MySQL优化之查询成本
什么是查询成本:
MySQL执行一个查询它会选择其中成本最低,或者说代价最低的那种方案,MySQL中一条查询语句的执行成本是由以下两个方面组成:
I/O 成本
MySQL中的数据和索引都存储到磁盘上,当查询表中的记录时,需要先把数据或者索引加载到内存中然后再操作,这个从磁盘到内存这个加载的过程损耗的时间称为I/O成本
CPU成本
读取以及检测记录是否满足对应的搜索条件,对结果集进行排序等这些操作损耗的时间称之为CPU成本
什么是成本常数:
MySQL 规定读取一个页面花费的成本是多少,读取以及检测一条记录是否符合搜索条件的成本默认是 是多少。这些数字称之为成本常数,这两个成本常数我们最常用到,当然还有其他的成本常数。
除了以上两个成本常数,MySQL还支持很多,它们被存储到了MySQL数据库中的两个表中:

因为一条SQL语句的执行是分为两层的:Server层和存储引擎层。
在Server层进行连接管理、查询缓存(8.0以后去掉了)、语法解析、查询优化等操作,在存储引擎层执行具体的数据存取操作。也就是说一条SQL语句在Server层中执行的成本和它所操作表使用的存储引擎是没有关系的,所以关于这些操作对应的成本常数就存储到了server_cost表中,而依赖存储引擎的一些操作对应的成本常数就存储到了engine_cost表中。
不同的mysql版本中默认的成本常数值是不同的
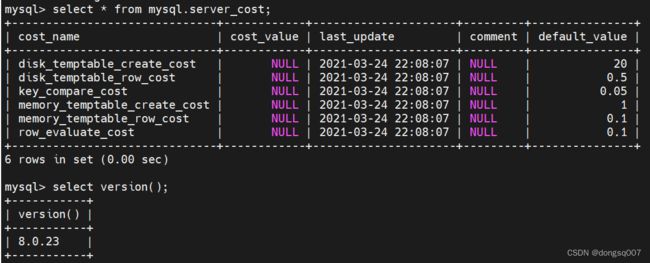
server_cost表:
server_cost表在server层进行的一些操作对应的成本常数,具体内容如下,先看MySQL:5.7版本:

server_cost表中各列的意思:
cost_name: 表示成本常数的名称。
cost_value: 表示成本常数对应的值,如果该列的值为NULL的话,会采用默认的值。
last_update: 表示最后更新记录的时间。
comment: 注释。
再看cost_name列中各参数值的意义:
disk_temptable_create_cost:默认值是40.0 表示创建基于磁盘的临时表的成本,如果增大这个值会让优化器尽量少的创建基于磁盘的临时表。
disk_temptable_row_cost: 默认值1.0 向基于磁盘的临时表写入或读取一条记录的成本,如果增大这个值,会让优化器尽量少的创建基于磁盘的临时表。
key_compare_cost:默认值0.1 两条记录做比较操作的成本,多用在排序操作上,如果增大这个值的话会提升 filesort 的成本,让优化器可能更倾向于使用索引完成排序而不是 filesort。
memory_temptable_create_cost:默认值 2.0 创建基于内存的临时表的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。
memory_temptable_row_cost:默认值0.2 向基于内存的临时表写入或读取一条记录的成本,如果增大这个值的话会让优化器尽量少的创建基于内存的临时表。
row_evaluate_cost:默认值 0.2 这个就是使用检测一条记录是否符合搜索条件的成本,增大这个值可能让优化器更倾向于使用索引而不是直接全表扫描。
这些成本常数在server_cost中的初始值都是NULL,优化器会使用其默认值来计算某个操作的成本计算,如果想修改某个成本常数值的话,对成本常数做update更新操作,然后 :
FLUSH OPTIMIZER_COSTS;
再看MySQL:8.0的默认值,和MySQL:5.7的默认值还是有很大不同。
engine_cost表:
engine_cost表再存储引擎层面进行一些操作对应的成本常数,先看MySQL:5.7版本:
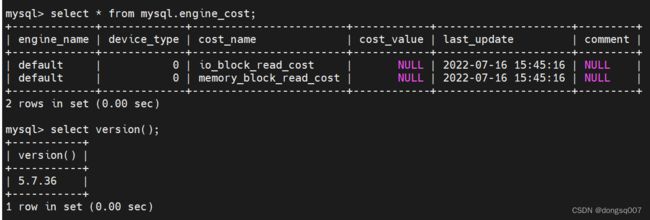
engine_name:成本常数适用的存储引擎名称。如果值为 default,表示对应的成本常数适用于所有的存储引擎。
device_type:指存储引擎使用的设备类型,这主要是为了区分常规的机械硬盘和固态硬盘,不过在 MySQL 5.7 这个版本中并没有对机械硬盘的成本和固态硬盘的成本作区分,所以该值默认是 0。
从 engine_cost 表中的内容可以看出来,目前支持的存储引擎成本常数只有两个:
io_block_read_cost: 默认值 1.0 从磁盘上读取一个块对应的成本。对于 InnoDB 存储引擎来说,一个页就是一个块,不过对于 MyISAM 存储引擎来说,默认是以 4096 字节作为一个块的。增大这个值会加重 I/O 成本,可能让优化器更倾向于选择使用索引执行查询而不是执行全表扫描。
memory_block_read_cost: 默认值 1.0 与上一个参数类似,只不过衡量的是从内存中读取一个块对应的成本。
再看MySQL:8.0的默认值,memory_block_read_cost 默认值与MySQL:5.7相比有变化。

计算全表扫描的代价:
对于 InnoDB 存储引擎来说,全表扫描的意思就是把聚簇索引中的记录都依次和给定的搜索条件做一下比较,把符合搜索条件的记录加入到结果集,所以需要将聚簇索引对应的页面加载到内存中,然后再检测记录是否符合搜索条件。由于
查询成本=I/O 成本+CPU 成本
而
I/O成本=页面数量 x engine_cost表中io_block_read_cost的值
CPU成本=记录数 x server_cost表中row_evaluate_cost的值
所以计算全表扫描的代价需要两个信息:聚簇索引占用的页面数,该表中的记录数。页面数用于计算I/O成本,记录数用于计算CPU成本。
通过SHOW TABLE STATUS 语句来查看表的统计信息,如果要看指定的某个表的统计信息,在该语句后加对应的 LIKE 语句就好了,比方说我们要查看 t1 这个表的统计信息可以这么写:
SHOW TABLE STATUS LIKE 't1'
通过Rows和Data_length两个参数的值,我们就可以计算出全表扫描的代价:
Rows:表示表中的记录条数。对于使用 MyISAM 存储引擎的表来说,该值是准确的,对于使用 InnoDB 存储引擎的表来说,该值是一个估计值。
Data_length:表示表占用的存储空间字节数。使用 MyISAM 存储引擎的表来说,该值就是数据文件的大小,对于使用 InnoDB 存储引擎的表来说,该值就相当于聚簇索引占用的存储空间大小,也就是说可以这样计算该值的大小:
Data_length = 聚簇索引的页面数量 x 每个页面的大小
t1表默认 16KB 的页面大小,而上边查询结果显示
Data_length 的值是 33095680,所以我们可以反向来推导出聚簇索引的页面数量:聚簇索引的页面数量 = 33095680÷ 16 ÷ 1024 = 2020
所以I/O成本的计算是:2020 x 1.0 (MySQL:8.0中engine_cost中的io_block_read_cost中的值) = 2020
所以CPU成本的计算是:656568 x 0.1 (MySQL:8.0中server_cost中row_evaluate_cost中的值) = 65656.8
所以 t1 表全表扫描的代价是 2020 + 65656.8 = 67676.8
现在修改 engine_cost表中io_block_read_cost的参数为1.1

按照我们的计算方式:I/O成本=2020 x 1.1=2222,CPU成本不变,总成本=67878.80
执行explain format=json select * from t1 通过执行这个语句,会得到一个json格式的执行计划:
{
"query_block": {
"select_id": 1,
"cost_info": {
"query_cost": "67878.80" //整个查询的成本为
},
"table": {
"table_name": "t1",
"access_type": "ALL",
"rows_examined_per_scan": 656568, //查询一次大致扫描的行数
"rows_produced_per_join": 656568, //扇出数量
"filtered": "100.00", //过滤百分比,和查询一次大致扫描的行数相乘,就是扇出数量
"cost_info": {
"read_cost": "2222.00", //IO成本
"eval_cost": "65656.80", //CPU成本
"prefix_cost": "67878.80", //单独查询表的成本
"data_read_per_join": "35M"
},
"used_columns": [
"id",
"order_no",
"create_time",
"expire_time",
"order_status"
]
}
}
}还没完,有空再更新,哈哈