深度解析Tengine的调试与资源监控方法论
云栖君导读:Tengine是由淘宝网发起的Web服务器项目。它在Nginx的基础上,针对大访问量网站的需求,提供更强大的流量负载均衡能力、全站HTTPS服务、安全防攻击、链路追踪等众多高级特性。团队的核心成员来自于淘宝、搜狗等互联网企业,从2011年12月开始,Tengine成为一个开源项目,团队在积极地开发和维护着它,最终目标是打造一个高效、稳定、安全、易用的Web平台。
阿里云CDN现在服务超过24万家客户,Tengine作为接入层提供高性能Web Server服务,是CDN系统最核心的组件之一。无论是来自阿里集团内部还是外部客户的流量服务,几乎都是由Tengine承载。可以毫不夸张地说,Tengine的服务质量直接影响着国内外无数大中小型Web站点的服务质量和业务存活,所以,维护Tengine的稳定性一直是我们团队的最高优先级目标之一。经过了多年淘宝、天猫等大型网站双十一活动的洗礼,Tengine的性能和稳定性已经得到了很好的验证。
有一句俗语:“上帝说要有光,于是便有了光。“阿里云高级开发工程师墨飏说,“Tengine在做工具化的时候,也基本沿袭了这样的思路。在做开发之前,我们会系统性地思考:我们需要面对什么样的场景,会碰到什么样的问题,需要怎样的调试技巧和工具,是否可以解决更多此类问题,于是,我们的工具便会在这样的思路下逐渐成型和完善。同时,在服务客户的过程中,我们也会遇到各种新场景新问题,为了定位和解决问题,我们也会针对性地提出解决方案,沉淀出更多调试技巧和工具。作为一线开发团队,我们一路走来积累了非常多调试技巧、工具化的经验。”
本文由阿里云CDN团队的研发同学笑臣和墨飏带来,从Tengine的内存调试、核心结构、upstream、coredump四个部分展开,为大家整理和分享一些实践经验。
内存调试——精准定位问题
Tengine作为C语言开发的应用,在内存的使用中会碰到一些问题,第一部分将重点介绍内存调试方面的相关内容。
从下图可以清晰的看出,Tengine内存分布可以从三个维度来理解:底层实现、抽象层、应用层。

一、底层实现
Tengine底层实现依赖操作系统的内存分配机制,常见的内存分配器包括jemalloc(FreeBSD)、ptmalloc(glic)、tcmalloc(Google),luajit则使用内置的dlmalloc库。Tengine在每个连接accept后会malloc一块内存,作为整个连接生命周期内的内存池, 当HTTP请求到达的时候,又会malloc一块当前请求阶段的内存池, 因此对malloc的分配速度有一定的依赖关系。jemalloc的性能是ptmalloc的两倍以上,我们在使用Tengine的时候默认采用jemalloc。jemalloc在追踪实际内存分配时可以使用“malloc_stats_print”来查看内部细节,帮助定位内存泄露等问题。

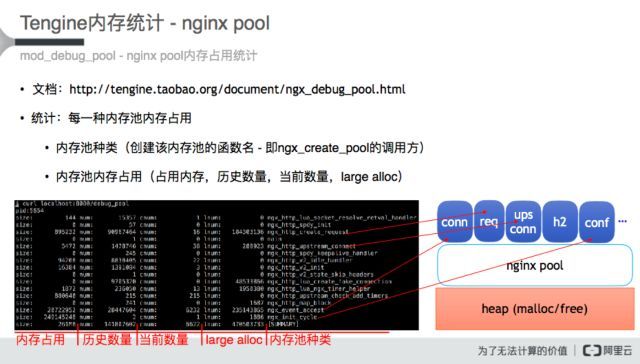
二、nginx pool调试
在底层内存分配工具无法定位问题时,我们需要从抽象层分析出了什么问题。
Tengine作为nginx 的fork,在使用nginx pool方面与官方nginx基本没什么区别,它的内存池管理机制在HTTP请求的任一阶段都可能被调用来分配内存,我们可以从内存分配的真实函数调用来统计内存分配的占用量、历史数量、当前数量、large alloc等。mod_debug_pool已经在Tengine社区开源,有兴趣可以自行查阅文档,它的原理是通过hook ngx_create_pool函数来记录__func__/__LINE__,在需要排查问题时可以展示历史数据,从抽象层定位内存泄露等问题。
三、lua内存统计
lua/luajit是另一个非常成熟的开源项目,在nginx生态系统中,lua-nginx-module允许lua/luajit以虚拟机形式内嵌到nginx提供强大的脚本能力,我们在阿里云CDN海量业务开发中大量使用到lua/luajit。在调试luajit内存占用时,可以通过collectgarbage来展示总内存占用量,通过扫描gc object,可以统计global_State中所有gc对象,OpenResty社区也提供了GDB工具来输出gc对象的数量和内存占用。

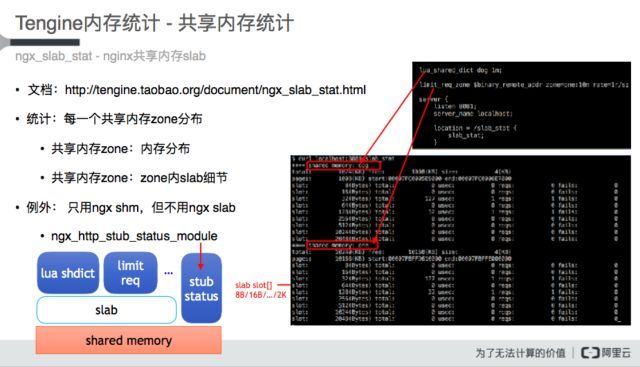
四、共享内存调试
Tengine是多进程服务模型,其进程间的通信主要依赖操作系统共享内存机制,随着业务的发展共享内存的使用频率越来越高,如何去定位、调试共享内存,是一个比较严峻的问题,且业内缺少相关工具。我们在调试共享内存问题时,沉淀和开源了mod_slab_stat工具,在Tengine社区可以查阅详细的文档,该工具统计和展示了每个zone的内存分配细节,包括page、slab和alloc num等,突出业务通信内容块分布情况等。该工具适用于ngx shm,基于ngx slab的stub stats模块是个例外。
以上,从底层实现、抽象层、应用层三个维度,可以定位到绝大部分Tengine系统和业务的内存问题,包括一些内存的调试技巧。
核心结构——调试与解决故障
Tengine作为高性能服务器被广泛应用,它的核心框架和核心数据结构决定了其承载服务的质量。针对所遇到的CDN用户上报故障的工单,比如请求异常、访问慢等,如何从Tengine核心结构去调试、定位和解决问题,是本部分要介绍的内容。
Tengine主要的核心结构包括连接、请求和计时器等。连接承载着请求,以连接池的形式提供前端、后端网络服务,其异步事件驱动的特性是Tengine高性能网络服务的基石,而其事件模型又和计时器紧紧关联,这些核心结构组成了Tengine的核心框架。
要调试和定位Tengine网络问题,需要从连接、请求、计时器等多角度思考,从读写请求状态、解析请求阶段、应答输出阶段、建连等多维度采集,从而得到更详细的全局监控数据。

Tengine在nginx stub status工具基础上,开发了tsar工具(已开源),来展示更细粒度的历史资源监控,包括应用层QPS、HTTPS和网络层的accept、读写等待等。基于reqstatus的域名级监控,可以针对任意粒度域名级来统计请求数、连接数和5xx、4xx等状态码数量,还包括连接的复用情况等。

有了tsar和reqstatus工具,我们可以从全局来分析Tengine系统的服务和性能状态,但是,这够了么?CDN系统中,我们会遇到一些问题,比如:为啥tengine/nginx访问慢?是因为客户端慢、后端慢、还是nginx本身hang住?如何去衡量“慢“?我们需要对请求时间进一步细分。
Tengine新增了
responsefirstbytetime、responsefirstbytetime、upstream_response_time、
writewaittime、writewaittime、upstream_read_wait_time等变量来记录从请求进入到响应结束整个请求流程中的包括不限于应答首字节、后端应答首字节、socket读写等待时间总和等关键指标。

Tengine在衡量和监控请求卡顿时,将events cycle内event平均处理时间和events cycle内timer平均处理时间综合来定位单cycle平均耗时长的异常,常见的问题如同步IO(磁盘负载高时写log卡顿)、CPU密集型执行流(lua实现的CPU密集型逻辑)。
有些时候,我们无法从全局资源监控角度定位问题,这时候可以从ngx_cycles->connections[]来查询当前执行的请求或连接结构信息,通过gdb脚本来扫描worker内当前连接信息,查看和调试是否有请求堆积或连接泄露等问题。mod_debug_conn(待开源)工具是上述调试技巧的沉淀,它还可以帮助我们查看请求/连接的内存占用、分析连接和请求上的各类信息。

同时,Tengine的计时器(timer)在异步业务场景中有重要作用,通过扫描计时器红黑树,分析每个event timer,我们可以调试和定位异步操作中的问题。有时候我们在平滑升级tengine服务时,worker一直处于shutting down状态无法退出,其实便是因为一直存在timer导致的。也可以通过hook ngx.timer.at函数来统计lua-nginx-module中的timer caller次数,解决timer超限的报错等。
回源监控
CDN是内容分发网络的简称,其分发的内容来自用户源站,负责回源的upstream模块是Tengine最重要组成部分之一,使Tengine跨越单机的限制,完成网络数据的接收、处理和转发。这部分主要介绍upsteam的一些调试技巧和回源资源监控的内容,以及相应的实例分享。
在上面的章节中,我们已经分析过如何依靠Tengine提供的关键指标来衡量和监控请求卡顿,那么,我们同样可以提出问题:如何去分析请求代理或回源失败?是因为客户端主动断连、后端异常还是请求超时?如何去分析真实的原因,从而实时监控回源失败,这也是经常困扰CDN用户和开发人员的难题。
从Tengine的请求处理流程分析,客户端在完成TCP三次握手后,比较常见的错误是:1、客户端异常断开连接;2、客户端主动断开连接;3、等待读写客户端超时。在Tengine读取请求内容后,解析客户端请求失败如请求行/请求头等协议出错,在upstream模块回源时,也可能发生连接后端失败、后端异常断开连接、后端主动断开连接、等待读写后端超时、解析后端应答头失败等错误,我们可以从Tengine的错误日志查看对应的报错信息,在此基础上,我们从ngx_http_upstream_connect、ngx_http_upstream_send_request、ngx_http_upstream_process_header、ngx_http_upstream_process_body_in_memory等回源关键函数切入,提供error flag来监控真实的客户端/回源失败原因,将错误统计输出至访问日志、reqstatus工具等,关联和分析域名/请求级别的回源失败问题,保障CDN服务的稳定性。

现在,我们有了回源的关键指标变量和error flag,可以依靠一些调试技巧来分享一个upstream问题实例。如图所示,当客户端请求通过Tengine upstream回源时,我们可能碰到这样的问题:

读源站,读满buffer
发送buffer size数据给客户端,全发完了
循环上述两步骤…
继续读源站,读出若干数据,且源站已读完
发送部分给客户端,未发完(客户端卡或者其他原因)
再次读upstream,读出again(显然,因为之前源站数据读完了)
继续发送数据给客户端,未发完(客户端卡或者其他原因)
upstream回源先超时了,这个时候$error_flag表明等待读源站超时,但是事实是这样吗?
我们提供了完整的复现方法,如图所示:

站在上帝视角,很明显可以看到其实是客户端问题,但是回源采集的关键指标:errorflag、errorflag、upstream_read_wait_time、$write_wait_time,却告诉我们是源站出错导致的问题,数据不会欺骗我们,那么问题到底在哪里?
上述调试的一些技巧和回源监控,帮助我们理解upstream模块的原理:
1、upstream有2个计时器,前端的和后端的;
2、Tengine/Nginx即使写客户端写不进去,只要proxy buf没满也会尝试读后端,如果后端数据读完了,会读出EAGAIN;
3、后端计时器较短先超时了,关闭请求,此时往往认为后端出错,真实情况是客户端出错;

这个特殊实例,在某些场景下,甚至在很多的生成环境中,都是比较常见但却往往被忽视的问题,在帮助提升用户体验和服务质量的目标下,即使是nginx核心代码不易发现的bug,在完善的调试工具和回源监控下,一样无所遁形。有兴趣的同学可以搜索nginx邮件列表来详细了解问题背景,虽然nginx 官方因为一些原因没有合入该patch,我们在Tengine中也做了单独的优化策略。
Coredump
coredump是Tengine这类C开发的应用程序比较常见的问题,随着业务的迅猛发展,coredump往往会变得越来越大,甚至越来越频繁,我们从空间、数量、自动分析等角度层层递进来优化Tengine的coredump。
“cat /proc/PID/coredump_filter”这行指令帮助我们了解Linux操作系统coredump机制所支持的内存形态,包括私有内存、共享内存等。我们在使用Tengine时可以去除共享内存,降低coredump文件大小。同时,也可以限制一定时间内crash写coredump文件的次数,防止磁盘IO过高或磁盘空间被占满,Tengine提供了“worker_core_limit”指令(待开源)来限制至分钟/小时/天级别。

现在我们已经从空间和数量角度优化了coredump,方便了调试。那么是否可以自动化完成分析,提升定位问题的速度?答案是肯定的。
我们通过gdb python脚本来自动分析coredump文件,从中提取得到触发问题的请求的host、URL、headers等,有了这些信息,就可以不断复现来快速调试和定位问题。但是有时候,coredump栈并不能告诉我们完整的现场,而在crash时,Tengine丢失了日志中的请求信息,我们将这些信息记录在环形内存中,通过coredump文件将环形缓冲数据输出到文件,环环相扣,完整的现场,真相只有一个。

原理:
http://nginx.org/en/docs/ngx_core_module.html#error_log
事后诸葛只能查漏补缺,我们需要提前发现问题,实时流量拷贝工具应运而生。http_copy是Tengine的扩展模块,可以实时放大转发本机的流量(HTTP请求),可以配置放大流量到指定地址和端口,也可设置放大的倍数和并发量等,更可以通过源站健康检查来自动关停流量,避免过大流量对Tengine和源站的正常服务造成影响。

在流量压测/流量拷贝时,不需要真实返回响应的内容,减少带宽消耗,drop_traffic工具添加body filter直接丢弃数据,或者截获c->send_chain/c->send函数直接丢弃数据,在调试时发现问题而不产生问题。
以上就是阿里云CDN团队对于Tengine的内存调试与资源监控方面的一些实践经验,希望对于正在使用开源Tengine的同学有一些帮助。

end
阿里90后工程师利用ARM硬件特性开启安卓8终端“上帝模式”
HBase从入门到精通系列:误删数据如何抢救?
阿里大咖带你了解技术团队效能动力模型
深度学习12大常见问题解答(附答案)
DRDS 柔性事务漫谈
更多精彩