MySQL 基于成本的优化
其实在MySQL中⼀条查询语句的执⾏成本是由下边这两个⽅⾯组成的:
I/O成本
我们的表经常使⽤的MyISAM、InnoDB存储引擎都是将数据和索引都存储到磁盘上的,当我们想查询表中的记录时,需要先把数据或者索引加载到内存中 然后再操作。这个从磁盘到内存这个加载的过程损耗的时间称之为I/O成本。
CPU成本
读取以及检测记录是否满⾜对应的搜索条件、对结果集进⾏排序等这些操作损耗的时间称之为CPU成本。 对于InnoDB存储引擎来说,⻚是磁盘和内存之间交互的基本单位,设计MySQL的⼤叔规定读取⼀个⻚⾯花费的成本默认是1.0,读取以及检测⼀条记录是否符 合搜索条件的成本默认是0.2。1.0、0.2这些数字称之为成本常数,这两个成本常数我们最常⽤到,其余的成本常数我们后边再说哈。
基于成本的优化步骤 在⼀条单表查询语句真正执⾏之前,MySQL的查询优化器会找出执⾏该语句所有可能使⽤的⽅案,对⽐之后找出成本最低的⽅案,这个成本最低的⽅案就是所 谓的执⾏计划,之后才会调⽤存储引擎提供的接⼝真正的执⾏查询,这个过程总结⼀下就是这样:
1. 根据搜索条件,找出所有可能使⽤的索引
2. 计算全表扫描的代价
3. 计算使⽤不同索引执⾏查询的代价
4. 对⽐各种执⾏⽅案的代价,找出成本最低的那⼀个
下边我们就以⼀个实例来分析⼀下这些步骤,单表查询语句如下:
1. 根据搜索条件,找出所有可能使⽤的索引
我们前边说过,对于B+树索引来说,只要索引列和常数使⽤=、、IN、NOT IN、IS NULL、IS NOT NULL、>、=、)或者LIKE操作符连接起来,就可以产⽣⼀个所谓的范围区间(LIKE匹配字符串前缀也⾏),也就是说这些搜索条件都可能使⽤到索引,设计MySQL的⼤ 叔把⼀个查询中可能使⽤到的索引称之为possible keys。
我们分析⼀下上边查询中涉及到的⼏个搜索条件:
key1 IN ('a', 'b', 'c'),这个搜索条件可以使⽤⼆级索引idx_key1。
key2 > 10 AND key2 < 1000,这个搜索条件可以使⽤⼆级索引idx_key2。
key3 > key2,这个搜索条件的索引列由于没有和常数⽐较,所以并不能使⽤到索引。
key_part1 LIKE '%hello%',key_part1通过LIKE操作符和以通配符开头的字符串做⽐较,不可以适⽤索引。
common_field = '123',由于该列上压根⼉没有索引,所以不会⽤到索引。
综上所述,上边的查询语句可能⽤到的索引,也就是possible keys只有idx_key1和idx_key2。
2. 计算全表扫描的代价
对于InnoDB存储引擎来说,全表扫描的意思就是把聚簇索引中的记录都依次和给定的搜索条件做⼀下⽐较,把符合搜索条件的记录加⼊到结果集,所以需要 将聚簇索引对应的⻚⾯加载到内存中,然后再检测记录是否符合搜索条件。由于查询成本=I/O成本+CPU成本,所以计算全表扫描的代价需要两个信息:
聚簇索引占⽤的⻚⾯数
该表中的记录数 这两个信息从哪来呢?设计MySQL的⼤叔为每个表维护了⼀系列的统计信息,关于这些统计信息是如何收集起来的我们放在本章后边详细唠叨,现在看看怎么 查看这些统计信息哈。设计MySQL的⼤叔给我们提供了SHOW TABLE STATUS语句来查看表的统计信息,如果要看指定的某个表的统计信息,在该语句后加对应 的LIKE语句就好了,⽐⽅说我们要查看single_table这个表的统计信息可以这么写:
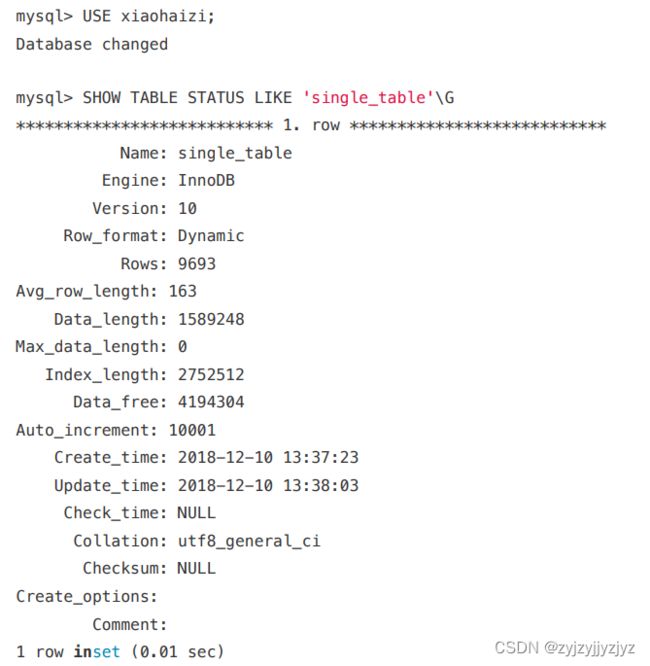
虽然出现了很多统计选项,但我们⽬前只关⼼两个:
Rows
本选项表示表中的记录条数。对于使⽤MyISAM存储引擎的表来说,该值是准确的,对于使⽤InnoDB存储引擎的表来说,该值是⼀个估计值。从查询结果 我们也可以看出来,由于我们的single_table表是使⽤InnoDB存储引擎的,所以虽然实际上表中有10000条记录,但是SHOW TABLE STATUS显示的Rows 值只有9693条记录。
Data_length
本选项表示表占⽤的存储空间字节数。使⽤MyISAM存储引擎的表来说,该值就是数据⽂件的⼤⼩,对于使⽤InnoDB存储引擎的表来说,该值就相当于聚 簇索引占⽤的存储空间⼤⼩,也就是说可以这样计算该值的⼤⼩:
Data_length = 聚簇索引的⻚⾯数量 x 每个⻚⾯的⼤⼩
我们的single_table使⽤默认16KB的⻚⾯⼤⼩,⽽上边查询结果显示Data_length的值是1589248,所以我们可以反向来推导出聚簇索引的⻚⾯数量:
聚簇索引的⻚⾯数量 = 1589248 ÷ 16 ÷ 1024 = 97
我们现在已经得到了聚簇索引占⽤的⻚⾯数量以及该表记录数的估计值,所以就可以计算全表扫描成本了,但是设计MySQL的⼤叔在真实计算成本时会进⾏⼀ 些微调,这些微调的值是直接硬编码到代码⾥的,由于没有注释,我也不知道这些微调值是个啥⼦意思,但是由于这些微调的值⼗分的⼩,并不影响我们分 析,所以我们也没有必要在这些微调值上纠结了。现在可以看⼀下全表扫描成本的计算过程:
I/O成本
97 x 1.0 + 1.1 = 98.1
97指的是聚簇索引占⽤的⻚⾯数,1.0指的是加载⼀个⻚⾯的成本常数,后边的1.1是⼀个微调值,我们不⽤在意。
CPU成本:
9693 x 0.2 + 1.0 = 1939.6
9693指的是统计数据中表的记录数,对于InnoDB存储引擎来说是⼀个估计值,0.2指的是访问⼀条记录所需的成本常数,后边的1.0是⼀个微调值,我们 不⽤在意。
总成本:
98.1 + 1939.6 = 2037.7 综上所述,对于single_table的全表扫描所需的总成本就是2037.7。