/ods_didi.db/t_user_order/dt=2020-04-12
-- 查看是否映射成功
select * from ods_didi.t_user_order limit 10
5.7 数据预处理
目的主要是让预处理后的数据更容易进行数据分析,并且能够将一些非法 的数据处理掉,避免影响实际的统计结果
dw层创建宽表:
create table if not exists dw_didi.t_user_order_wide(
orderId string comment '订单id',
telephone string comment '打车用户手机',
lng string comment '用户发起打车的经度',
lat string comment '用户发起打车的纬度',
province string comment '所在省份',
city string comment '所在城市',
es_money double comment '预估打车费用',
gender string comment '用户信息',
profession string comment '用户信息',
age_range string comment '年龄段(70后、80后、',
tip double comment '小费',
subscribe integer comment '是否预约(0 - 非预约、1 - 预约)',
subscribe_name string comment '是否预约名称',
sub_time string comment '预约时间',
is_agent integer comment '是否代叫(0 - 本人、1 - 代叫)',
is_agent_name string comment '是否代叫名称',
agent_telephone string comment '预约人手机',
order_date string comment '预约日期,yyyy-MM-dd',
order_year integer comment '年',
order_month integer comment '月',
order_day integer comment '日',
order_hour integer comment '小时',
order_time_range string comment '时间段',
order_time string comment '预约时间'
)
partitioned by (dt string comment '按照年月日来分区')
row format delimited fields terminated by ',';
预处理需求
-
过滤掉order_time长度小于8的数据,如果小于8,表示这条数据不合法,不应该参加统计。
-
将一些0、1表示的字段,处理为更容易理解的字段。例如:subscribe字段,0表示非预约、1表 示预约。我们需要添加一个额外的字段,用来展示非预约和预约,这样将来我们分析的时候,跟容 易看懂数据。
-
order_time字段为2020-4-12 1:15,为了将来更方便处理,我们统一使用类似 2020-04-12 01:15 来表示,这样所有的order_time字段长度是一样的。并且将日期获取出来
-
为了方便将来按照年、月、日、小时统计,我们需要新增这几个字段。
-
后续要分析一天内,不同时段的订单量,我们需要在预处理过程中将订单对应的时间段提前计 算出来
数据加载到dw层宽表
HQL编写好后,为了方便后续分析,我们需要将预处理好的数据写入到之前创建的宽表中。注意: 宽表也是一个分区表,所以,写入的时候一定要指定对应的分区。
insert overwrite table dw_didi.t_user_order_wide partition(dt = '2020-04-12')
select
orderId,
telephone,
long,
lat,
province,
city,
es_money,
gender,
profession,
age_range,
tip,
subscribe,
case when subscribe = 0 then '非预约'
when subscribe = 1 then '预约'
end as subscribe_name,
sub_time,
is_agent,
case when is_agent = 0 then '本人'
when is_agent = 1 then '代叫'
end as is_agent_name,
agent_telephone,
date_format(order_time, 'yyyy-MM-dd') as order_date,
year(order_time) as year,
month(order_time) as month,
day(order_time) as day,
hour(order_time) as hour,
case when hour(order_time) >= 1 and hour(order_time) < 5 then '凌晨'
when hour(order_time) >= 5 and hour(order_time) < 8 then '早上'
when hour(order_time) >= 8 and hour(order_time) < 11 then '上午'
when hour(order_time) >= 11 and hour(order_time) < 13 then '中午'
when hour(order_time) >= 13 and hour(order_time) < 17 then '下午'
when hour(order_time) >= 17 and hour(order_time) < 19 then '晚上'
when hour(order_time) >= 19 and hour(order_time) < 20 then '半夜'
when hour(order_time) >= 20 and hour(order_time) < 24 then '深夜'
when hour(order_time) >= 0 and hour(order_time) < 1 then '凌晨'
end as order_time_range,
date_format(order_time, 'yyyy-MM-dd HH:mm') as order_time
from
ods_didi.t_user_order
where
dt = '2020-04-12' and
length(order_time) >= 8;
5.8 订单分析
5.8.1 app层建表
数据分析好了,但要知道,我们处理大规模数据,每次处理都需要占用较长时间,所以,我们可以 将计算好的数据,直接保存下来。将来,我们就可以快速查询数据结果了。所以,我们可以提前在 app层创建好表。
-- 创建保存日期对应订单笔数的app表
create table if not exists app_didi.t_order_total(
date string comment '日期(年月日)',
count integer comment '订单笔数'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ',';
5.8.2 加载数据到app表
insert overwrite table app_didi.t_order_total partition(month='2020-04')
select
'2020-04-12',
count(orderid) as total_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12';
5.8.3 不同地域订单占比分析(省份)
create table if not exists app_didi.t_order_province_total(
date string comment '日期',
province string comment '省份',
count integer comment '订单数量'
)
partitioned by (month string comment '年月,yyyy-MM')
row format delimited fields terminated by ',';
insert overwrite table app_didi.t_order_province_total partition(month = '2020-04')
select
'2020-04-12',
province,
count(*) as order_cnt
from
dw_didi.t_user_order_wide
where
dt = '2020-04-12'
group by province;