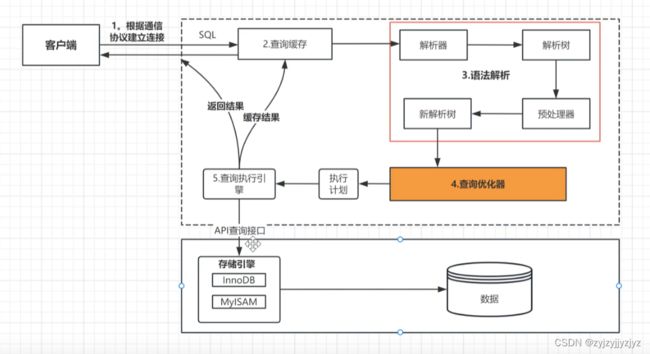
explain性能详细分析
首先看看sql的执行过程:
explain的返回列详解
1、id列:每个select都有一个对应的id号,并且是从1开始自增的。一共由四种情况。
(1)id号相同,从上往下执行。
CREATE table users(
id int PRIMARY KEY,
user_id int
)
CREATE table orders(
id int PRIMARY KEY,
order_id int
)
-- create index inx_users_user on users(user_id);
create index inx_orders_order on orders(order_id);
explain
select users.* from users inner join orders on users.id = orders.id;
id号相同,从上往下执行,先users再orders
(2)id号不同,号大的先执行
EXPLAIN
select id from users where id = (select id from orders where id = 2);
id号不同,号大的先执行,先orders再users
(3)两种情况都有————限制性序号大的,再同级从上往下执行。
set session OPTIMIZER_switch='derived_merge=off';#关闭5.7对衍生表合并优化
EXPLAIN
select * from (select users.id from users where user_id = 1) temp inner join orders on temp.id = orders.id;
set session OPTIMIZER_switch='derived_merge=on'; 
先 (2)后(1)。先user之后derived2,之后orders
uses产生衍生表,衍生表显示derived2(因为id为2的表产生的衍生表)
(4)有null
explain
select * from users
UNION
select * from orders; 显示null,最后执行null。表示结果集,并且不需要使用它进行查询。
显示null,最后执行null。表示结果集,并且不需要使用它进行查询。
2、select_type:表示查询语句执行的查询操作类型
(1)simple:简单select、连接查询。不包括union和子查询的select。
explain
select * from users;
explain
select users.* from users inner join orders on users.id = orders.id;
(2)primary:复杂查询中最外层查询,比如使用union或者union all时,id为1的记录select_type通常时primary
如union语句1——(4):
explain
select * from users
UNION
select * from orders;
先执行的orders被标记为union,users就是最外层的被标记为primary。
再如子查询1——(3):
set session OPTIMIZER_switch='derived_merge=off';
EXPLAIN
select * from (select users.id from users where user_id = 1) temp inner join orders on temp.id = orders.id;
set session OPTIMIZER_switch='derived_merge=on';
为什么有两个primary,先用users衍生表derived2。外层只是用了连接查询,所以外层的两个连接表都是primary。
(3)subquery:指在select语句中出现的子查询(不在from语句中),并且结果不依赖外部查询(不相关子查询)
EXPLAIN
select id from users where id = (select id from orders where id = 2);
为什么强调不在from语句中呢?
在from中的子句,可想而知是作为表的,所以大概率时衍生表类型。
不在from语句中的不相关子查询,类型就是subquery。
(4)dependent subquery:指在select语句中出现的查询语句(不在from语句中),相关子查询
EXPLAIN
select id from users where id = (select orders.id from orders where users.id = orders.id and id = 3);
不在from语句中的相关子查询,类型就是dependent subquery。
(5)derived:派生表,在from子句的查询语句,表示从为外部数据源中推导出来的,而不是从select语句中的其他列中选择出来的。
set session OPTIMIZER_switch='derived_merge=off';
EXPLAIN
select * from (select users.id from users where user_id = 1) temp inner join orders on temp.id = orders.id;
set session OPTIMIZER_switch='derived_merge=on';
(6) union:分为union和union all两种,若第二个select出现在union之后,则被标记为union,如果union被from子句的子查询包含,那么第一个select被标记为derived。union会去重,union all不会去重。
explain
select * from users
UNION
select * from orders;
3、type列:查询所使用的访问类型
需要知道的效率从高到低:
system const eq_ref ref range index all
一般来说保证range级别,最好能达到ref
(1)system:const类型的一种特使场景,查询的表只有一行记录的情况。并且该表使用的存储引擎的统计数据是精确的。
实验发现InnoDB创建表,并且直插入一条数据,但是type类型是all,这是为什么呢?
create table product(
id int PRIMARY KEY,
price VARCHAR(10)
)
insert into product values(1,'123');
explain
select * from product;![]() 原因: 就如上述概念所说的,表使用的存储引擎的统计数据是精确的才是system。InnoDB的统计数据不是精准的,虽然只有一条数据但是type是all。
原因: 就如上述概念所说的,表使用的存储引擎的统计数据是精确的才是system。InnoDB的统计数据不是精准的,虽然只有一条数据但是type是all。
Memory存储引擎(Hash索引)的统计数据是精确的,所以当只有一条数据的时候type是system。
在InnoDB中查找只有一行数据的系统表,type类型是system。
explain select * from mysql.proxies_priv;
![]()
有多行数据的系统表

(2)const:where条件是基于主键或者唯一索引查看一行,并且连接条件是常量(变量就是不确定的)
EXPLAIN
select * from product where id = 1;![]()
(3)eq_ref:基于主键或者唯一索引连接的两个表,对于每个索引键值,只有一条匹配记录,被驱动表的类型为eq_ref
explain
select * from users inner join orders on users.id = orders.id; 正如概念所说,被驱动表orders是eq_ref类型。
正如概念所说,被驱动表orders是eq_ref类型。
问题发现1:驱动表users,类型是all,看rows为8,因为需要users的id列的所有值所以全表扫描,但是如果建辅助索引,类型就变为index(这里index的原因是直接扫描了辅助索引不用回表就可以获取到全部的主键值,这很好理解)。但是这里我产生疑问,index和all的区别到底是什么?
我认为的index是全表扫描聚簇索引的时候只扫描主键值,不扫描数据value。全表扫描不光扫描主键值还扫描value。
但是 当删除辅助索引,驱动表变为all,这就证明在扫描聚簇索引的时候发生了全表扫描,为什么不只是扫描主键值这样也是index。看来我的理解有误,欢迎评论区对我进行指导。
问题发现2:概念所说的主键或者唯一索引连接的两个表,那连接条件是驱动表.主键=被驱动表.唯一索引列,是否还是eq_ref
答:否
explain
select * from users inner join orders on users.id = orders.order_id;
我们可以这么理解,因为唯一索引可以允许插入多个null,所以这样就违反了概念的只有一条匹配记录。
(4)ref:基于非唯一索引连接两个表或者通过二级索引与常量进行等值匹配,可能会存在多条记录。
①第一种情况:基于非唯一索引连接的两个表
explain
select * from users inner join orders on users.id = orders.order_id;上述order_id的唯一索引被删除了
 发现这和上面的问题发现2,都是相同的,被驱动表不管是唯一索引还是非唯一索引类型都是ref(确认过了),这是为什么?我学习的视频和文档都没有给出解释或者说没有发现这个问题,欢迎评论区解答。
发现这和上面的问题发现2,都是相同的,被驱动表不管是唯一索引还是非唯一索引类型都是ref(确认过了),这是为什么?我学习的视频和文档都没有给出解释或者说没有发现这个问题,欢迎评论区解答。
②第二种情况:通过二级索引(非唯一索引)列进行等值匹配
explain
select * from orders where order_id = 11; 实验发现order_id如果为非唯一索引的等值查询type就是ref,如果是唯一索引的等职查询就是const。
实验发现order_id如果为非唯一索引的等值查询type就是ref,如果是唯一索引的等职查询就是const。
(5)range:扫描部分索引,比如使用索引获取某些范围区间的记录。
explain
select * from orders where id > 3;
explain
select * from orders where order_id > 11;有些概念说的是非唯一索引进行扫描部分索引,实验发现唯一索引扫描部分索引也会range。
![]()
 当id > 1为条件时,系统选择了全表扫描。待解决。。。。。
当id > 1为条件时,系统选择了全表扫描。待解决。。。。。
(6)index:扫描整个索引就能拿到结果,一般时二级索引,这种查询一般为使用覆盖索引(需优化,缩小数据范围)
(7)all:扫描整个表进行匹配,即扫描聚簇索引树
all和index的区别:
all全表扫描,扫描整个索引树。
index一般发生在覆盖索引上,全表扫描整个辅助索引(二级索引)
但是index还有一种情况,请看。
explain
select id from users;![]()
上述用到了主键索引,type类型是index,extra是using index意思是使用到了覆盖索引。
我在这里纠结了很长时间,因为我认为使用二级索引不回表才是覆盖索引。
这里我们可以认为,主键索引是一个特殊的二级索引,没有回表,查找数据就是index覆盖索引。
问题(欢迎评论区解答):
explain
select * from users inner join orders on users.id = orders.id;
既然上述使用主键索引可以index,为什么驱动表类型不可以是index。可能表连接有些特殊情况,其中的水很深,我学到之后会完善这个问题。