2019 DGF(深度引导滤波网络) 相关的论文笔记
文章目录
- *Fast End-to-End Trainable Guided Filter*
- *KeyPoint*
-
- *overview*
- *keywords*
- *extends*
- 摘要
- 引言
- 相关工作
-
- *Joint Upsampling*
- *Deep Learning based Image Filter*
- *Guided Filtering Layer* 引导滤波层
-
- ***Problem Formulation***
- ***Guided Filter Revisited***(重新审视引导过滤器)
- *Fully Differentiable Guided Filter*
- *Learn to Generate Task-Specific Guidance Map*
- *Convolutional Guided Filtering Layer*
- *Deep Guided Filtering Network* 深度引导滤波网络
-
- *Fully Convolutional Network* * C l C_l Cl*(* I l I_l Il*)
- *Guided Filtering Layer*
- *Objective Function*
- 图像处理任务的实验
-
- *Details of Five Image Processing Operators*
- *Details of DGF*
- *Experimental Setup*
- *Experimental Results*
- 计算机视觉任务的实验
-
- 三个计算机视觉任务的细节
- *Details of DGF*
- *Main Results*
- 结论
- 结论
Fast End-to-End Trainable Guided Filter
代码地址
KeyPoint
overview
该论文提出了一种DGF深度引导滤波网络,能够很好的模拟(clone)图像处理操作,特别是能够模拟语义分割中CRF的操作。同时该论文提出的模块相比其他操作要快非常多倍,还能够有效的解决因为神经网络降采样操作导致的分辨率下降问题,使得图像的分辨率得到进一步提高(相当于图像的上采样)。
keywords
joint upsampling:*联合上采样,其目的是在给定相应的低分辨率输出和高分辨率引导图时生成高分辨率输出。其方法主要有bilateral filter和guided fliter*
bilateral filter:双边滤波
deep bilateral learning:深度双侧学习,集成了双侧滤波器与FCNs
Deep Guided Filtering Network (DGF):深度引导滤波器网络
guided fliter:引导滤波
guided filtering layer:引导滤波层,用来处理联合上采样(joint upsampling)
guidance map:引导图
end-to-end training:端到端训练
Pixel-wise Image Prediction
extends
edge-preserving local filters
dilated convolution
pointwise convolution
摘要
摘要:利用全卷积网络(FCNs)的能力,提高了密集像素级的图像预测技术。FCN的一个中心问题是处理联合上采样的能力有限。为了解决这一问题,我们提出了一种新的FCNs构建块,即引导滤波层,它被设计为在相应的低分辨率输出和高分辨率引导图下有效地生成高分辨率输出。
该层包含可学习的参数,可以与fcn集成,并通过端到端训练进行联合优化。为了进一步利用端到端训练,我们插入了一个可训练的转换函数来生成特定任务的指导图。在此基础上,我们提出了一个像素级图像预测的通用框架,称为深度引导滤波网络(DGF)。通过5个图像处理任务对该网络进行了评估。在MIT-AdobeFiveK数据集上进行的实验表明,DGF的运行速度要快10-100倍,并达到了最先进的性能。我们还表明,DGF有助于提高多个计算机视觉任务的性能。
引言
密集像素级图像预测是一个基本的图像处理和计算机视觉问题,具有广泛的应用范围。在图像处理中,密集的像素级图像预测能够平滑图像,同时保留边缘[7]–[9],,增强图像细节[3],[10],从参考图像转换风格[11],[12],照片去雾[4],[13]–[15],和修饰图像以进行全局色调调整[2]。在计算机视觉中,像素级图像预测不仅解决了将图像分割成语义部分的问题 [16]-[18],但也有助于从单个图像中估计深度 [19],和检测图像中最显着的对象 [20], [21]。
最近的方法[22]-[24]通常为这些应用程序使用全卷积网络(FCNs),实现了最先进的性能。然而,FCNs在高分辨率输入图像上通常具有巨大的计算复杂度和内存使用,这限制了像素级图像预测算法在现实应用中的部署。为了加速fcn,我们采用了从粗到细的方式提出了一个一般框架,首先对输入图像进行下采样,以低分辨率执行算法,然后将结果上采样到原始分辨率。主要的挑战是将低分辨率的输出恢复到原始的分辨率与丰富的细节和尖锐的边缘。
这一挑战可以表述为联合上采样,其目的是在给定相应的低分辨率输出和高分辨率引导图时生成高分辨率输出。然而,现有的fcn的构建块处理这类问题的能力有限。为了提高FCNs联合上采样的能力,我们建议将广泛使用的引导滤波器[25]重新构建成一个完全可拆分的模块,可以
(1)与FCNs联合训练,(2)通过可学习参数适应不同的任务,(3)直接由高分辨率GT监督。
为此,我们提出了一种名为引导滤波层的新型构建块。具体地说,原始的引导滤波器被表示为一个由扩展卷积和点态卷积组成的计算图*(computational graph)*,可以针对不同的任务进行自适应演化。 提出的层中引入了可训练的转换函数,可以生成特定于任务的引导图。
因此,可以通过端到端训练以数据驱动的方式学习引导过滤层的所有参数。
此外,这样的层可以很容易地与预定义的FCN集成,而不需要额外的努力。通过为FCNs配置引导滤波层,我们提出了一个像素级图像预测任务的通用框架,即深度引导滤波网络(DGF),它可以在很大程度上降低计算复杂度和内存使用。该框架可广泛应用于许多图像处理和计算机视觉任务,如图1所示。实验表明,DGF在质量、速度和内存使用方面都取得了最先进的性能。

注:深度引导过滤网络的示例结果。上一行表示输入图像,下一行表示相应的输出。从左到右:图像润色(image retouching)[2]、多尺度细节操作[3]、非局部去雾(non-local dehazing)[4]、显著性检测( saliency detection)[5]和深度估计[6]。最好用颜色观看。
总而言之,本文的主要贡献是
(1)我们开发了一个端到端可训练的引导滤波层,具有可学习参数和可训练的引导图,提高了FCNs进行联合上采样的能力;
(2)结合FCNs,提出的层显著提高了多个图像处理任务的最先进结果,并比其他方法运行快10-100×;
(3)附加实验表明,我们的方法可以很好地推广到许多计算机视觉任务,并比基线方法取得了显著的改进。
本文的早期版本[1]出现在IEEE计算机视觉和模式识别会议(2018)上,我们对该会议进行了实质性的扩展。改进如下所示:
(1)[1]将原始引导滤波器公式化为一系列空间变化的线性变换矩阵,没有任何可学习的参数。在本文中,我们将原始的引导滤波器重新构造成一个具有可学习参数的扩展卷积和逐点卷积块。这样的形式使引导过滤层能够通过端到端训练来适应特定的任务。
(2)在改进的引导滤波层的基础上,进一步提高了DGF在5个图像处理任务中的性能。
(3)我们对5个图像处理任务进行了系统的消融研究,以分析DGF中每个超参数的影响。
(4)我们通过一个全面的实验证明了该层的联合上采样能力的上限。
(5)发布了训练代码和测试代码,以重现本文的实验结果,并支持进一步的研究和其他应用。
相关工作
Joint Upsampling
与我们的方法最相关的工作是联合上采样的方向。许多算法已经被开发出来来解决这个问题。联合双侧上采样[26]将双侧滤波器[27]应用于高分辨率引导图,从而得到分段平滑的高分辨率输出。底层的双边过滤器通常需要大量的计算资源。因此,提出了许多方法[28]-[30]来降低计算复杂度。Barron 等人建立在联合双边上采样的基础上。 [31] 提出一个新的双边空间优化的一种形式,它有效地解决了正则化的最小二乘优化问题,以产生双边平滑且接近输入的输出。 加尔比等人。 [32]首先计算从高度压缩的输入到输出的转换的描述。 然后可以通过将配方*(recipe)*应用于高质量输入来构建输出的高保真近似值。
类似地,双边引导上采样[33]首先在低分辨率的输入/输出对上匹配一个具有局部仿射模型网格的图像算子。然后,通过将局部仿射模型应用于高分辨率的输入图像,生成高分辨率的输出。该方法只是作为一个后处理操作,而我们的方法可以与整个FCN联合训练。深度双侧学习[22]将双侧滤波器与FCNs集成,可以通过端到端训练联合学习。然而,该方法需要在获得输出之前产生仿射系数,这缺乏对地面真相的直接监督。对于计算机视觉任务,仿射系数的数量通常非常大,这成为性能和速度的瓶颈。除了双边滤波器外,引导滤波器[25],派生自一个局部线性模型,也被广泛应用于联合上采样,通过考虑引导图像*(guidance image)*的内容来计算滤波输出。与此相比,我们的方法被描述为一个具有可学习参数的完全可微的构建块,它可以与fcn联合训练,并根据特定的任务进行自适应调整。同样,Yuan等人。[34]采用局部仿射模型,将patches从低分辨率RAW图像与高分辨率JPEG图像联系起来。
上述方法都是基于保持边缘的局部滤波器。不同的是,其他方法 [35]-[37] 通过优化手动设计的涉及所有或多个像素的目标函数来产生高分辨率输出。目标函数通常由数据项和正则化项组成,如总变化(TV)[35]、加权最小二乘(WLS)[36]和尺度映射方案[37]。遵循这些方法,Shen等人。[38]提出了*互结构*(mutual-structure)来保留两幅图像中包含的结构信息。同样,Ham等人。[39]将该问题表述为一个非凸优化问题,并由优化-最小化算法来解决。与我们的方法相比,这些方法的主要缺点是(1),它们依赖于手工设计的目标函数,而(2),它们通常很耗时。
Deep Learning based Image Filter
近年来,基于深度学习的方法在图像处理任务被提出,这在很大程度上提高了最先进的性能。这些任务包括图像去噪[40]、图像去除[41]、图像去模糊[42]、图像匹配[43]、雨滴去除[44]、图像去模糊[45]和图像着色[46]。上述方法主要集中于解决一个特定的图像处理任务。不同的是,其他一些工作 [47]-[49] 旨在逼近一般类别的算子。Xu等人。[47]使用深度神经网络用梯度域*( gradient-domain)训练程序来近似各种边缘保持**(edge-preserving)***滤波器,而Liu等人。[48]结合了一个卷积网络和一组递归网络来近似各种图像滤波器。
Xu等人。[47]和Liu等人。[48]部署神经网络来直接生成高分辨率的输出,通过专门设计的网络架构来加速运行。同样,Chen等人。[23]提出了上下文聚合网络***(context aggregation networks)***加速各种图像处理操作。其性能优于之前的工作[33]、[47]、[48]、[50]、[51],在速度和精度方面达到最佳效果。我们的方法是对这种方法的补充,它可以提供可比或更好的结果,运行速度提高 10-100 倍。与所有相关工作相比,所提出的引导滤波层可以通过整个网络进行端到端训练,并推广从图像处理到计算机视觉的不同任务,同时在质量和速度上都取得了最先进的性能。
Guided Filtering Layer 引导滤波层
Problem Formulation
给定一个高分辨率图像 I h I_h Ih和相应的低分辨率输出 O l O_l Ol,联合上采样的目的是生成一个高分辨率输出 O h O_h Oh,在视觉上类似于 O l O_l Ol,并保留了 I h I_h Ih的边缘和细节。在联合上采样的文献中,引导滤波器[25]是应用最广泛的算法之一,在速度和精度的权衡方面而言表现出更好的性能。
Guided Filter Revisited(重新审视引导过滤器)
为了解决联合上采样问题,引导滤波器[25]以低分辨率图像 I l I_l Il、相应的高分辨率图像 I h I_h Ih和低分辨率输出 O l O_l Ol作为输入,产生高分辨率输出 O h O_h Oh。具体地说, A l A_l Al和 b l b_l bl首先是通过最小化 O l ^ \hat{O_l} Ol^和 O l O_l Ol之间的重建误差得到的,其中 O l ^ \hat{O_l} Ol^采用局部线性模型:
O ^ l i = A l k I l i + b l k , ∀ i ∈ ω k \hat{O}_{l}^{i}=A_{l}^{k} I_{l}^{i}+b_{l}^{k}, \forall i \in \omega_{k} O^li=AlkIli+blk,∀i∈ωk
w k w_k wk是 I l I_l Il上的第 k k k个局部正方形窗口, I l i I_l^{i} Ili是 w k w_k wk中的第 i i i个像素。
然后通过上采样 A l A_l Al和 b l b_l bl产生 A h A_h Ah和 b h b_h bh。高分辨率输出 O h O_h Oh最后由一个线性的变换模型生成:
O h = A h ∗ I h + b h O_{h}=A_{h} * I_{h}+b_{h} Oh=Ah∗Ih+bh
其中∗是元素级乘法。
Fully Differentiable Guided Filter
原始的引导滤波器只能作为一种后处理操作,它是不可微分的,也不能用fcn进行端到端训练。为了提高fcn的联合上采样能力,我们提出了一种新的构建块,通过将引导滤波器重新构造成一个完全可微的层。这一层被称为引导滤波层,可以从头开始与fcn联合训练,并直接由高分辨率目标监督。引导滤波层的计算图如图2所示。
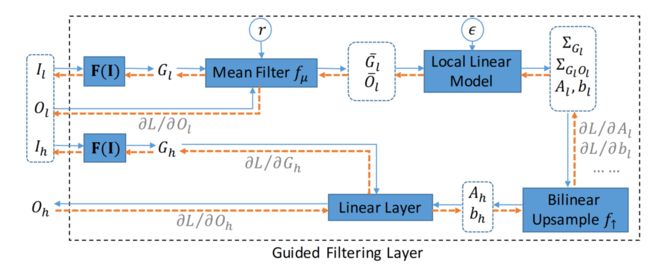
注:引导滤波层的计算图。以低分辨率图像 I l I_l Il、相应的高分辨率图像 I h I_h Ih和低分辨率输出 O l O_l Ol作为输入,产生高分辨率输出 O h O_h Oh。与引导滤波器[25]相比,所提出的层被重新表述为一个完全可微的块,并使用 F ( I ) F(I) F(I)来生成特定于任务的引导图。
引导滤波层的计算图如图2所示。通过应用平均滤波器 f μ f_\mu fμ和局部线性模型于 I l I_l Il和 O l O_l Ol可以得到 A l A_l Al和 b l b_l bl,其中 f μ f_\mu fμ被实现为一个box 过滤器以降低计算复杂度。然后通过双线性上采样 f ↑ f_\uparrow f↑生成 A h A_h Ah和 b h b_h bh。 O h O_h Oh最终由一个以 A h A_h Ah、 b h b_h bh和 I h I_h Ih作为输入的线性层产生。 r r r为 f μ f\mu fμ的半径, ϵ \epsilon ϵ为正则化项,默认情况下设置为1和1e-8。
算法1给出了通过GF层传播梯度的方程。通过将每个算子构造为可微函数, O h O_h Oh的梯度可以通过计算图反向传播到 O l O_l Ol、 I l I_l Il和 I h I_h Ih,使FCNs联合训练和直接引导高分辨率目标。因此,对于GF 层,FCNs可以学习生成一个更合适的 O l O_l Ol来恢复 O h O_h Oh。
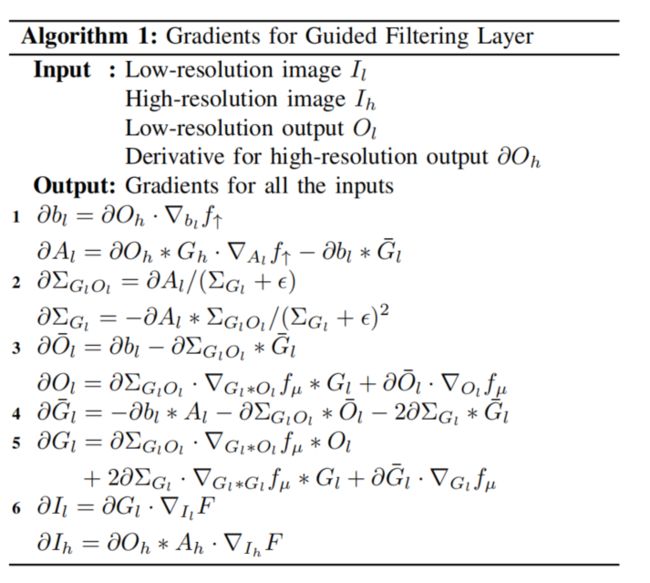
Learn to Generate Task-Specific Guidance Map
在第三节-C中, I l I_l Il、 I h I_h Ih和 O l O_l Ol、 O l O_l Ol假设具有相同数量的通道。当通道大小不同时,需要一个转换函数将 I l I_l Il和 I h I_h Ih转换为与 O l O_l Ol、 O l O_l Ol通道相同数量的引导图。即使通道大小相同,比 I l I_l Il、 I h I_h Ih更好的引导图也是获得更高性能的必要条件。现有的方法通常是为不同的任务手动设计转换函数,需要大量的努力和尝试。与此相反,自从被提出后,引导过滤层是完全可微的,我们可以通过端到端训练自动学习一个转换函数,生成更合适的、特定于任务的指导图。
如图2所示,转换函数 F ( I ) F(I) F(I)将 I l I_l Il、 I h I_h Ih转换为特定于任务的引导图 G l G_l Gl、 G h G_h Gh。 F ( I ) F(I) F(I)是一个由两个卷积层组成的FCN块,其中包括一个自适应归一化层***(adaptive normalization layer)***[23]和一个leaky ReLU 层。两个卷积层的核大小都设置为1×1,第一个卷积层的通道大小默认设置为16。
Convolutional Guided Filtering Layer
除 F ( I ) F(I) F(I)外,所提出的引导滤波层是一个无参数的块,它对所有不同的任务都以相同的方式行为。然而,由于任务之间的巨大差异,一个没有可学习参数的单一引导过滤层不能在各种场景中表现良好。为了解决这个问题,我们通过将非参数操作替换为卷积层,将可学习参数引入引导滤波层。
因此,改进的层,卷积引导滤波层(convolutional guided filtering layer),在处理各种应用时变得更加强大,可以通过端到端训练自适应地适应特定**的任务。卷积引导滤波层的体系结构如图4所示。
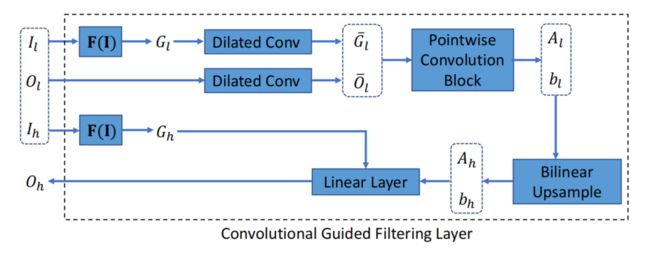
注:图 4.卷积引导滤波层的计算图。引入了扩展卷积和逐点卷积块来代替平均滤波器和局部线性模型。有了可学习的参数,这样的层可以通过端到端训练自适应适应特定的任务。
与图2相比,我们引入了扩展卷积来代替平均滤波器 f μ f_\mu fμ,并且用一个由逐点卷积组成的卷积块来代替一个局部线性模型。对于第三©节中的超参数,去除 ϵ \epsilon ϵ, r r r表示扩张卷积中的膨胀速率。
Deep Guided Filtering Network 深度引导滤波网络
基于所提出的GF层,我们提出了一个像素级图像预测任务的通用框架,即深度引导滤波网络(DGF)。通过以粗到细的方式将所提出的层与FCNs集成,DGF可以生成高分辨率、保留边缘的输出,计算成本和内存使用。DGF的体系结构如图3所示。
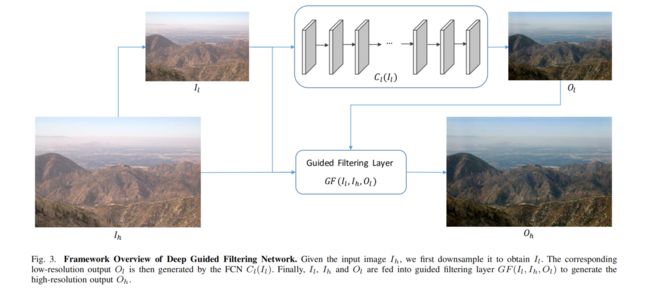
注:图 3.深度引导过滤网络的框架概述。给定输入图像 I h I_h Ih,我们首先对其进行降采样,得到 I l I_l Il。然后由FCN C l ( I L ) C_l(I_L) Cl(IL)生成相应的低分辨率输出 O l O_l Ol。最后,将 I l 、 I h 和 O l I_l、I_h和O_l Il、Ih和Ol入引导滤波层 G F ( I l 、 I h 、 O l ) GF(I_l、I_h、O_l) GF(Il、Ih、Ol),生成高分辨率输出 O h O_h Oh。
首先,我们对原始输入图像 I h I_h Ih进行降采样,以获得低分辨率的输入 I l I_l Il。然后,将FCN C l ( I L ) C_l(I_L) Cl(IL)应用于 I l I_l Il,生成相应的低分辨率输出 O l O_l Ol。最后,利用引导滤波层, I l 、 I h 、 O l I_l、I_h、O_l Il、Ih、Ol为输入,生成高分辨率输出 O h O_h Oh。整个网络都是端到端可训练的,这可以从头开始学习。
Fully Convolutional Network C l C_l Cl( I l I_l Il)
DGF是一个针对像素级图像预测任务的通用框架,它可以显著降低底层算法的计算复杂度和内存使用。具体地说,给定一个特定的像素级图像预测任务,可以设计一个FCN C ( I ) C(I) C(I)来在不考虑速度和内存成本的情况下实现优异的性能。为了获得在速度和内存上的显著优化,我们可以简单地将 C ( I ) C(I) C(I)放到提出的框架DGF中,作为* C l C_l Cl( I l I_l Il*),而无需进行任何其他修改。由于 C ( I ) C(I) C(I)处理低分辨率而不是原始分辨率的输入图像,速度和内存使用可以在很大程度上提高。此外,由于所提出的引导滤波层,我们的系统的性能也可以与之前最先进的滤波层相媲美。这是因为所提出的引导滤波层显著提高了fcn在联合上采样任务中的能力。
Guided Filtering Layer
本文DGF根据引导滤波层的不同配置,总共有四种变体。
- D G F s DGF_s DGFs:使用原始的引导滤波器[25]作为后处理操作,无需经过任何训练。 C l C_l Cl( I l I_l Il)插入 D G F s DGF_s DGFs之前,用低分辨率的输入/输出对进行训练。
- D G F b DGF_b DGFb:在 D G F b DGF_b DGFb中采用了图2中的引导过滤层。当输入和输出具有相同数量的通道时, F ( I ) F(I) F(I)是一个恒等函数。当通道大小不同时, F ( I ) F(I) F(I)通过沿通道轴进行平均,将输入转换为灰色图像。 C l C_l Cl( I l I_l Il)和引导滤波层直接在高分辨率目标的监督下从头开始联合训练。
- D G F b c DGF_b^c DGFbc:与 D G F b DGF_b DGFb相比,图4中的引导滤波层被卷积引导滤波层所取代。
- D G F c DGF^c DGFc:与 D G F b c DGF_b^c DGFbc相比,引入了III-D节提出的 F ( I ) F(I) F(I),它可以在无需手动设计的情况下学习生成面向任务的指导图***(task-oriented guidance maps)***。因此, D G F c DGF^c DGFc不仅可以端到端训练,而且可以通过调整可训练的卷积权值和可学习的 F ( I ) F(I) F(I)来更好地适应不同的任务。
Objective Function
DGF在直接在高分辨率目标的监督下进行端到端训练。具体地说,给定高分辨率输出 O h O_h Oh和相应的目标 T h T_h Th,目标函数被定义为 L ( O h , T h ) L(O_h,T_h) L(Oh,Th)。具体公式因任务而异。通常,训练 C ( I ) C(I) C(I)的目标函数可以直接用于训练DGF,而不进行任何调整。
图像处理任务的实验
为了证明我们的方法的有效性,我们使用DGF clone(模拟)了5个广泛使用的图像处理操作算子。具体地说,首先通过对输入图像应用 L 0 L_0 L0平滑算子[7]、细节操作算子3]、风格转移算子[11]、非局部除模糊算子[4]和图像修饰算子[2]来生成GT。然后,利用输入/GT对,以有监督的方式训练DGF,克隆相应的图像处理算子。
Details of Five Image Processing Operators
- L 0 L_0 L0平滑: L 0 L_0 L0平滑[7]可以有效地锐化主要边缘,同时通过使用 L 0 L_0 L0梯度最小化来消除小边缘。为了生成GT,我们使用具有默认参数的官方实现。
- 细节处理:多尺度细节算子[3]通过增强多个尺度的特征来增强图像。具体地说,首先给定输入图像构造CIELAB亮度通道的三级分解(*(coarse base level )*b和两个细节level d1、d2)。结果图像然后通过b、d1和d2的非线性组合得到。为了生成GT,我们首先使用官方实现和默认参数2生成粗尺度、中等尺度和细尺度图像。最后,通过对三幅图像进行平均,得到最终的输出
- 风格转换:摄影风格转换[11]旨在将参考图像的摄影风格转换到输入图像中。为了生成GT,我们使用了具有默认设置和默认参考图像3的官方实现。生成的输出为灰色图像,并转换为RGB图像作为GT。
- 非局部去雾:非局部去雾[4]在使用非局部去除之前,以消除对输入图像中的大气吸收和散射的影响。我们使用具有默认参数的官方实现来生成GT
- 图像修饰:图像修饰旨在通过全局色调调整自动提高输入图像的美学质量。 人类专家 Human experts被用来生成GT。
Details of DGF
我们对所有五个图像处理操作符使用上下文聚合网络(CAN)[23]作为 C l ( I l ) C_l(I_l) Cl(Il)。 C l ( I l ) C_l(I_l) Cl(Il)和 F ( I ) F(I) F(I)的详细体系结构如表I所示。

注: 表一,用于克隆图像处理操作符的 C l ( I l ) C_l(I_l) Cl(Il)和 F ( I ) F(I) F(I)的体系结构。Leaky relu的负斜率设为0.2。
Adapt-Norm代表了Chen等人提出的自适应归一化。[23]。采用Leaky ReLU作为非线性,其负斜率设置为0.2。对于目标函数,我们按照之前的工作[22],[23]的约定,使用 L 2 L_2 L2损失。
Experimental Setup
我们的实验是在MIT-Adobe FiveK数据集[2]上进行的,该数据集包含2500/2500张高分辨率照片作为训练/测试图像。在数据集中,每张照片包含来自5位专家的5个注释,可以作为图像修饰的GT。我们使用来自专家A的注释,而不是所有五个注释作为GT。
| 训练参数(Adam) | MIT-Adobe FiveK |
|---|---|
| momentum | \ |
| weight decay | 1 0 − 4 10^{-4} 10−4 |
| batch size | 1 |
| poly γ = γ 0 × ( 1 − N iter N total ) p , \gamma=\gamma_{0} \times\left(1-\frac{N_{\text {iter }}}{N_{\text {total }}}\right)^{p}, γ=γ0×(1−Ntotal Niter )p, | p = 0.9 , γ 0 = 1 × 1 0 − 2 p=0.9, \gamma_0=1\times10^{-2} p=0.9,γ0=1×10−2 |
| iteration | 150–>30 |
对于其他四个图像处理算子,地面真实图像按照V-A节中的说明生成。至于训练,我们首先对网络进行150次周期的训练,输入/目标图像的大小调整为512(表示图像的短边被调整为x的大小,而不改变长宽比。)。为了提高泛化能力,我们进一步训练了网络30个时代,训练数据随机调整到512~1672之间的特定分辨率。对于Il,无论 I H I_H IH的分辨率如何,空间分辨率均为64。
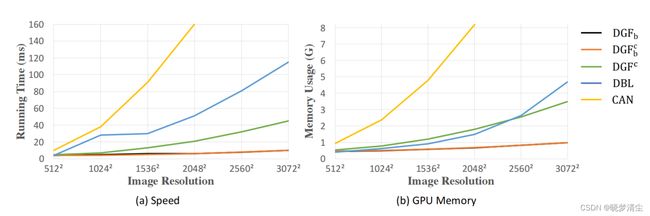
我们的主要baseline是 Deep Bilateral Learning(DBL)[22],它拥有与我们的相似的架构,并在质量和速度之间实现了很好的权衡。另一个强大的baseline是CAN[23],它在运行速度相当快的同时实现了最先进的性能。为了确保公平的比较,我们使用这两种方法的官方实现和训练程序来训练模型。
Experimental Results
1) 运行时间和内存使用情况
| 运行环境 | ||
| CPU | Intel E5-2650 2.20GHz | |
| GPU | Nvidia Titan X (Pascal) | |
| 内存 |
在GPU设备上, D G F b DGF_b DGFb和 D G F b c DGF_b^c DGFbc都需要小于10ms来处理一个分辨率从512×512到3072×3072。由于使用了 F ( I ) F(I) F(I), D G F c DGF_c DGFc的速度略慢,但它仍然在分辨率为3072×3072的图像上实时运行。在所有分辨率中,我们的方法的三种变体都比CAN和DBL快得多。具体来说, D G F b DGF_b DGFb、 D G F b c DGF_b^c DGFbc和 D G F c DGF_c DGFc对2048×2048的一幅图像分别需要6ms、6ms和21ms。CAN则需要160ms,比我们的方法慢超过25×,25×和7×。DBL在相同的设置下需要51ms,比CAN稍快,但比 D G F b DGF_b DGFb和 D G F b c DGF_b^c DGFbc慢8×以上。随着分辨率的增长,我们的方法在速度上的优势甚至更加显著。
对于 h × w × n I 的 I h h\times w\times n_I 的I_h h×w×nI的Ih和 h × w × n O 的 O h h\times w \times n_O的O_h h×w×nO的Oh, D G F b DGF_b DGFb、 D G F b c DGF_b^c DGFbc、 D G F c DGF_c DGFc和 D B L DBL DBL的理论计算复杂性分别为 O ( h × w × n O ) 、 O ( h × w × n O ) 、 O ( h × w × ( n I + n O ) 、 O ( h × w × n O × n I ) \mathcal{O}(h\times w \times n_O)、\mathcal{O}(h\times w \times n_O)、\mathcal{O}(h\times w \times (n_I+n_O)、\mathcal{O}(h\times w \times n_O \times n_I) O(h×w×nO)、O(h×w×nO)、O(h×w×(nI+nO)、O(h×w×nO×nI)
在内存使用方面,我们的方法比两种基线方法占用的GPU内存空间更少。CAN是内存效率最低的方法,它需要近10G GPU内存来处理分辨率为2048×2048的图像。 D G F c DGF_c DGFc占用的内存空间与DBL相似,但随着分辨率的增加而增长较慢。 D G F b DGF_b DGFb和 D G F b c DGF_b^c DGFbc是内存效率最高的方法,即使在分辨率为3072×3072的图像上,它需要的内存也少于1G内存。
2) 定量和定性比较:在MIT Adobe FiveK数据集的测试集上对每种方法的性能进行评估,输入/目标图像的大小调整为1024 × 1024。MSE、PSNR和SSIM作为评估指标。如表二所示,我们的方法在风格转换、非局部去雾和图像修饰方面取得了最先进的性能;同时在L0平滑和多尺度细节操作方面获得了类似的结果。具体而言, D G F c DGF_c DGFc在PSNR中达到26.17dB,比CAN和DBL分别提高了4.86dB和2.85dB。与DBL相比,我们的方法在所有三个指标上的所有五个任务上都大大优于它。定性结果如图8所示。

- 引导滤波层的作用
为了显示卷积引导滤波层和 F ( I ) F(I) F(I)的影响,我们替换了 O l O_l Ol用低分辨率的GT来生成 O h O_h Oh。所得结果代表了每个DGF变体的性能上界。如表三所示,通过将引导滤波层重新构造为可学习的卷积层, D G F b c DGF_b^c DGFbc在所有五个任务中都优于 D G F b DGF_b DGFb。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RY05i7yl-1636274507806)(https://raw.githubusercontent.com/Quincy756/picutres/main/img/papers/DGF/image-20211106183938553.png)]通过进一步将 F ( I ) F(I) F(I)引入卷积引导滤波层, D G F c DGF^c DGFc获得了最好的性能。
类似的结果也可以在表II中观察到。
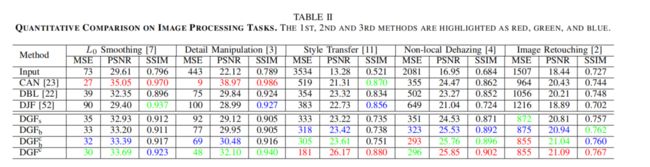
通过联合端到端训练, D G F b DGF_b DGFb在大多数任务上比 D G F s DGF_s DGFs获得更好的性能。具体地说,对于非局部去雾和细节操作, D G F b DGF_b DGFb改进了1dB和0.83dB(PSNR)。通过重新构造为卷积引导滤波层,通过比较 D G F b DGF_b DGFb和 D G F b c DGF_b^c DGFbc,我们可以发现进一步提高了性能。通过添加可学习的 F ( I ) F(I) F(I),我们在几个任务中获得了显著的改进,特别是在依赖于分辨率的任务中。从表二可以看出,在风格转换和细节操作方面, D G F c DGF^c DGFc比 D G F b c DGF_b^c DGFbc使PSNR增加了2.56dB和1.62dB。
DJF[52]是一种最先进的联合上采样方法。为了验证我们的方法的有效性,我们将DJF替换为DGF中的引导滤波层。表二的结果显示,我们的方法在所有任务中都优于DJF。此外,我们的方法也比DJF运行得快得多,对于分辨率为1024×1024的图像,它比DJF少9×(5ms v.s 46ms)。
4) Cross Resolution Generalization 交叉分辨率泛化
在主实验中,我们的方法对1024s(表示1024×1024,下同)的图像进行了评估。为了展示DGF对不同分辨率图像处理的泛化能力,将预先训练好的DGF直接用于512s、1024s、1536s和2048s的图像上,无需微调。如图6所示,我们的方法在所有任务的不同分辨率上都同样好。原因是风格转换高度依赖于分辨率。具体地说,给定一个具有固定分辨率的参考图像,对于具有不同分辨率的输入图像,输出的风格是不同的。

5)Ablation Study
在本节中进行了一系列的实验来验证每个超参数在所提出的引导滤波层中的作用。
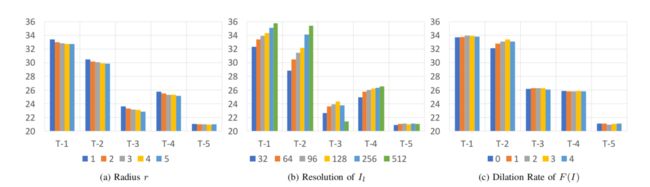
注:消融研究。不同(a)引导滤波层半径r、(b) I l I_l Il的分辨率和©F(I)的扩张卷积率 性能(PSNR)。T-x表示表二中的第x个图像处理任务。
半径r的作用如图7a所示。随着r的增长,性能迅速下降,默认设置(r=1)获得最好的PSNR分数。
I l I_l Il分辨率的效果如图7b所示。对于L0平滑、多尺度细节操作和非局部去雾处理,性能随着 I l I_l Il分辨率的增加而增长。对于风格变换和图像修饰,更高的分辨率并不总是更好的。相应的运行时间和内存使用情况见表4。
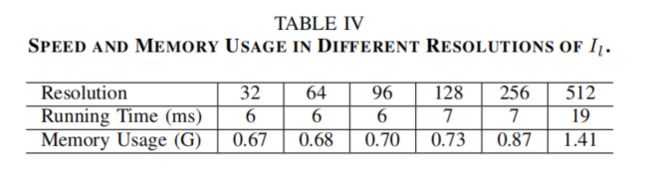
当 I l I_l Il的分辨率为128或256时,我们的方法不仅可以获得优异的性能,而且运行得非常快。
通过改变扩张率,也探讨了 F ( I ) F(I) F(I)的功能。图7c显示,提高扩张率(dilation rate)可以在一定程度上提高性能。
计算机视觉任务的实验
提出的引导滤波层可以显著提高多个图像处理任务的精度、速度和内存使用方面的性能。此外,我们的方法也可以用于替代许多计算机视觉应用中耗时的条件随机场(CRF)。为了评估我们方法的有效性,我们在低视觉到高水平视觉三个计算机视觉任务上进行了实验,即深度估计[19]、显著性目标检测[20]和语义分割[16]。
三个计算机视觉任务的细节
-
深度估计:深度估计由Saxena等人提出。[19],它旨在用单眼线索*(monocular cues)*预测图像的每个像素的深度。对于这项任务,KITTI[53]是使用最广泛的数据集,它包含了来自61个场景的942,382对校正后的立体声对(rectifified stereo pairs )。本文使用了来自官方训练集的29000/1159张图像进行训练和评价,共覆盖33个场景。官方训练集的其余28个场景包含200张高质量的视差图像,本文用于测试。
-
显著性对象检测:显著性对象检测用于检测图像中最显著的对象,并被表示为图像分割问题[20]。在我们的实验中使用了MSRAB[54]和官方的训练/验证/测试分裂[54]。
-
语义分割:语义分割旨在将图像的每个像素分配给预定义的标签[16]之一。为了评估我们的方法,本文使用了PASCAL VOC2012基准[55],其中包括20个前景对象类和一个背景类。原始数据集分别包含1464、1449和1456张像素标记的图像,用于训练、验证和测试。训练集通过额外的注释[56]进一步增强,得到10,582张图像。我们使用10582张增强图像进行训练,并使用1449张验证图像进行测试。
Details of DGF
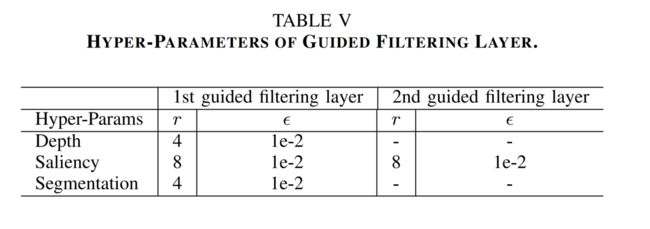
当将DGF应用于计算机视觉任务时,高分辨率的输入图像直接由* C l C_l Cl( I l I_l Il)处理,而不进行降采样,产生低分辨率的输出 O l O_l Ol。对于 C l C_l Cl( I l I_l Il)的体系结构,分别采用MonoDepth7[6]、DSS8[5]、DeepLab-V29[24]进行深度估计、显著性检测和语义分割。相应的训练和测试程序和损失函数也被用于训练我们的网络。对于引导滤波层的超参数,r和 ϵ \epsilon ϵ是通过在验证集上的**网格搜索(grid search)***来确定的,如表v所示。值得注意的是,在显著性检测任务中应用了第二个引导滤波层,以获得更好的性能。
Main Results
我们的方法和基线方法的性能见表六。

对于深度估计, D G F s DGF_s DGFs比基线获得了0.177个rms的改进。通过端到端训练和添加可学习的引导图,我们获得了rms的最佳性能(5.887)。在显著性检测和语义分割方面也得到了类似的结果。将引导滤波层应用于显著性检测, F β F_\beta Fβ从90.61%提高到91.29%。通过用 D G F s DGF_s DGFs取代DGF, F β F_\beta Fβ进一步提高到91.75%。在分割方面,DGF的平均IOU值为73.58%,比基线方法提高了1.79%。
我们还将我们的方法与DenseCRF[57]进行了比较,后者常用于显著性检测和语义分割。实验表明,该方法在显著性检测方面与DenseCRF相当,在语义分割方面具有更好的性能。此外,提出的层的性能至少比DenseCRF快10×。实际上,我们的方法需要34张ms来处理512×512张图像,而DenseCRF需要432张ms。图9显示了我们的方法和基线的可视化结果。用我们的方法得到的结果可以更好地保留边缘和细节。
结论
我们提出了一种新的FCN构建块,即引导滤波层,旨在提高FCNs对联合上采样的能力。通过将引导滤波器构造成一个具有可学习卷积核的完全可微模块,基于FCN的像素级图像预测方法可以从端到端训练中获益,并产生高质量的结果。我们用一个可学习的转换函数进一步扩展了所提出的层,通过生成特定于任务的引导图,使它可以很好地推广到不同的任务中。我们将引导滤波层与fcn集成,并在5个图像处理任务和3个计算机视觉任务上进行评估。实验表明,该层可以在降低10-100×计算成本的情况下达到最先进的性能。我们还进行了一个全面的消融研究,它证明了每个成分和超参数的贡献。
用我们的方法得到的结果可以更好地保留边缘和细节。
结论
我们提出了一种新的FCN构建块,即引导滤波层,旨在提高FCNs对联合上采样的能力。通过将引导滤波器构造成一个具有可学习卷积核的完全可微模块,基于FCN的像素级图像预测方法可以从端到端训练中获益,并产生高质量的结果。我们用一个可学习的转换函数进一步扩展了所提出的层,通过生成特定于任务的引导图,使它可以很好地推广到不同的任务中。我们将引导滤波层与fcn集成,并在5个图像处理任务和3个计算机视觉任务上进行评估。实验表明,该层可以在降低10-100×计算成本的情况下达到最先进的性能。我们还进行了一个全面的消融研究,它证明了每个成分和超参数的贡献。