Python机器学习手册(六)
非结构化文本数据(比如,一本书或一条推文的内容)是处理起来最有意思也是最难的特征之一
6.1 清洗文本
对一些非结构化的文本数据进行基本的清洗
大部分基本的文本清洗操作用python的常用字符串操作即可完成。其中strip、replace、split这三个操作用的最多
#创建文本
text_data = [" Interrobang. By Aishwarya Henriette ","Parking And Going. By Karl Gautier"," Today Is The night. By Jarek Prkash"]
#去除文本两端的空格
strip_whitespace = [string.strip() for string in text_data]
#查看文本
strip_whitespace

#删除句号
remove_periods = [string.replace(".","") for string in strip_whitespace]
#查看文本
remove_periods

# 也可以创建并应用自定义的转换函数
#创建函数
def capitalizer(string:str)->str:
return string.upper()
#应用函数
[capitalizer(string) for string in remove_periods]

# 还可以使用正则表达式来做一些复杂的字符串操作
#加载库
import re
#创建函数
def replace_letters_with_X(string:str) ->str:
return re.sub(r"[a-zA-Z]","X",string)
#应用函数
[replace_letters_with_X(string) for string in remove_periods]

6.2 解析并清洗HTML
提取HTML文件中的文本数据,仅提取某段文本
Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库
#加载库
from bs4 import BeautifulSoup
#创建一些HTML代码
html="""Masego Azra"""
#解析HTML
soup=BeautifulSoup(html,"lxml")
#查找class是“full_name”的div标签,并查看文本
soup.find("div",{"class":"full_name"}).text

6.3 移除标点
移除文本数据的特征中的标点
定义一个函数,将一个标点字典作为参数传入translate
将Unicode中的标点字符作为key,None作为value,然后将字符串中所有在punctuation字典中出现过的字符转换成None,近而高效的移除它们
#加载库
import unicodedata
import sys
#创建文本
text_data = ['Hi!!! I. Love.This. Song....','10000% Agree!!!! #LoveIT','Right?!?!']
#创建一个标点字典
punctuation = dict.fromkeys(i for i in range(sys.maxunicode)
if unicodedata.category(chr(i)).startswith('P'))
#移除每个字符串中的标点
[string.translate(punctuation) for string in text_data]
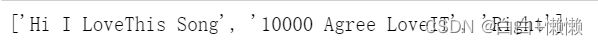
6.4 文本分词
将文本分离成独立的单词
python的自然语言工具集(Natural Language Toolkit;NLTK)在处理文本方面有很多功能强大的操作,其中包括文本分词(word tokenizing)
#加载库
from nltk.tokenize import word_tokenize
#创建文本
string = "The science of today is the technology of tomorrow"
#分词
word_tokenize(string)

#将文本切分成为句子
#加载库
from nltk.tokenize import sent_tokenize
#创建文本
string = "The science of today is the technology of tomorrow. Tomorrow is today."
#切分成句子
sent_tokenize(string) #发现一个小bug,只有句号+空格才能切分成句子。

文本分词,尤其使将文本分为独立的单词是在清洗文本数据之后的常见任务。
因为他是将文本转换成能用于构建有效特征的数据的第一步。
6.5 删除停用词(stop word)
给定一组分好词的文本数据,删除其中非常常见但包含的信息又很少的单词
#使用NLTK的stopword
#加载库
from nltk.corpus import stopwords
#如果是第一次使用停用词表,需要先进行下载
import nltk
nltk.download('stopwords')
#创建单词序列
tokenized_words = ['i','am','going','to','go','to','the','store','and','park']
#加载停用词
stop_words = stopwords.words('english')
#删除停用词
[word for word in tokenized_words if word not in stop_words]

尽管“停用词”可以指代所有需要在数据预处理阶段删除的单词,但是这个属于常常用来指代那些特备常见而包含的信息又很少的单词。
NLTK有一个常见停用词列表,可用于查找并删除单词序列中的停用词。
值得注意的是:NLTK的stopwords假设所有的单词但是小写形式。
#查看停用词
stop_words[:5]

6.6 提取词干
将一个单词序列中的单词转换成它们的词干
# 使用NLTK的PorterStemmer
#加载库
from nltk.stem.porter import PorterStemmer
#创建单词序列
tokenized_words = ['i','am','hnmbled','by','this','traditional','meeting']
#创建词干转换器
porter = PorterStemmer()
#应用词干转换器
[porter.stem(word) for word in tokenized_words]

词干提取(stemming)能识别出一个单词的词缀并将其删除(例如,动名词中的“ing”后缀),同时保留其词根的意思,以此得到这个词的词干。
例如,“tradition”和“traditional”的词干都是“tradit” ,表明虽然它们是不同的单词,但基本意思是相同的。提取文本的词干后,单词的可读性会变差,不过更接近它的基本意思,因此更适合用来作比较。
NLTK的PorterStemmer实现了被广泛使用的波特词干(porter stemming)算法,移除或替换单词中常用的后缀来生成词干。
6.7 标注词性
为文本数据中的每个单词或字符标注词性
# 使用NLTK与训练的词性标注器
#加载库
from nltk import pos_tag
from nltk import word_tokenize
#创建文本
text_data = "Chris loved outdoor running"
#使用预训练的词性标注器
text_tagged = pos_tag(word_tokenize(text_data))
#查看词性
text_tagged

NNP:单数专有名词
VBD:过去式的动词
VBG:动名词或动词的现在分词形式
为文本添加了词性标注,就可以一句标签找到特定词性的单词。例如,找到所有的名词;
#过滤单词
[word for word, tag in text_tagged if tag in['NN','NNS','NNP','NNPS']]

现实中可能遇到的情况是,有一份数据,其中每个观察值都包含一条推文,
我们将这些句子转换成用词性表示的特征(例如:如果是专有名词,特征就是1,否则为0)
#加载库
from sklearn.preprocessing import MultiLabelBinarizer
#创建文本
tweets = ["I am eating a burrito for breakfast","Political science is an amazing filed","San Francisco is an awesome city"]
#创建列表
tagged_tweets= []
#为每条推文中的每个单词加标签
for tweet in tweets:
tweet_tag = nltk.pos_tag(word_tokenize(tweet))
tagged_tweets.append([tag for word,tag in tweet_tag])
#使用ont-hot编码将标签转换成特征
one_hot_multi = MultiLabelBinarizer()
one_hot_multi.fit_transform(tagged_tweets)

使用classes_就能发现每个特征都是一个词性标注
#查看特征名
one_hot_multi.classes_

文本是英文的,而且不是关于某个特定主题的(例如医学),词性标注最简单的做法就是使用NLTK预训练的词性标注器。
如果pos_tag不是很准确,NLTK也提供了自行训练标注器的机制,词性标注器的主要缺点就是需要一个很大的文本语料库,并且其中每个单词的词性标签都是已知的,构建这样的语料库是一种繁琐的工作。
自行训练语料库可以参考下列的做法:
使用的语料库是Brown Copus(布朗语料库),他是最流行的带标签的文本语料库之一。使用回退n元模型(back n-gram)标注器,n表示在预测一个单词的词性时需要考虑多少个前面的单词(其实是n-1个)。首先,考虑这个单词的前两个单词(使用TrigramTagger),如果它前面没有这两个单词则回退到只考虑这个单词的前面一个单词,这时候使用BigramTagger。如果这个单词前面一个单词也没有,就通过UnigramTagger只考虑这个单词本身。为了监测标注器的准确率,将文本分成训练标注器、测试标注器。
#加载库
from nltk.corpus import brown
from nltk.tag import UnigramTagger
from nltk.tag import BigramTagger
from nltk.tag import TrigramTagger
#从布朗语料库中获取文本数据,切分成句子
sentences = brown.tagged_sents(categories='news')
#将4000个句子用作训练,623个句子用作测试
train = sentences[:4000]
test = sentences[4000:]
#创建回退标注器
unigram = UnigramTagger(train)
bigram = BigramTagger(train,backoff=unigram)
trigram = TrigramTagger(train,backoff=bigram)
#查看准确率
trigram.evaluate(test)

6.8 讲文本编码成词袋
创建一组特征来标识观察值文本中包含的特定单词的数量
# 使用scikit-learn的CountVectorizer
#加载库
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
#创建文本
text_data = np.array(['I love Brazil Brazil','Sweden is best','Germany beats both'])
#创建一个词袋特征矩阵
count = CountVectorizer()
bag_of_words = count.fit_transform(text_data)
#查看特征矩阵
bag_of_words

输出的是一个稀疏矩阵。当文本量很大时,使用这样的存储方式是由必要的,但是在我们的玩具例子中,可以使用toarray查看每个观察值的词频统计矩阵:
bag_of_words.toarray()

使用get_feature_names方法能查看每个特征所对应的单词
count.get_feature_names()

将文本转换成特征的最常用的方法之一就是使用词袋模型(big-of-words model)。词袋模型为文本数据中的每一个单词都输出一个特征,每个特征都包含该单词在观察值中出现的次数。
极大多数的单词的次数为一,因此词袋模型输出的是一个稀疏矩阵,CountVectorizer默认以稀疏矩阵作为输出,节约空间。
CountVectorizer有很多有用的参数,默认情况下每个特征是一个单词,也可以选取两个单词、三个单词等等。将特征设置成两个词(称为二元模型,2-gram),三个词(三元模型,3-gram)的组合。ngram_range为我们的n元模型设置最大元和最小元,例如(2,3)会返回所有的二元模型和三元模型。其次,使用stop_words可以很方便的移除信息量比较少的单词,停止此列表可以是函数自带的也可以是自定义的。最后,使用vocabulary可以将观察值限定为仅在特定的单词表中出现的单词或短语。例如,创建一个只包含国家名字的词袋特征矩阵。
#用特定参数创建特征矩阵
count_2gram = CountVectorizer(ngram_range=(1,2),stop_words="english",vocabulary=['brazil'])
bag = count_2gram.fit_transform(text_data)
#查看特征矩阵
bag.toarray()

#查看一元模型和二元模型
count_2gram.vocabulary_

6.9 按单词的重要性加权
对词袋模型中的词按照其在观察值中的重要程度进行加权
TF-IDF将一个词在某个文档(推文、影评、演讲稿等)中的出现次数和这个词在所有文档中出现次数进行对比。用scikit-learn的TfidfVectorizer能方便的做对比
#加载库
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
#创建文本
text_data = np.array(['I love Brazil. Brazil!','Sweden is best','Germany beats both'])
#创建TF-IDF特征矩阵
tfidf = TfidfVectorizer()
feature_matrix = tfidf.fit_transform(text_data)
#查看TF-IDF特征矩阵
feature_matrix

TfidfVectorizer输出的也是一个稀疏矩阵,想看稠密矩阵形式的输出,可以使用.toarray
#查看TF-IDF特征矩阵的稠密形式
feature_matrix.toarray()

vocabulary_可以查看特征callable单词表
tfidf.vocabulary_

一个词在文档中出现的次数越多,他对这个文档就越重要。例如,如果单词economy在某篇文档中频繁出现,就表示这个文档可能是关于经济的。我们把单词在文档中的出现次数称为词频(term frequency,tf)
一个单词出现在了多少文档中,我们把这个数值称为文档频率(document frequency,df)
单词在文档中的重要程度:将tf和idf(inverse of document frequency,逆文档频率)相乘:
tf-idf(t,d) = tf(t,d)*idf(t)
t表示单词,d表示文档。计算tf和idf的方法有很多。在scikit-learn中,就是单词在文档中出现的次数,idf是这样计算出来的:
idf(t) = log(1+nd/1+df(d,t))+1
nd是文档的数量,df(d,t)是单词t的文档频率(单词在多少份文档中出现过)
scikit-learn会使用欧式范数(L2范数)将TF-IDF向量归一化。得到的结果值越大,这个单词对一个文档来说就越重要。