08【保姆级】-GO语言的函数、包、错误处理
08【保姆级】-GO语言的函数、包、错误处理
- 一、 函数基本介绍
-
- 1.1 基本概念
- 1.2 包的概念
- 1.3 包使用的注意事项和细节
- 1.4 函数的调用机制
- 1.5 函数的递归调用
- 1.6 函数使用的注意事项和细节讨论
- 1.7 init函数
- 1.8 匿名函数
-
- 1.8.1 匿名函数使用方式
- 1.8.2 全局匿名函数
- 1.9 闭包
-
- 1.9.1 闭包的最佳实践
- 1.10 函数的defer
- 1.11 函数参数
-
- 1.11.1 两种传递方式
- 1.11.2 值类型和引用类型
- 1.12 变量的作用域
- 1.13 字符串常用的系统函数
- 1.14 时间和日期的常用函数
- 1.15 内置函数
- 二、错误处理
-
- 2.1 异常处理
- 2.2 自定义错误
之前我学过C、Java、Python语言时总结的经验:
- 先建立整体框架,然后再去抠细节。
- 先Know how,然后know why。
- 先做出来,然后再去一点点研究,才会事半功倍。
- 适当的囫囵吞枣。因为死抠某个知识点很浪费时间的。
- 对于GO语言,切记遵守语法格式规则。(例如python语言、例如SpringBoot框架等)
解释:某些知识点,就是很难了解,那么先做出来,然后继续向前学习,可能在某个时间点我们就会恍然大悟。
一、 函数基本介绍
1.1 基本概念
为完成某一功能的程序指令(语句)的集合,称为函数。
在Go语言中分为:自定义函数、系统函数。
func 函数名(形参列表) (返回值类型列表){
执行语句
return 返回值列表
}
1. 形参列表: 表示函数的输入
2. 函数中的语句:表示为了实现某一功能代码块
3. 函数可以有返回值,也可以没有
例子: j
func main() {
c := add(2, 5)
fmt.Println("c=", c)
}
func add(a int, b int) int {
c := a + b
return c
}
1.2 包的概念
- 在实际的开发中,我们往往需要在不同的文件中,去调用其它文件的定义的函数,比如 main.go中,去使用 utils.go 文件中的函数,如何实现? -》包
- 现在有两个程序员共同开发一个 Go 项目,程序员 xiaoming 希望定义函数 Cal,程序员 xiaoqiang也想定义函数也叫 Cal。两个程序员为此还吵了起来,怎么办?-》包
包的本质实际上就是创建不同的文件夹,来存放程序文件。
包的基本概念: go 的每一个文件都是属于一个包的,也就是说 go 是以包的形式来管理文件和项目目录结构
- 包的三大作用
- 区分相同名字的函数、变量等标识符
- 当程序文件很多时,可以很好的管理项目
- 控制函数、变量等访问范围,即作用域
- 包的基本语法
package 包名
- 引入包的基本语法
import "包的路径"
- 包使用的快速入门
包快速入门-Go 相互调用函数,我们将func Cal 定义到文件utils.go,将utils.go放入一个包中,当其他文件需要使用utils.go的方法时,可以import该包,就可以使用了。
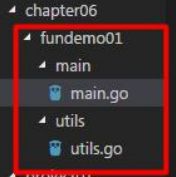
1.3 包使用的注意事项和细节
- 在给一个文件打包时,该包对应一个文件夹,比如这里的utils文件夹,对应的包名是utils,文件的包名通常和文件所在的文件夹名一致,一般为小写字母。
- 当一个文件要使用其它包函数或变量时,需要先引入对应的包。
引入方式1:import “包名”
引入方式2:
import(
"包名"
"包名"
)
package 指令在 文件第一行,然后是import指令
在import包时,路径从$GOPATH 的src下开始,不用带src,编译器会自动从src下开始引入。
-
为了让其他包的文件,可以访问到本包的函数,则该函数名的首字母需要大写,类似其他语言的public,这样才能跨包访问。比如 utils.go 的
-
在访问其他函数,变量时,其语法是 包名.函数名 ,比如这里的 main.go 文件中:
-
如果包名较长,Go支持给包取别名,注意细节:取别名后,原来的包名就不能使用了。
说明:如果给包取了别名,则需要使用别名来访问该包的函数和变量
- 在同一包下,不能有相同的函数名(也不能有相同的全局变量名),否则报重复定义
- 如果你要编译成一个可执行程序文件,就需要将这个包申明为main,既 package main。 这个就是一个语法规范,如果你是写一个库,包名可以自定义。
路径下写:
- src
- 项目名称
- 各个包名
1.4 函数的调用机制
关于栈区:
函数在调用的时候,基本数据类型,一般说分配到栈区,编译器存在一个逃逸分析
栈区:
add 栈区
main 栈区
- 在调用一个函数时,会给该函数分配一个新的空间,编译器会通过自身的处理,让这个新的空间和其他的栈的空间区分开来
- 在每个函数对应的栈中, 数据空间是独立的。不会混淆
- 当一个函数调用完毕(执行完毕)后,程序会销毁这个函数对应的栈空间。
func main() {
n := 10
add(n)
fmt.Println("main() 的n =", n) // main() 的n = 10
}
func add(n int) {
n = n + 1
fmt.Println("add() 的n =", n) // add() 的n = 11
}
1. 其中两个函数都是在栈中,当main函数只是将 n 的值 传给了add函数(值传递).
2. 这样说来,add更改n的值,并不会更改main的n的值.
3. 其中根据栈的原则,先进后出,main先进去的,所以,先打印add函数的println语句。
关于堆区:
堆区:引用数据类型一般说分配到堆区,编译器存在一个逃逸分析
代码区:
所有的代码存储到此位置。
案例要求:写一个函数,传入两个int值,返回两者的相加和相减
func main() {
n1 := 10
n2 := 5
add, sub := addOrSub(n1, n2)
fmt.Println("add=", add, "sub=", sub) // add= 15 sub= 5
}
func addOrSub(n1 int, n2 int) (int, int) {
return n1 + n2, n1 - n2
}
1.5 函数的递归调用
一个函数在函数体内 又 调用了本身,我们称为递归调用。
- 执行一个函数时,就创建一个新的受保护的独立空间(新函数栈)
- 函数的局部变量是独立的,不会相互影响
- 递归必须向退出递归的条件逼近,否则就是无限递归,死鬼了
- 当一个函数执行完毕,或者遇到return,就会返回,遵守谁调用,就将结果返回给谁,同时当函数执行完毕或者返回时,该函数本身也会被系统销毁。
递归的演示案例:
-- 第一种:
// 第一种自己的思路(方便理解):
// 当第1次调用test时,调用了递归,我们可以先把fmt.println打印的结果写出来,也就是3
// 当第2次调用test时,调用了递归,我们可以先把fmt.println打印的结果写出来,也就是2
// 当第3次调用test时,没有调用递归,我们可以先把fmt.println打印的结果写出来,也就是2
// 那么最后的结果,反推上去也就是:2/2/3
func main() {
n1 := 4
test(n1)
}
func test(n1 int) {
if n1 > 2 {
n1--
test(n1)
}
fmt.Println("n1=", n1)
}
n1= 2
n1= 2
n1= 3
-- 第二种:
// 自己的思路:
// 不管多少次递归,那么最后结果是,最后一次不符合if条件后,才会执行的else结果。
func main() {
n1 := 4
test(n1)
}
func test(n1 int) {
if n1 > 2 {
n1--
test(n1)
} else {
fmt.Println("n1=", n1)
}
}
n1= 2
1.6 函数使用的注意事项和细节讨论
- 函数的形参列表可以是多个,返回值列表也可以是多个。
- 形参列表和返回值列表的数据类型可以是值类型和引用类型。
- 函数的命名遵循标识符命名规范,首字母不能是数字,首字母大写该函数可以被本包文件和其它文件使用,类似public,首字母小写,只能被本包文件使用,其它包文件不能使用,类似private
- 函数中的变量是局部的,函数外不生效
- 基本数据类型和数组 默认都是值传递的,既进行值拷贝。在函数内修改,不会影响到原来的值
- 如果希望函数内的变量能修改函数外的变量(指的是 默认以值传递的方式的数据类型),而已传入的地址&,函数内以指针的方式操作变量。
func main() {
n1 := 4
test(&n1)
fmt.Println("main() n1=", n1) //main() n1= 14
}
func test(n1 *int) {
*n1 = *n1 + 10
fmt.Println("test() n1=", *n1) // test() n1= 14
}
- Go函数不支持函数重载。
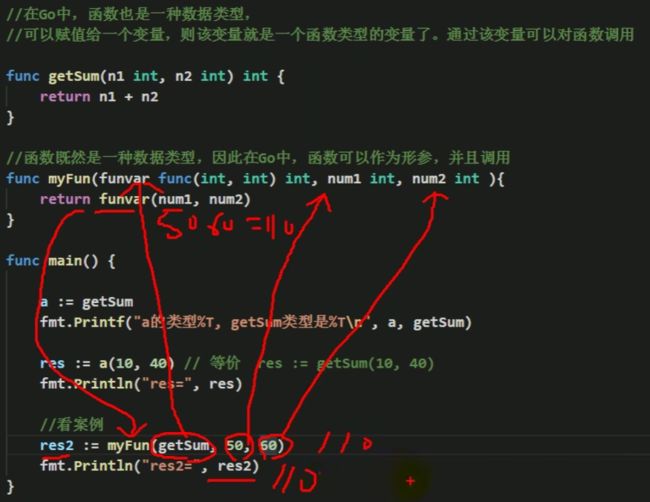
- 在Go中,函数也是一种数据类型 ,可以赋值给一个变量,则该变量就是一个函数类型的变量了。通过该变量可以对函数 调用。
func main() {
//在Go中,函数也是一种数据类型
a := getSum
fmt.Println(a(1, 2))
}
func getSum(n1 int, n2 int) int {
return n1 + n2
}
- 函数既然是一个种函数类型,因此在Go中,函数可以作为函数,并且调用。
1. myFun函数,将三个参数分别赋值给myFun() 其中func(int ,int)int 是一个类型。
funvar = getSum
num1 = 50
num2 = 60
2. 然后将 num1 和 num2 赋值给 funvar(num1,num2)
3. 根据第一点得知,funvar 等于 getSum函数。
4. 根据getSum()函数得知,n1 + n2 =50+60. 得到结果是110。getSum()函数返回110给的是res2
5. 切记:getSum返回的110,是返回给res2的
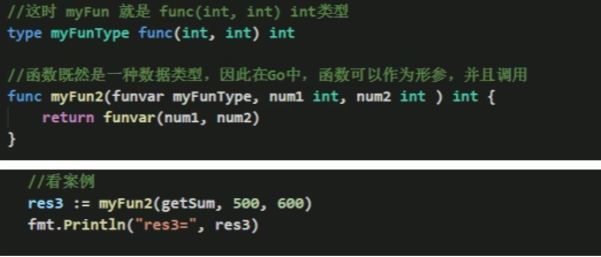
- 为了简化数据类型定义,Go支持自定义数据类型
基本语法:type 自定义数据类型名 数据类型
// 理解:相当于一个别名
案例:type myInt int
// 这时 myInt 就等价 int来使用了
// myInt 是一个类型,虽然根据定义是一个类型,是一个int类型,但是Go认为并不是同种类型。
//如代码:

案例:type mySum func(int,int)int
// 这时 mySum就等价 一个函数类型func(int,int) int
// 创建一个mySum 类型,该类型是一个函数,名为:func(int,int)int函数
- 支持对函数返回值命名
func main() {
var num1 int
var num2 int
num1 = 10
num2 = 10
add, sub := addOrSub(num1, num2)
fmt.Println("add=", add, "sub=", sub)
// add= 20 sub= 0
}
func addOrSub(num1 int, num2 int) (add int, sub int) {
add = num1 + num2
sub = num1 - num2
return
// 此时可以忽略掉 返回类型和顺序
}
- 只用 _ 标识符,忽略返回值
- Go支持可变参数
// 支持0到多个参数
func sunc(args... int ) sum int {
}
// 支持1到多个参数
func sum(n1 int ,args... int) sum int{
}
14. args是slice切片(可以理解java的数组),通过args[index] key访问到各个值
15. 如果一个函数的形参列表中有可变参数,则可变参数需要放在形参列表最后。
编写函数swap(n1 *int,n2 *int) 进行交换n1 和 n2的值
func main() {
var n1 int = 10
var n2 int = 20
fmt.Println("前n1=", n1, "前n2=", n2)
swap(&n1, &n2)
fmt.Println("后n1=", n1, "后n2=", n2)
//前n1= 10 前n2= 20
//后n1= 20 后n2= 10
}
func swap(a *int, b *int) {
var test int
test = *a
*a = *b
*b = test
}
1.7 init函数
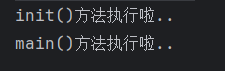
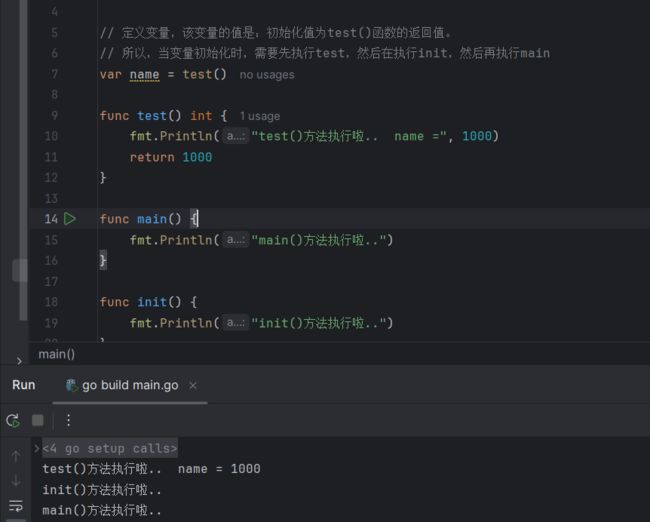
每一个源文件都可以包含一个init函数,该函数会在main函数执行前,被Go运行框架调用,也就是说init会在main函数前被调用。
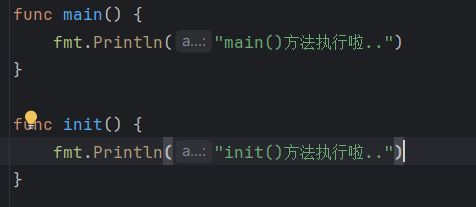
-
如果一个文件同时包含全局变量定义, init函数,和main函数 ,则 执行流程:全局变量定义 -> init 函数 -> main函数
- 当如果有被引入的包,那么会先执行被引入的包。例如 fmt 、 utils
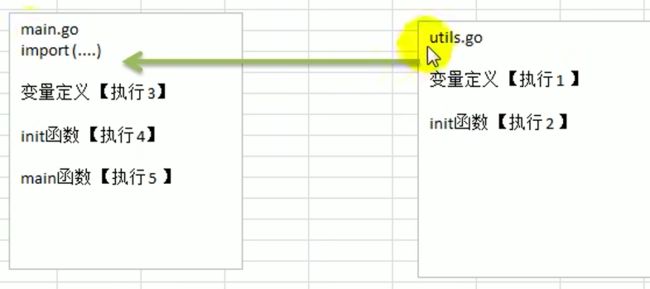
- 当如果有被引入的包,那么会先执行被引入的包。例如 fmt 、 utils
-
init函数最主要的作用,就是完成一些初始化的工作。
1.8 匿名函数
Go支持匿名函数,匿名函数就是没有名字的函数,如果我们某个函数只是希望使用一次,可以考虑使用匿名函数,匿名函数也可以实现多次调用。
1.8.1 匿名函数使用方式
在定义匿名函数时就直接调用,这种方式匿名函数只能调用一次。
// 在定义匿名函数时就直接调用,这种方式匿名函数只能调用一次。
func main() {
resAdd := func(a int, b int) int {
return a + b
}(1, 2)
fmt.Println("resAdd=", resAdd) // resAdd= 3
}
将匿名函数赋给一个变量(函数变量),再通过该变量来调用匿名函数
resSub := func(c int, d int) int {
return c - d
}
sub := resSub(1, 2)
fmt.Println("sub=", sub) // sub= -1
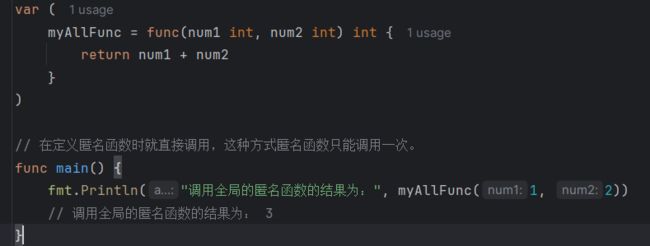
1.8.2 全局匿名函数
如果将匿名函数赋给一个全局变量,那么这个匿名变量,就成为一个全局匿名函数,可以在程序有效。
var (
myAllFunc = func(num1 int, num2 int) int {
return num1 + num2
}
)
// 在定义匿名函数时就直接调用,这种方式匿名函数只能调用一次。
func main() {
fmt.Println("调用全局的匿名函数的结果为:", myAllFunc(1, 2))
// 调用全局的匿名函数的结果为: 3
}
1.9 闭包
闭包就是一个函数和与其相关的引用环境组合的一个整体(实体)
- AddUpper 是一个函数,返回的数据类型是fun (int) int
- 闭包的说明
返回的是一个匿名函数,但是这个匿名函数引用到函数外的 n,因此这个匿名函数就和n形成个整体,构成闭包。 - 大家可以这样理解: 闭包是类,函数是操作,n 是字段。函数和它使用到 n 构成闭包。
- 当我们反复的调用 f函数时,因为 n 是初始化一次,因此每调用一次就进行累计。
- 我们要搞清楚闭包的关键,就是要分析出返回的函数它使用(引用)到哪些变量,因为函数和它引用到的变量共同构成闭包。
1.9.1 闭包的最佳实践
- 编写一个函数 makeSuffix(sufix string) 可以接收一个文件后缀名(比如jpg),并返回一个闭包2. 调用闭包,可以传入一个文件名,如果该文件名没有指定的后缀(比如.jpg),则返回 文件名jpg,如果已经有.ipg 后缀,则返回原文件名。
- 要求使用闭包的方式完成
- strings.HasSuffix,该函数可以判断某个字符串是否有指定的后缀。
package main
import (
"fmt"
"strings"
)
func main() {
res := makeSuffix(".txt")
fmt.Println("测试的名字是:", res("zhangsan1.txt"))
}
func makeSuffix(houzhui string) func(name string) string {
return func(name string) string {
// 判断如果输入的name后缀有huizhui,那么为true。 (! 取反)
if !strings.HasSuffix(name, houzhui) {
return name + houzhui + "a"
}
return name
}
}
1.10 函数的defer
在函数中,程序员经常需要创建资源(比如: 数据库连接、文件句柄、锁等) ,为了在函数执行完毕后,及时的释放资源,Go 的设计者提供 defer(延时机制)。
- 当 go 执行到一个 defer 时,不会立即执行 defer 后的语句,而是将 defer 后的语句压入到一个栈中[我为了讲课方便,暂时称该栈为 defer 栈1然后继续执行函数下一个语句。
- 当函数执行完毕后,在从 defer 中,依次从栈顶取出语句执行(注:遵守栈 先入后出的机制).
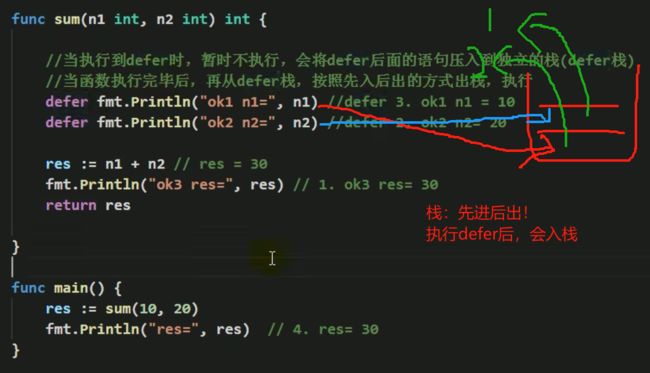
- 在 defer 将语句放入到栈时,也会将相关的值拷贝同时入栈。
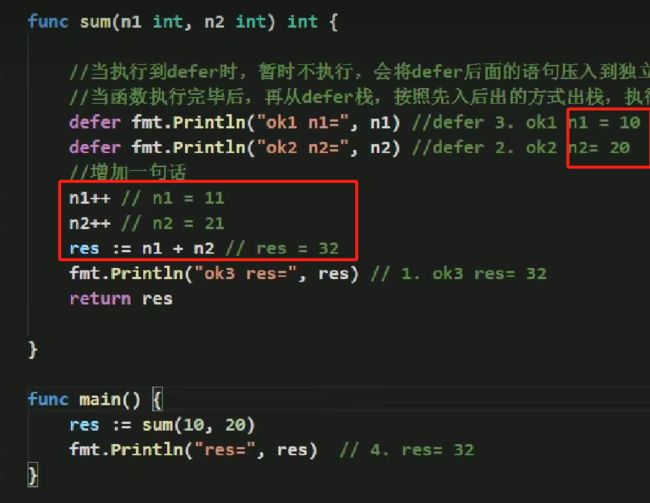
- defer 最主要的价值是在,当函数执行完毕后,可以及时的释放函数创建的资源
- 在 golang 编程中的通常做法是,创建资源后,比如(打开了文件,获取了数据库的链接,或者是锁资源,可以执行 defer file.Close() defer connect.Close()
- 在 defer 后,可以继续使用创建资源.
- 当函数完毕后,系统会依次从 defer 栈中,取出语句,关闭资源
- 这种机制,非常简洁,程序员不用再为在什么时机关闭资源而烦心。
1.11 函数参数
1.11.1 两种传递方式
- 值传递
- 引用传递
其实,不管是值传递还是引用传递,传递给函数的都是变量的副本,不同的是,值传递的是值的拷贝,引用传递的是地址的拷贝,一般来说,地址拷贝效率高,因为数据量小,而值拷贝决定拷贝的数据大小,数据越大,效率越低。
1.11.2 值类型和引用类型
-
值类型:基本数据类型 int 系列,flat 系列,bool,string 、数组和结构体 struct
-
引用类型: 指针、slice 切片、map、管道 chan、interface 等都是引用类型
-
值类型默认是值传递:变量直接存储值,内存通常在栈中分配
-
引用类型默认是引用传递,变量存储的是一个地址,这个地址对应的空间才真正存储数据(值),内存通常在堆上分配,当没有任何变量引用这个地址时,该地址对应的数据空间就成为一个垃圾,由GC来回收。
-
如果希望函数内的变量能修改函数外的变量,可以传入变量的地址&,函数内以指针的方式操作变量。从效果上看类似引用 。
1.12 变量的作用域
- 函数内部声明/定义的变量叫局部变量,作用域仅限于函数内部
- 函数外部声明/定义的变量叫全局变量,作用域在整个包都有效,如果其首字母为大写,则作用域在整个程序有效
- 如果变量是在一个代码块,比如 for /if 中,那么这个变量的的作用域就在该代码块
1.13 字符串常用的系统函数
-
统计字符串的长度,按字节 len(str)

-
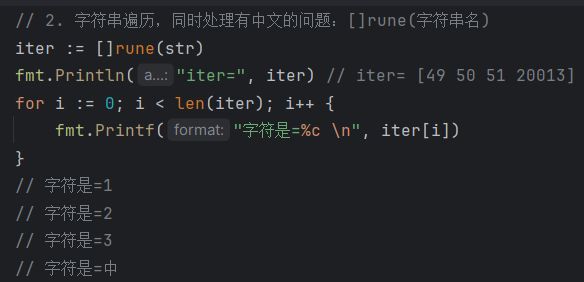
字符串遍历,同时处理有中文的问题r:=[]rune(str)
-
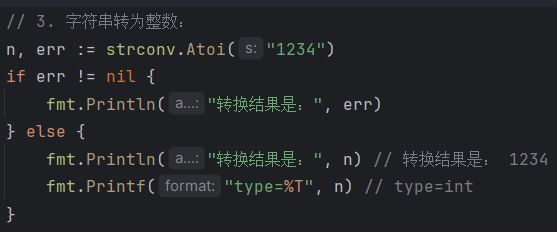
字符串转整数: n,err := strconv.Atoi(”12"”)
-
整数转字符串 str = strconv.ltoa(12345)
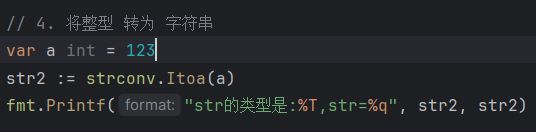
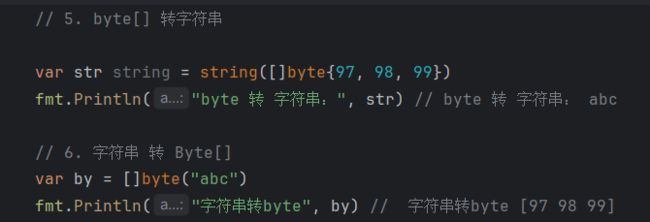
-
字符串转[Ibyte: var bytes = []byte(“hello go”)
// 5. byte[] 转字符串
var str string = string([]byte{97, 98, 99})
fmt.Println("byte 转 字符串:", str) // byte 转 字符串: abc
// 6. 字符串 转 Byte[]
var by = []byte("abc")
fmt.Println("字符串转byte", by) // 字符串转byte [97 98 99]
-
[]byte转字符串:str=string([]byte(97,98, 99}
-
10进制转 2,8,16进制: str=strconv,Formatlnt(123,2) // 2-> 8,16

-
查找子串是否在指定的字符串中: strings.Contains("seafood”,“foo”) //true

-
统计一个字符串有几个指定的子串 : strings.Count(“ceheese”,“e”)//4

-
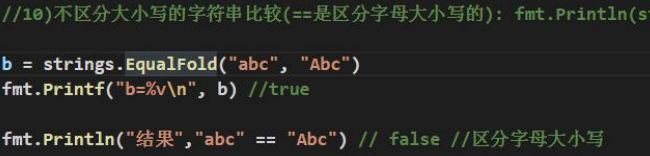
不区分大小写的字符串比较(==是区分字母大小写的):fmt,Println(strings.EqualFold("abc”,“Abc”) true
-
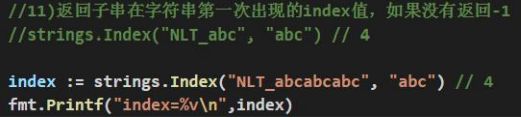
返回子串在字符串第一次出现的index值,如果没有返回-1 :strings.Index(“NLT abc”,“abc”)//4
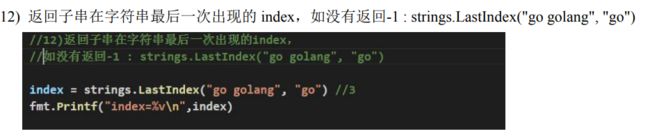
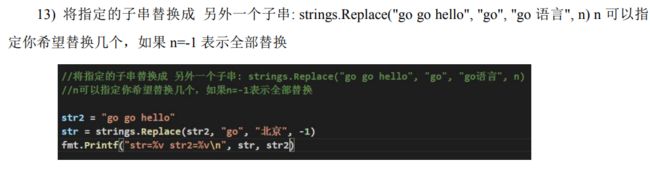
1.14 时间和日期的常用函数
package time
import "time"
time包提供了时间的显示和测量用的函数。日历的计算采用的是公历。
获取时间
// 1. 获取当前的时间
nowTime := time.Now()
fmt.Println(nowTime)
//2023-11-19 17:53:20.8044591 +0800 CST m=+0.001999601
分别获取年月日
// 2.获取年月日、时分秒
fmt.Println("年:", nowTime.Year()) // 年: 2023
fmt.Println("月:", int(nowTime.Month())) // 月: November
// 强转INt类型后:月: 11
fmt.Println("日:", nowTime.Day()) // 日: 19
fmt.Println("时:", nowTime.Hour()) // 时: 17
fmt.Println("分:", nowTime.Minute()) // 分: 57
fmt.Println("秒:", nowTime.Second()) // 秒: 31
格式化时间
2006/01/02 15:04:05”这个字符串的各个数字是固定的,必须是这样写。
2006/01/02 15:04:05”这个字符串各个数字可以自由的组合,这样可以按程序需求来返回时间和日期
//3.格式化日期时间
fmt.Println(nowTime.Format("2006/01/02 15-04-05"))
// 2023/11/19 18-05-25
时间的常量
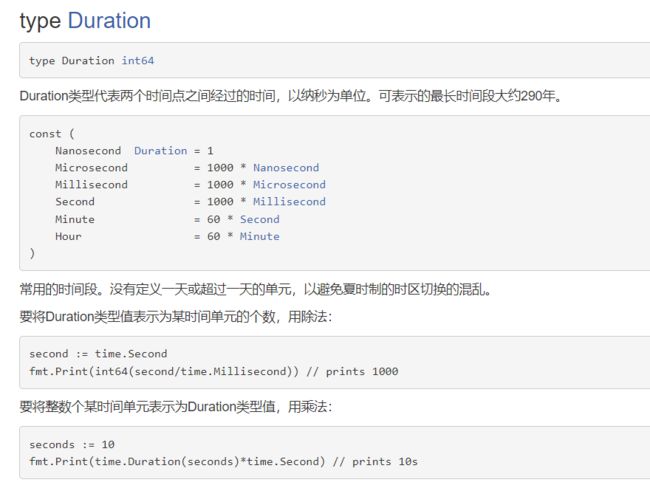
// 4. Go语言的常量。
// 时间单位是: 秒、毫秒、微秒、纳秒
//其中例子:1秒打印一次,以及1秒输出十次(也就是100毫秒)
i := 1
for ; ; i++ {
fmt.Println(i)
time.Sleep(time.Second) // 每次睡眠1秒
time.Sleep(time.Millisecond*100) // 每次睡眠 100毫秒,也就是0.1秒
if i == 5 {
break
}
}
获取时间戳,和纳秒时间戳。 例如获取一个随机数(当前时间戳)
// 5. 获取时间戳,和纳秒时间戳。 例如获取一个随机数(当前时间戳)
fmt.Println("unix时间戳是:", nowTime.Unix(), "纳秒时间戳是:", nowTime.UnixNano())
// unix时间戳是: 1700391072 纳秒时间戳是: 1700391072223348100
}
测试某个函数执行的时间:
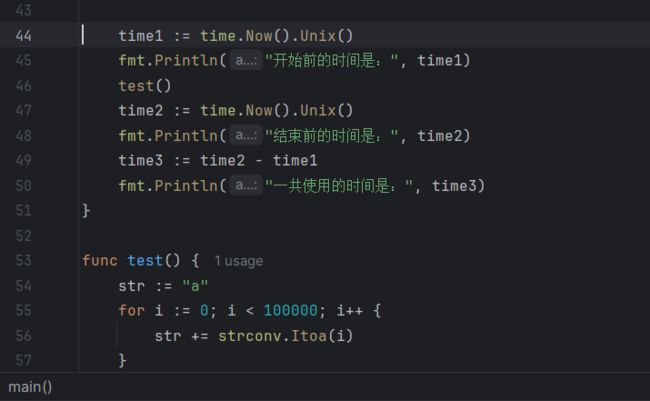
1.15 内置函数
new: 用来分配内存,主要用来分配值类型,比如 int、float32,struct…返回的是指针
举例说明new的使用:
二、错误处理
2.1 异常处理
- Go 语言追求简洁优雅,所以,Go 语言不支持传统的 try.··catch···finally 这种处理
- Go 中引入的处理方式为: defer,panic,recover
- 这几个异常的使用场景可以这么简单描述: Go 中可以抛出一个 panic 的异常,然后在 defer 中通过 recover 捕获这个异常,然后正常处理
defer + recover 来捕获和处理异常
func main() {
test()
fmt.Println("后续的代码是:--------------------")
}
func test() {
defer func() {
err := recover() // 内置函数,捕获异常
if err != nil { // 说明捕获结果
fmt.Println(err)
}
}()
n1 := 10
n2 := 0
res := n1 / n2
fmt.Println("res=", res)
}
- 打印的结果是:
runtime error: integer divide by zero
后续的代码是:--------------------
2.2 自定义错误
Go 程序中,也支持自定义错误, 使用 errors.New 和 panic 内置函数
- errors.New(“错误说明”),会返回一个 error 类型的值,表示一个错误
- panic 内置函数接收一个 interface类型的值(也就是任何值了)作为参数。可以接收 error 类型的变量,输出错误信息,并退出程序
func main() {
test()
fmt.Println("后续的代码....")
}
func recover2(s string) (err error) {
if s == "test.txt" {
return nil
} else {
return errors.New("读取文件错误")
}
}
func test() {
err := recover2("test.txt")
if err != nil {
panic(err)
// 如果读取文件失败后,就会输出该错误,并且终止程序
}
fmt.Println("test继续执行")
}