大数据篇--Kafka数据丢失、重复与消息顺序保证
文章目录
-
-
- 一、Kafka介绍
- 二、数据重复
-
- 1.Consumer重复消费数据:
- 2.幂等性:
- 3.事务:
- 三、数据丢失
- 四、Kafka的优化建议
-
- 1.broker端:
- 2.Producer优化(producer.properties):
- 3.comsumer端:
- 4.Kafka内存调整(kafka-server-start.sh):
- 五、消息顺序保证
-
- 1.kafka的特性:
- 2.问题:
- 3.解决方案:
- 六、其他(1 和 2 这两个知识点比较冷门,不看也可以)
-
- 1. 我的 kafkaoffsetmonitor 为什么无法监控到 offset 了?
- 2. kafka会利用checkpoint机制对offset进行持久化(这里的offset不是指消费者的消费位移,而是指其他位移)
- 3. 两种日志清理策略
-
参考官网: http://kafka.apache.org/documentation/
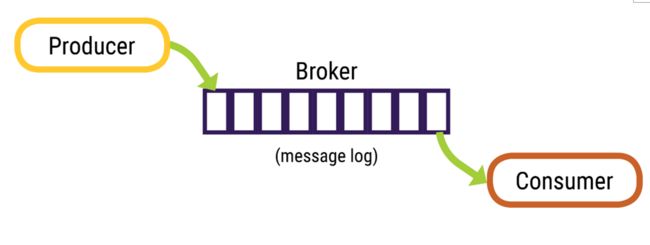
一、Kafka介绍
Kafka 是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的 Kafka 集群甚至可以做到每秒几十万、上百万的超高并发写入。可参考这篇文章:页缓存技术 + 磁盘顺序写 + 零拷贝技术
由 Producer(生产),Broker(存储)和Consumer(消费)三部分构成。
二、数据重复
1.Consumer重复消费数据:
底层根本原因:已经消费了数据,但是offset没提交。
- 重复消费最常见的原因:消费后的数据,当offset还没有提交时,partition就断开连接。比如,通常会遇到消费的数据,处理很耗时,导致超过了Kafka的session timeout时间(0.10.x版本默认是30秒),那么就会re-blance重平衡,此时有一定几率offset没提交,会导致重平衡后重复消费。
- 强行kill线程,导致消费后的数据,offset没有提交。
- 设置offset为自动提交,关闭kafka时,如果在close之前,调用 consumer.unsubscribe() 则有可能部分offset没提交,下次重启会重复消费。
- 当消费者重新分配partition的时候,可能出现从头开始消费的情况,导致重发问题。
- 当消费者消费的速度很慢的时候,可能在一个session周期内还未完成,导致心跳机制检测报告出问题。
在kafka 0.11版本中已经提出,kafka 将对事务和幂等性的支持,使得kafka 端到端exactly once(精确的一次)语义成为可能。幂等性与事务性都是Kafka发展过程中非常重要的。
2.幂等性:
参考:Kafka幂等性原理及实现剖析
Producer在生产发送消息时,难免会重复发送消息。Producer进行retry时会产生重试机制,发生消息重复发送或者消息乱序。而引入幂等性后,重复发送只会生成一条有效的消息。Kafka作为分布式消息系统,它的使用场景常见与分布式系统中,比如消息推送系统、业务平台系统(如物流平台、银行结算平台等)。以银行结算平台来说,业务方作为上游把数据上报到银行结算平台,如果一份数据被计算、处理多次,那么产生的影响会很严重。
在使用Kafka时,需要确保Exactly-Once语义。分布式系统中,一些不可控因素有很多,比如网络、OOM、FullGC等。在Kafka Broker确认Ack时,出现网络异常、FullGC、OOM等问题时导致Ack超时,Producer会进行重复发送。
Kafka为了实现幂等性,它在底层设计架构中引入了ProducerID和SequenceNumber。那这两个概念的用途是什么呢?
- ProducerID:在每个新的Producer初始化时,会被分配一个唯一的ProducerID,这个ProducerID对客户端使用者是不可见的。
- SequenceNumber:对于每个ProducerID,Producer发送数据的每个Topic和Partition都对应一个从0开始单调递增的SequenceNumber值。
Kafka在引入幂等性之前,Producer向Broker发送消息,然后Broker将消息追加到消息流中后给Producer返回Ack信号值。这是一种理想状态下的消息发送情况,但是实际情况中,会出现各种不确定的因素,比如在Producer在发送给Broker的时候出现网络异常。比如以下这种异常情况的出现:当Producer第一次发送消息给Broker时,Broker将消息(x2,y2)追加到了消息流中,但是在返回Ack信号给Producer时失败了(比如网络异常) 。此时,Producer端触发重试机制,将消息(x2,y2)重新发送给Broker,Broker接收到消息后,再次将该消息追加到消息流中,然后成功返回Ack信号给Producer。这样下来,消息流中就被重复追加了两条相同的(x2,y2)的消息。
生产者要使用幂等性很简单,只需要增加以下配置即可:enable.idempotence=true
3.事务:
与幂等性有关的另外一个特性就是事务。Kafka中的事务与数据库的事务类似,Kafka中的事务属性是指一系列的Producer生产消息和消费消息提交Offsets的操作在一个事务中,即原子性操作。对应的结果是同时成功或者同时失败。
这里需要与数据库中事务进行区别,操作数据库中的事务指一系列的增删查改,对Kafka来说,操作事务是指一系列的生产和消费等原子性操作。
数据传输的事务定义:
- 最多一次:消息不会被重复发送、最多被传输一次、但也有可能一次不传输
- 最少一次:消息不会被漏发送,最少被传输一次,但也有可能重复传输(消费端需要判断处理)
- 精确的一次(Exactly once):不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅传输一次
Producer提供了五种事务方法,它们分别是:initTransactions()、beginTransaction()、sendOffsetsToTransaction()、commitTransaction()、abortTransaction(),代码定义在org.apache.kafka.clients.producer.Producer
// 初始化事务,需要注意确保transation.id属性被分配
void initTransactions();
// 开启事务
void beginTransaction() throws ProducerFencedException;
// 为Consumer提供的在事务内Commit Offsets的操作
void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets,
String consumerGroupId) throws ProducerFencedException;
// 提交事务
void commitTransaction() throws ProducerFencedException;
// 放弃事务,类似于回滚事务的操作
void abortTransaction() throws ProducerFencedException;
三、数据丢失
数据丢失是一件非常严重的事情事,针对数据丢失的问题我们需要有明确的思路来确定问题所在。首先应该明确数据到底是在什么地方丢失的数据,在kafka之前的环节或者kafka之后的流程丢失?比如kafka的数据是由flume提供的,也许是flume丢失了数据,kafka自然就没有这一部分数据。
如果定位到是kafka环节丢失数据,那么常见的kafka环节丢失数据的原因有:
- 如果
auto.commit.enable=true(采用自动提交的机制),当consumer拿到了一些数据但还没有完全处理掉的时候,刚好到auto.commit.interval.ms(的默认值是 5000,单位是毫秒)发出了提交offset操作,接着consumer挂掉了。这时已经拿到的数据还没有处理完成但已经被commit掉,因此没有机会再次被处理,数据丢失。 - 网络负载很高或者磁盘很忙写入失败的情况下,没有自动重试重发消息。没有做限速处理,超出了网络带宽限速。kafka一定要配置上消息重试的机制,并且重试的时间间隔一定要长一些,默认1秒钟并不符合生产环境(网络中断时间有可能超过1秒)。
- 如果磁盘坏了,会丢失已经落盘的数据。
- 并行消费的场景下:如果多个Consumer 消费一个partition的数据时,有两条消息到达消费者: a 和 b。处理消息时,b 成功,并且提交了偏移量(offset)。但是,在处理消息 a 时产生了一个错误。此时,因为消息 b 有较大的偏移量,Kafka将保存最新的偏移量。所以消息 a 永远不会再发送给Consumer,数据丢失就这么产生了。为了避免这个问题最好选用组消费的方式:如果Consumer 在一个组内,并且使用的是Subscribe(自动分配取哪个区的数据),就不会发生上面的问题,因为:每个Consumer 取不同分区的数据,不存在同时消费一个partition数据的情况。
- Broker端:kafka的数据一开始就是存储在PageCache上的,定期flush到磁盘上的,也就是说,不是每个消息都被存储在磁盘了,如果出现断电或者机器故障等,PageCache上的数据就丢失了。
可以通过log.flush.interval.messages(在消息刷到磁盘之前,日志分区收集的消息数量,long型,默认值是9223372036854775807)和log.flush.interval.ms(主题中消息在刷到磁盘之前,保存在内存中的最长时间,单位是ms,如果不配置,使用log.flush.scheduler.interval.ms(单位为毫秒,日志刷新器检查日志是否需要刷到磁盘的频率,long型,默认为9223372036854775807)的配置,long型,默认为null)来配置flush间隔,无论哪个达到都会flush。interval大丢的数据多些,小会影响性能。设置较小定期 flush 的时间,并不能真正保证数据不会丢失,也就是说设置 flush 的时间,不能从根本上保证我们的数据丢失问题。 - partition leader在未完成副本数follows的备份时就宕机的情况,即使选举出了新的leader但是已经push的数据因为未备份就丢失了!可参考:https://developer.51cto.com/art/201903/593232.htm
kafka是多副本的,当你配置了同步复制之后。多个副本的数据都在PageCache里面,出现多个副本同时挂掉的概率比1个副本挂掉的概率就很小了。(官方推荐是通过副本来保证数据的完整性的)
当Producer向Leader发送数据时,可以通过acks参数设置数据可靠性的级别:
0: 不论写入是否成功,server不需要给Producer发送Response,如果发生异常,server会终止连接,触发Producer更新meta数据;
1: Leader写入成功后即发送Response,此种情况如果Leader fail,会丢失数据
all或者-1: 等待所有ISR接收到消息后再给Producer发送Response,这是最强保证
仅设置acks=-1也不能保证数据不丢失,当Isr列表中只有Leader时,同样有可能造成数据丢失。要保证数据不丢除了设置acks=-1, 还要保证ISR的大小大于等于2,具体参数设置:
request.required.acks:设置为-1 等待所有ISR列表中的Replica接收到消息后采算写成功;
min.insync.replicas: 设置为大于等于2,保证ISR中至少有两个Replica;
replica(副本)机制的代价就是需要更多资源,尤其是磁盘资源,kafka当前支持GZip和Snappy压缩,来缓解这个问题。
Producer要在吞吐率和数据可靠性之间做一个权衡 - 单批数据的长度超过限制会丢失数据,报kafka.common.MessageSizeTooLargeException异常。broker可复制的消息的最大字节数
replica.fetch.max.bytes。这个值应该比message.max.bytes大,否则broker会接收此消息,但无法将此消息复制出去,从而造成数据丢失。
四、Kafka的优化建议
1.broker端:
topic设置多分区,分区自适应所在机器,为了让各分区均匀分布在所在的broker中,分区数要大于broker数。分区是kafka进行并行读写的单位,是提升kafka速度的关键。
broker能接收消息的最大字节数message.max.bytes,这个值应该比消费端的fetch.message.max.bytes更小才对,否则broker就会因为消费端无法使用这个消息而挂起。Kafka设计的初衷是迅速处理短小的消息,一般10K大小的消息吞吐性能最好,但有时候,我们需要处理更大的消息,比如XML文档或JSON内容,一个消息差不多有10-100M,这种情况下,Kakfa应该如何处理?可参考:kafka发送字节过多引起的发送失败、kafka中处理超大消息的一些考虑、kafka处理超大消息的配置
参数调优(server.properties):
1、网络和IO操作线程配置优化
# broker 处理消息的最大线程数(默认为3)
num.network.threads = cpu核数+1
# broker 处理磁盘IO的线程数
num.io.threads=cpu核数*2
2、log数据文件刷盘策略
# 每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
# 每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000
3、日志保留策略配置
# 保留三天,也可以更短
log.retention.hours=72
4、Replica相关配置
offsets.topic.replication.factor:3
# 这个参数指新创建一个topic时,默认的Replica数量,Replica过少会影响数据的可用性,太多则会白白浪费存储资源,一般建议在2~3为宜。
2.Producer优化(producer.properties):
buffer.memory:33554432 (32m)
#在Producer端用来存放尚未发送出去的Message的缓冲区大小。缓冲区满了之后可以选择阻塞发送或抛出异常,由block.on.buffer.full的配置来决定。
compression.type:none
# 默认发送不进行压缩,推荐配置一种适合的压缩算法,可以大幅度的减缓网络压力和Broker的存储压力。
3.comsumer端:
关闭自动更新offset,等到数据被处理后再手动跟新offset。在消费前做验证前拿取的数据是否是接着上回消费的数据,不正确则return先行处理排错。手动维护Offset可参考:https://blog.csdn.net/qq_20641565/article/details/64440425、https://blog.csdn.net/qq_38483094/article/details/99118140、https://www.cnblogs.com/wh984763176/p/13809346.html
这个是总结出的到目前为止没有发生丢失数据的情况:
//producer用于压缩数据的压缩类型。默认是无压缩。正确的选项值是none、gzip、snappy。压缩最好用于批量处理,批量处理消息越多,压缩性能越好
props.put("compression.type", "gzip");
//增加延迟
props.put("linger.ms", "50");
//这意味着leader需要等待所有备份都成功写入日志,这种策略会保证只要有一个备份存活就不会丢失数据。这是最强的保证。,
props.put("acks", "all");
//无限重试,直到你意识到出现了问题,设置大于0的值将使客户端重新发送任何数据,一旦这些数据发送失败。注意,这些重试与客户端接收到发送错误时的重试没有什么不同。允许重试将潜在的改变数据的顺序,如果这两个消息记录都是发送到同一个partition,则第一个消息失败第二个发送成功,则第二条消息会比第一条消息出现要早。
props.put("retries ", MAX_VALUE);
props.put("reconnect.backoff.ms ", 20000);
props.put("retry.backoff.ms", 20000);
//关闭unclean leader选举,即不允许非ISR中的副本被选举为leader,以避免数据丢失
props.put("unclean.leader.election.enable", false);
//关闭自动提交offset
props.put("enable.auto.commit", false);
//限制客户端在单个连接上能够发送的未响应请求的个数。设置此值是1表示kafka broker在响应请求之前client不能再向同一个broker发送请求。注意:设置此参数是为了避免消息乱序
props.put("max.in.flight.requests.per.connection", 1);
4.Kafka内存调整(kafka-server-start.sh):
# 默认内存1个G,生产环境调整为4-6个G,尽量不要超过6个G,因为超过6G的上限后和6G效果一样。
export KAFKA_HEAP_OPTS="-Xms4g -Xmx4g"
扩展:Push vs. Pull:
作为一个messaging system,Kafka遵循了传统的方式,选择由producer向broker push消息并由consumer从broker pull消息。事实上,push模式和pull模式各有优劣。
push模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。push模式的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。
五、消息顺序保证
1.kafka的特性:
- kafka中,写入一个partion照片中的数据是一定有顺序的。(为什么只保证单partition有序?如果Kafka要保证多个partition有序,不仅broker保存的数据要保持顺序,消费时也要按序消费。假设partition1堵了,为了有序,那partition2以及后续的分区也不能被消费,这种情况下,Kafka 就退化成了单一队列,毫无并发性可言,极大降低系统性能。因此Kafka使用多partition的概念,并且只保证单partition有序。这样不同partiiton之间不会干扰对方。)可参考:Kafka 源码解析之 Producer 单 Partition 顺序性实现及配置说明
- kafka中一个消费者消费一个partion的数据,消费者取出数据时,也是有顺序的。
2.问题:
比如说我们建了一个 topic,有三个 partition。生产者在写的时候,其实可以指定一个 key,比如说我们指定了某个订单 id 作为 key,那么这个订单相关的数据,一定会被分发到同一个 partition 中去,而且这个 partition 中的数据一定是有顺序的。
消费者从 partition 中取出来数据的时候(kafka的消费组的组员 consumer 数量最多增加到和partition数量一致,超过的组员只会占用资源,而不起作用),也一定是有顺序的。到这里,顺序还是 ok 的,没有错乱。接着,我们在消费者里可能会搞多个线程来并发处理消息。因为如果消费者是单线程消费处理,而处理比较耗时的话,比如处理一条消息耗时几十 ms,那么 1 秒钟只能处理几十条消息,这吞吐量太低了。而多个线程并发跑的话,顺序可能就乱掉了。
3.解决方案:
- 一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
- 写 N 个内存 queue,具有相同 key 的数据(可以做hash分发)都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。
六、其他(1 和 2 这两个知识点比较冷门,不看也可以)
1. 我的 kafkaoffsetmonitor 为什么无法监控到 offset 了?
实际上,Kafka 0.9 开始提供了新版本的 consumer 及 consumer group,位移的管理与保存机制发生了很大的变化——新版本 consumer 默认将不再保存位移到 zookeeper 中,而目前 kafkaoffsetmonitor 还没有应对这种变化(虽然已经有很多人在要求他们改了),所以很有可能是因为你使用了新版本的 consumer 才无法看到的。关于新旧版本,这里统一说明一下:kafka 0.9 以前的 consumer 是使用 Scala 编写的,包名结构是kafka.consumer.*,分为 high-level consumer 和low-level consumer 两种。我们熟知的 ConsumerConnector、ZookeeperConsumerConnector 以及 SimpleConsumer 就是这个版本提供的;自 0.9 版本开始,Kafka 提供了 java 版本的 consumer,包名结构是o.a.k.clients.consumer.*,熟知的类包括 KafkaConsumer 和 ConsumerRecord 等。新版本的 consumer 可以单独部署,不再需要依赖 server 端的代码。
老版本的位移是提交到 zookeeper 中的,目录结构是:/consumers/,但是 zookeeper 其实并不适合进行大批量的读写操作,尤其是写操作。因此 kafka 提供了另一种解决方案:增加 __consumeroffsets topic,将 offset 信息写入这个 topic,摆脱对 zookeeper 的依赖(指保存 offset 这件事情)。__consumer_offsets 中的消息保存了每个 consumer group 某一时刻提交的 offset 信息。新版 Kafka 已推荐将 consumer 的位移信息保存在 Kafka 内部的 topic 中,即 __consumer_offsets topic,并且默认提供了 kafka_consumer_groups.sh 脚本供用户查看 consumer 信息。
__consumers_offsets topic 配置了 compact 策略,使得它总是能够保存最新的位移信息,既控制了该 topic 总体的日志容量,也能实现保存最新 offset 的目的。compact 的具体原理请参见:Log Compaction
2. kafka会利用checkpoint机制对offset进行持久化(这里的offset不是指消费者的消费位移,而是指其他位移)
checkpoint:参考:https://www.zhihu.com/question/426382418
“kafka会利用checkpoint机制对offset进行持久化” — 这里的offset不是指消费者的消费位移,而是指其他位移,而持久化应该是指Kafka把位移数据保存到Broker本地磁盘文件这件事。目前,Kafka对三类位移做checkpointing:Log Start Offset;Recovery Point Offset;Replication Offset。
第一个。每个topic partition log对象都有一个重要的位移字段:log start offset,标识分区消息对外部用户或应用可见的最早消息位移。在一些事件发生时Kafka会触发对该值的更新。Kafka对该offset进行checkpointing的初衷是更快地保存分区的元数据,这样下次再初始化Log对象时能够直接加载并初始化log start offset。
第二个是recovery point offset,它保存的是第一条未flush到磁盘的消息。Kafka对它进行checkpointing能够显著加速日志段恢复(recover)的速度,因为直接从recovery point offset所在的日志段开始恢复即可,没必要从头恢复日志段。毕竟生产环境上,分区下的日志段文件可能是非常多的。
第三个是replication offset,保存replication过程中副本的高水位(HW)位移值。通常的场景是当副本重启回来后创建Log对象时直接使用这个文件中的offset对高水位对象进行赋值,省去了读取日志段自行计算HW值的步骤。
总之,checkpointing大体的作用都是将Kafka Broker端重要的日志元数据保存下来,避免后面“书到用时方恨少”的尴尬。
3. 两种日志清理策略
Kafka将消息存储在磁盘中,为了控制磁盘占用空间的不断增加就需要对消息做一定的清理操作。Kafka中每一个分区partition都对应一个日志文件,而日志文件又可以分为多个日志分段文件,这样也便于日志的清理操作。Kafka提供了两种日志清理策略:日志删除(Log Deletion):按照一定的保留策略来直接删除不符合条件的日志分段;日志压缩(Log Compaction):针对每个消息的key进行整合,对于有相同key的的不同value值,只保留最后一个版本。可参考:Kafka日志清理之Log Deletion
我们可以通过broker端参数log.cleanup.policy来设置日志清理策略,此参数默认值为“delete”,即采用日志删除的清理策略。如果要采用日志压缩的清理策略的话,就需要将log.cleanup.policy设置为“compact”,并且还需要将log.cleaner.enable(默认值为true)设定为true。通过将log.cleanup.policy参数设置为“delete,compact”还可以同时支持日志删除和日志压缩两种策略。日志清理的粒度可以控制到topic级别,比如与log.cleanup.policy对应的主题级别的参数为cleanup.policy,为了简化说明,本文只采用broker端参数做陈述,如若需要topic级别的参数可以查看官方文档。