记一次Oracle DBLink连接使用情况的排查
背景
项目中应用程序有连接池配置到我们自己的Oracle RAC(以下简称本地库)和友商的Oracle RAC(简称友商库),均为11G。另外由于历史原因有一些需求需要本地库与友商库联合查询,为了实现联合查询,本地库有创建dblink到友商库。熟悉的朋友应该都知道dblink之前是存在SCN暴增Bug的,所以在后期的开发中我们一直尽量替换掉原有使用dblink写法的代码,久而久之时至今日,已经不清楚到底哪些程序使用了DBlink。今天友商工程师反馈友商库中我们的sessions太多了,让排查一下。
登录友商库排查
针对友商库,我这里有查询用户,尝试查询下gv$session发现也有查询权限,排查开始!
先统计下友商数据库的连接数情况,发现节点1sessions 2300,节点2sessions 1100,节点1连接数确实比较高,而且分布不均匀。
select inst_id,count(1)
from gv$session
group by inst_id;再统计下连接数分布情况,发现sessions确实大多数来源于我的服务器。
select machine,count(1) nums
from gv$session
group by machine
order by nums desc;但诡异的是,其中一多半sessions的machine都是本地库Oracle Rac两台主机,由于数据库不会主动访问友商库,这里判断这些sessions就是本地库到友商库的dblink连接,但具体dblink有哪些应用程序使用还不清楚。
考虑先查询一下session执行的sql:
select b.sql_text,b.sql_fulltext
from gv$session a, gv$sqlarea b
where a.sql_id = b.sql_id
and (a.machine = 'myoracledb1' or a.machine = 'myoracledb2');然后拿sql去代码里搜索下看是否可以查到,由于我这里只有部分源码,搜索后无果。
摘录sql发给各组开发排查,无果。
求人不如靠自己啊,自己想办法查查来源吧!
关联本地库排查
在gv$session中,process列对应着客户端操作系统的进程号。
这样我就可以使用以下sql在友商库里查询到客户端操作系统进程号(即本地库服务器执行dblink连接的操作系统进程号)
select process
from gv$session
where machine = 'myoracledb1' or machine = 'myoracledb2');将查询出的所有进程号复制出来,在本地库新建一个临时表feng将结果导入。
接下来在本地库进行查询,
因为oracle中的所有进程都会记录在v$process中,v$process中的SPID即oracle服务器操作系统进程号,v$process中的ADDR与v$session中的PADDR为对应关系,尝试写sql进行关联查询
select machine,count(1) nums from (SELECT SESS.INST_ID,
SESS.USERNAME,
SESS.STATUS,
SESS.SCHEMANAME,
SESS.OSUSER,
SESS.MACHINE,
SESS.PORT,
SESS.SQL_ID,
SESS.PREV_SQL_ID,
SESS.PREV_EXEC_START
FROM GV$SESSION SESS,
(SELECT DISTINCT(ADDR) FROM FENG A, GV$PROCESS B WHERE A.PROCESS = B.SPID) ADDRTAB
WHERE SESS.PADDR = ADDRTAB.ADDR ) zz group by zz.machine order by nums desc 即通过在友商库查询到本地库使用dblink的进程号,然后用这些进程号在本地库的v$process中与SPID匹配,获取到ADDR,再用这些ADDR去v$session与PADDR匹配结果,最中可以获取到这些session的信息。
结果出来,查看machine列,发现这些session绝大多数的客户端主机都来源于应用集群XX,可以定位到dblink用法的代码是在这里了(由于process与session为1对多的关系,所以查询结果可能会有一些偏差,但查询结果里的machine95%以上的记录都指向某一集群,一定不完全是巧合)。
验证
既然要把问题抛给开发,那还是确定一下比较好。
尝试轮起上面定位的应用集群,发现每重启一个节点,友商库中的session就会降低一些,同时猜测dblink连接只有当使用时才会创建,应用启动时即连接池初始化时并不会创建大量dblink连接。全部重启后发现结果与猜测一致。目前可以确定为dblink的使用者为此应用集群XX,将分析结果转给开发进行接下来的代码排查与修改。
连接数高的问题处理
1. DBLink 不均衡
处理问题前查看到所有dblink均连接到友商库的1节点,若将连接均衡到两个节点,则会降低1节点的连接数。
查看本地库dblink创建语句,发现没有添加loadbalance参数,遂重建dblink增加loadbalance参数,但经过观察问题未解决,dblink仍连接到友商库1节点,后续进行问题分析处理。
2. 调整连接池配置
分析得知此应用集群业务量不高,原本连接池设置为初始化与最大空闲连接均为50,经过测试后,将连接池初始化与最大空闲连接数均调整为10。
3. 人为KILLED导致
处理问题前经分析友商库中gv$session,发现有近一半dblink过去的连接状态都为KILLED,说明被手动杀过,经与友商工程师确认确实有人为杀过连接(杀连接的原因不得而知),但连接被杀掉后会重新发起新的连接,且被KILLED的连接并未真正释放,所以连接数也会增多一倍,经轮起应用集群后所有KILLED连接均已释放。
4. 依公司与客户规范,后期进行程序调整,不再使用DBLink
遗留问题
1. 为什么状态被标记为KILLED的session迟迟未释放?
2. DBLink Oracle Rac时如何均衡连接到两个节点?
我不是DBA,对Oracle了解也并不多,敬请指教,若有错误也请评论告知,多谢!
2022年5月12日补充
虽然上面我们已经定位到某一应用程序,但开发经过几日的排查,仍无结果。
毕竟跨库联合查询时,SQL语句先经过本地库oracle解析转换,然后把与友商库有关的脚本发送到友商库进行查询,这样我们最初在友商库获取到的sql语句是转换后的,并不是代码中写的sql。如下图1所示:
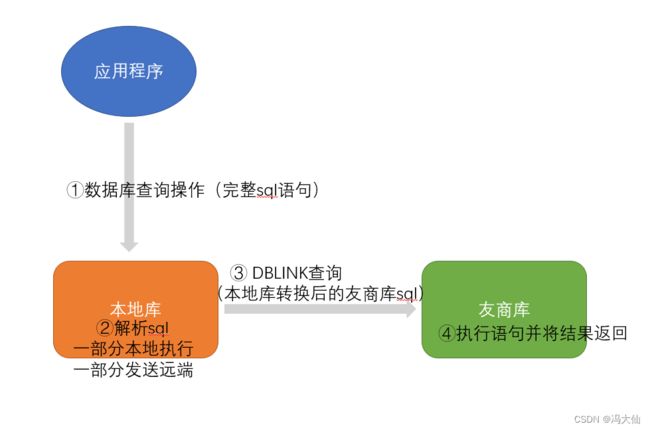
所以接下来需要想办法获取完整SQL语句。
查找数据库进程进行分析
由于数据库中进程很多,我们要在本地库中筛选出符合我们分析问题的进程(即包含上述①③的某个数据库进程),进行针对性的分析。
步骤1. 在友商库查找来源于本地库的dblink session(即上图③),在查询结果中任意挑选一行,记录inst_id、process、machine、port的值。
select inst_id,process,machine,port from gv$session where machine = '本地库主机名';步骤2. 在本地库执行以下sql,将步骤1中记录的值带入到以下sql,获取此process中从应用程序到本地库的session(即上图①)
select a.inst_id, a.process, a.machine, a.port, a.sql_id, a.prev_sql_id
from gv$session a, gv$process b
where a.paddr = b.ADDR
and b.spid = 'process值'
and a.inst_id = 'inst_id值';

这里可以查到客户端应用程序所在的主机,端口,以及执行过的sql_id。
由于这一session执行过多条语句,查看此sql_id并非为我们的目标sql。
步骤3. 监听tcp连接,抓包进行分析
通过上面的查询,我们已经分别获取到了图1中①③部分TCP连接的源主机、源端口,目标主机,目标端口,所以我们可以在这两处同时进行抓包,获取数据流。
在应用服务器执行命令抓取上图①段数据包:
tcpdump -i 当前主机网卡名 src port 步骤2查询结果中的PORT值 and dst host 本地库IP地址 -w /tmp/app.cap在本地库服务器执行命令抓取③段数据包:
tcpdump -i 当前主机网卡名 src port 步骤1查询结果中的PORT值 and dst host 友商库IP地址 -w /tmp/oracle.cap步骤4. 持续抓包一段时间,监控到oracle.cap大小不再为0时就可以全部停止抓包了,然后使用wireshark进行分析(下图关键内容模糊处理)。

通过左侧数据包内容与时间,再查找定位到右侧目标数据包,查看到数据包内容如下图:

到这里,已获取到从应用程序到本地库的原始sql,抛给开发,这次一下就查到了具体代码。
参考
v$session字段解释: https://blog.csdn.net/herry1689/article/details/102454871